

Chatbots(对话式机器人)往往具有高度专业性,只要回答与用户的期望相差不远,它们的性能就值得肯定。为了更好地处理不同的对话主题,开放域对话研究探索了一种新的方法,研究人员试图开发一种非聊天专用机器人,虽然不以聊天为主要功能,但仍然可以满足用户的任何对话需求。
谷歌的研究人员认为:开放域对话研究除了是一个引人入胜的研究课题之外,这种对话机制还可以产生许多有趣的应用程序,例如进一步人性化的计算机交互、改进外语练习以及制作可关联的交互式电影和游戏角色。
但是,当前的开放域聊天机器人有一个严重的缺陷:它们通常没有实用意义,比如对同一个问题的回答前后不一致,或者回答总是缺乏基本常识。此外,聊天机器人通常会给出并非特定于当前上下文的响应,例如,“我不知道”可以是对任何问题的回答,当前的聊天机器人比人类更经常这样做,因为它涵盖了许多可能的用户输入。
近日,在一篇名为《Towards a Human-like Open-Domain Chatbot》的论文中,谷歌的研究人员介绍了一个名为“Meena”的模型,它是一个包含了 26 亿参数的端到端训练型神经对话模型。
在论文中,研究人员表示:他们已经证明,与现有的最新聊天机器人相比,Meena 可以进行更聪明、更具体的对话。他们针对开放域聊天机器人提出了一项新的人类评估指标,即敏感度和特异性平均值(SSA),该指标捕获了人类对话的基本但重要的属性。值得注意的是,研究人员证明了“困惑度”是一种易用于任何神经对话模型的自动指标,与 SSA 高度相关。
什么是“Meena”
Meena 是一种端到端的神经对话模型,可以学会对给定的对话环境做出更加聪明的反应。据介绍,Meena 模型具有 26 亿个参数,并经过 341 GB 的文本训练,这些文本是从公共领域的社交媒体对话中过滤出来的,与现有的最新生成模型 OpenAI GPT-2 相比,Meena 具有 1.7 倍的模型容量,并且受过 8.5 倍的数据训练。
该模型训练的目标是最大程度地减少“困惑度”,即预测下一个标记(会话中的下一个单词)的不确定性。它的核心是Evolved Transformer seq2seq体系结构,这是一种通过进化神经体系结构搜索发现以改善困惑性的 Transformer 体系结构。
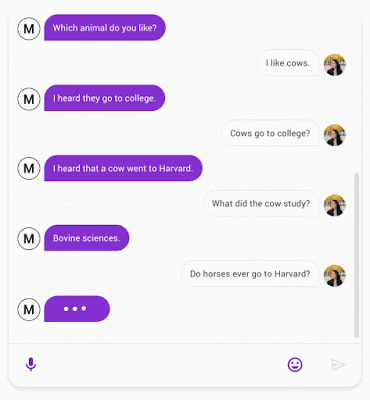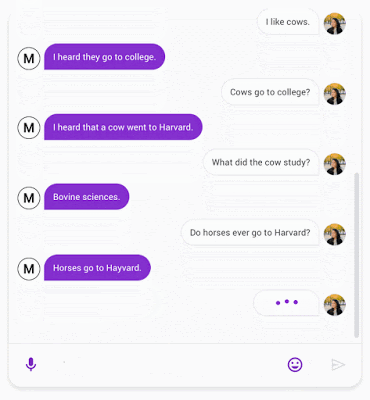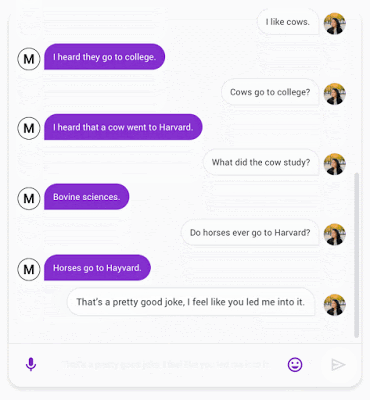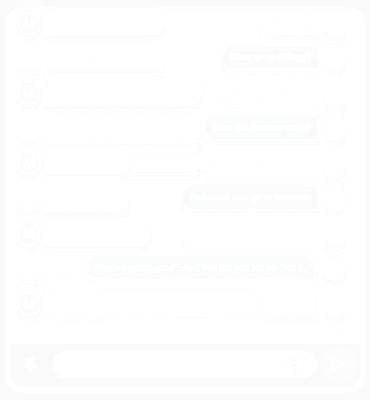
Meena(左)与人类的对话
