

BERT 是谷歌近期发布的一种自然语言处理模型,它在问答系统、自然语言推理和释义检测(paraphrase detection)等许多任务中都取得了突破性的进展。在这篇文章中,作者提出了一些新的见解和假设,来解释 BERT 强大能力的来源。作者将语言理解框架分解为解析和组合两个部分,注意力机制主要体现在解析过程,而组合过程也在 BERT 中起到了重要作用,因此作者提出对于 BERT Transformer 来说:attention isn’t all you need!
为什么 BERT 很重要
BERT是谷歌近期发布的一个自然语言处理模型,它在问答系统、自然语言推理和释义检测(paraphrase detection)等许多任务中都取得了突破性的进展。并且由于 BERT 是开源的,因此它在学界很受欢迎。
下图显示了GLUE基准分数的演变,GLUE 基准分数是多种 NLP 评估任务的平均分数。
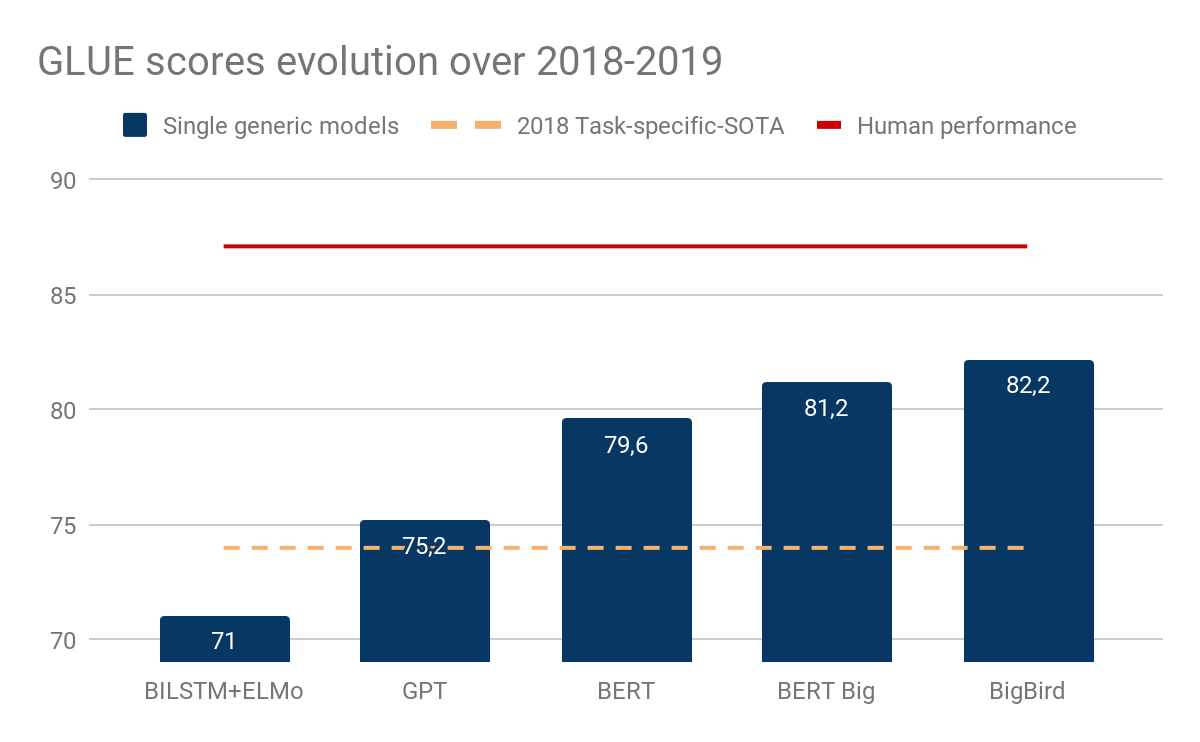
虽然目前还不清楚是否所有的 GLUE 任务都是非常有意义的,但是基于 Transformer 编码器的通用模型(open-GPT、BERT 和 BigBird)在不到一年的时间内就缩小了任务专用模型与人类的差距。
然而,正如 Yoav Goldberg 在论文《Assessing BERT’s Syntactic Abilities》中所指出的,我们并不能完全理解 Transformer 是如何编码句子的。
与 RNN 相比,Transformer 完全依赖注意力机制,并且,除了用单词的绝对位置嵌入来标记每个单词之外,Transformer 对单词顺序没有明确的概念。这种对注意力的依赖可能导致它在对语法敏感的任务上表现较差,而 RNN(LSTM)模型能够直接对单词顺序建模,并显式跟踪句子状态。
目前已有一些文章探讨了 BERT 的技术细节。在这里,我们尝试提出一些新的见解和假设,来解释 BERT 强大能力的来源。
语言理解的框架:解析-组合
人类理解语言的方式是一个长期存在的哲学问题。在 20 世纪,两个互补的理论揭示了这个问题:
组合性原理(Compositionality principle):词组的含义来源于单个单词的含义,以及这些单词组合的方式。根据这一原理,名词短语“食肉植物(carnivorous plants)”的含义可以通过“食肉(carnivorous)”和“植物(plant)”的组合过程中推导出来。[Szabó 2017]