具体而言,Meena 具有单个 Evolved Transformer 编码器块和 13 个 Evolved Transformer 解码器块,如下所示。编码器负责处理对话上下文,以帮助 Meena 理解对话中已经说过的内容,然后,解码器使用该信息来制定响应。通过调整超参数,研究人员发现:功能更强大的解码器是提高对话质量的关键。
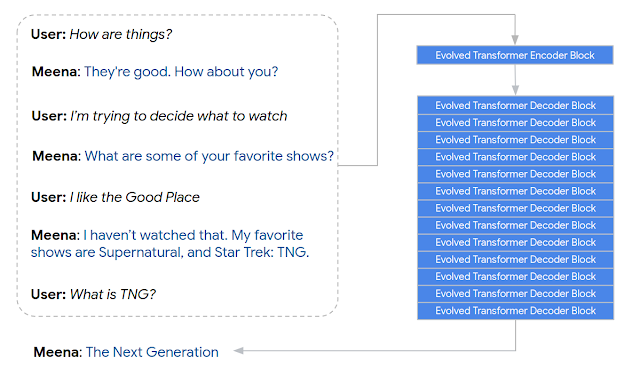
用于训练的对话被组织为树线程,其中线程中的每个答复都被视为一个会话回合。研究人员提取了每个会话训练示例(包含七次上下文转换)作为通过树线程的一条路径,研究人员表示,选择七次作为一个良好的平衡,是因为既要有足够长的上下文来训练会话模型,又要在内存约束内拟合模型(较长的上下文会占用更多的内存)。
敏感性和特异性平均值(SSA)
现有的关于聊天机器人质量的人工评估指标往往很复杂,并且未在审阅者之间达成一致。这促使谷歌的研发人员设计了一种新的人类评估指标,即敏感度和特异度平均值(SSA),它捕获了自然对话的基本但重要的属性。
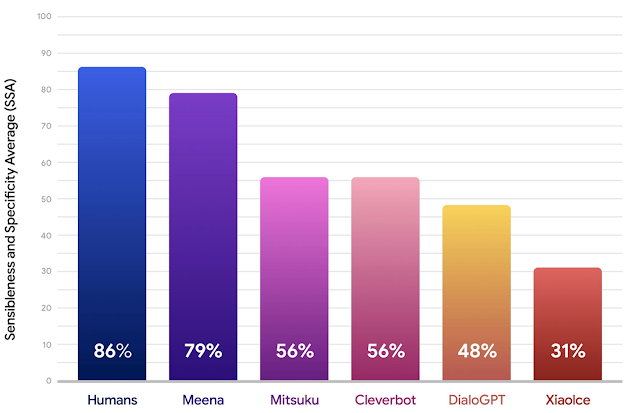
为了计算 SSA,研究人员与参与测试的聊天机器人(Meena 和其他知名的开放域聊天机器人共同参与测试,包括 Mitsuku,Cleverbot,小冰和 DialoGPT)进行了自由形式的对话众包。
为了确保评估之间的一致性,每个对话都以相同的问候语“ 嗨!”开始,人类评估员会在对话过程中重点关注两个问题:“回答是否有意义”以及“回答是否具体”,每轮对话都要求评估者使用常识来判断机器人的响应是否完全合理。如果出现任何问题,比如混淆,不合逻辑,脱离上下文或有事实性错误的,则应将其评定为“没有意义”;如果响应是有意义的,则需要评估其回答以确定是否基于给定的上下文。
例如,如果 A 回答“ 我爱网球 ”,而 B 回答“ 很好 ”,那么这段对话应标记为“不具体”,因为这样的答复可以在许多不同的上下文中使用;但是如果 B 回应:“我也是,我太喜欢罗杰·费德勒了!”那么就可以将其标记为“特定”,因为它的回答与前文所讨论的内容密切相关。
对于每个聊天机器人,研究人员通过大约 100 个对话收集了 1600 至 2400 种个人对话,每个模型响应都由评估人员标记,以表明其回答是否合理和具体。聊天机器人的敏感度是标记为“敏感”的响应的一部分,而特异性是标记为“特定”的响应的一部分,这两个数值的平均值是 SSA 分数。
下面的结果表明,就 SSA 分数而言,Meena 的表现大大优于现有的最新聊天机器人,并且正在缩小与人类的差距。
自动评估度量:困惑度
研究人员长期以来一直在寻求一种与更准确的人工评估相关的自动评估度量,这样做可以更快地开发对话模型,但是迄今为止,找到这样的自动度量标准一直是一个挑战。出乎意料的是,谷歌研究人员发现,在他们的工作中,“困惑度”似乎符合这一种自动度量标准,它可随时用于任何神经 seq2seq 模型,表现出与人工评估(如 SSA 值)的强烈相关性。
谷歌研究人员关于“困惑度”的解释是这样的:困惑度用于衡量语言模型的不确定性,困惑度越低,模型就越有信心生成下一个标记(如字符、子词或单词)。从概念上讲,困惑度表示模型在生成下一个回答时试图选择的选项数量。
在开发过程中,研发人员对具有不同超参数和体系结构的八个不同模型版本进行了基准测试,例如层数、关注头(attention heads)、总训练步骤、是否使用 Evolved Transformer 或常规 Transformer 以及是否使用硬标签或“蒸馏”进行训练。如下图所示,困惑度越低,模型的 SSA 评分越好,相关系数也很强(R 2 = 0.93)。
编者注:知识蒸馏(有时也称为师生学习)是一种压缩技术,要求对小型模型进行训练,以使其拥有类似于大型模型(或者模型集合)的行为特征。
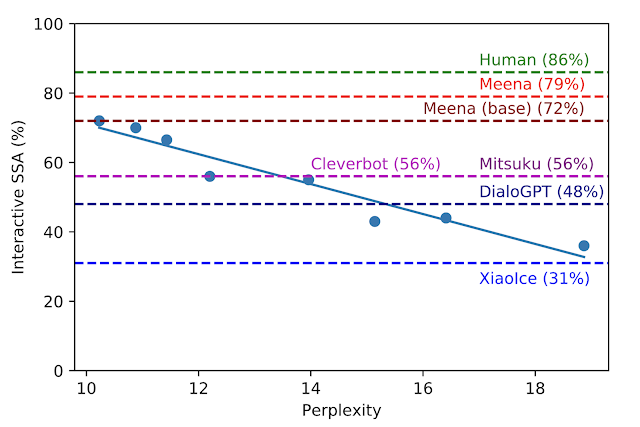
交互式 SSA 与困惑度。每个蓝点都是 Meena 模型的不同版本,通过绘制一条回归线,表明 SSA 和困惑之间存在很强的相关性。虚线分别对应人类、其他机器人、Meena(base)、端到端训练模型的 SSA 性能,以及最终的具有过滤机制和已调谐解码的完整 Meena。
谷歌表示,他们研发的最好的端到端 Meena 模型(称为 Meena(base))的困惑度为 10.2(越小越好),并且 SSA 分数转换为 72%,完整版的 Meena 具有过滤机制和经过解码的解码功能,可将 SSA 分数进一步提高到 79%。
未来的研究与挑战
对于未来的规划,谷歌的研发人员表示将继续通过改进算法,体系结构,数据和计算来降低神经对话模型的困惑度。虽然目前研发人员只专注于这项工作中的明智性和特殊性,但其他属性(例如事实性等)在后续工作中也值得考虑。此外,解决模型中的安全性和偏差是谷歌关注的重点领域。
参考链接:
https://ai.googleblog.com/2020/01/towards-conversational-agent-that-can.html
https://venturebeat.com/2020/01/28/meena-is-googles-attempt-at-making-true-conversational-ai/

InfoQ编辑

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论