另一个原理是语言的层次结构:通过分析,句子可以分解成简单的结构,如从句。而从句又可以进一步分解为动词短语和名词短语,等等。
通过对句子的层次结构进行解析,并递归地从其组成部分中推导含义,直到达到句子层面,这是一个很好的语言理解方法。假设这样一句话,“Bart watched a squirrel with binoculars(巴特用望远镜观察一只松鼠)”。一个好的解析组件可以生成下面的分析树:
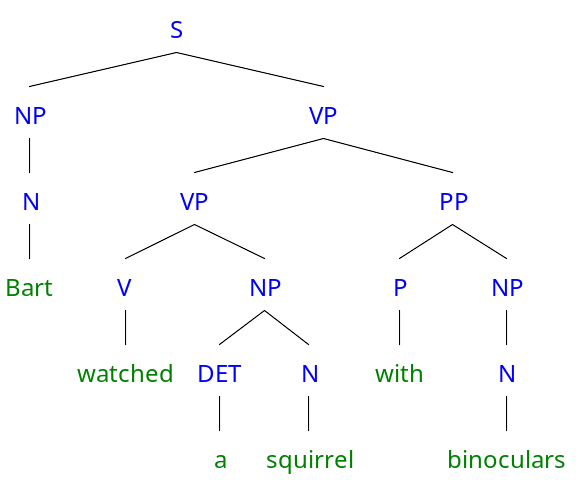
基于组件的“巴特用望远镜观察松鼠”句子的分析树
句子的意思可以从连续的组合中推导出来,首先是“a”和“squirrel”的组合,然后是“watched”和“a squirrel”的组合,最后是“watched a squirrel”和“with binoculars”的组合,直到得到整个句子的意思。
向量空间(词嵌入)可用于表示单词、词组和句子的其他成分。组合过程可以构造为函数 f,该函数将(“a”、“squirrel”)组合成一个有意义的向量表示,“a squirrel”=f(“a”、“squirrel”)。[Baroni 2014]
然而,组合和解析都是很困难的任务,并且它们互相依赖。
显然,组合过程需要依靠解析的结果来确定应该组合什么。但即使有了正确的输入,组合也是一个难题。例如,形容词的含义会根据它所描述的单词而变化:“white wine(白葡萄酒)”的颜色实际上是黄色的,而“white cat(白猫)”确实是白色的。这种现象称为共同组合(co-composition)。[Pustejovsky 2017]
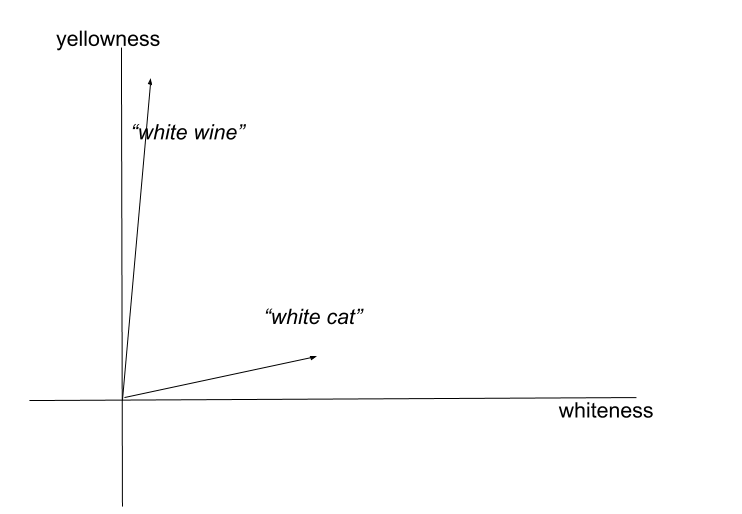
“白葡萄酒”和“白猫”在二维语义空间中的表现(颜色维度)
更广泛的上下文环境对于组合过程也是必要的。例如,“green light(绿灯)”中的词应该如何组合取决于具体情况。“绿灯”可以表示授权,或实际绿色的灯。有些习惯用语的含义需要某种形式的记忆,而不单单是组合。因此,在向量空间中完成这种组合需要强大的非线性函数,如深度神经网络(也具有记忆功能 [Arpit 2017])。
相反,解析操作在某些情况下可能需要组合才能工作。例如同一句子“Bart watched a squirrel with binoculars”的另一种解析树:
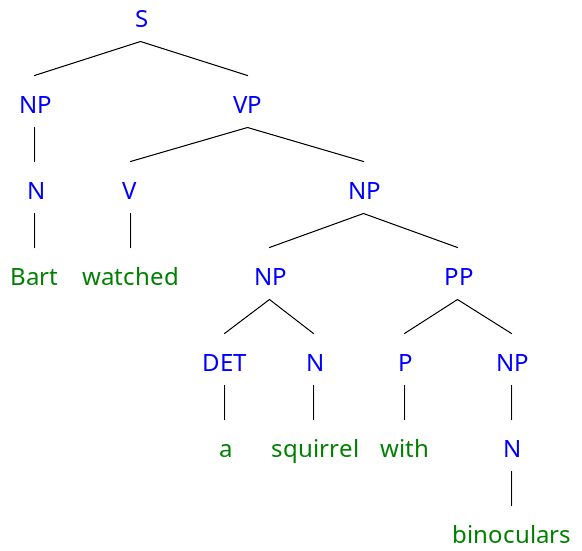
尽管它在语法上是成立的,但是这种解析导致了对句子的一种奇怪的解释:巴特看着一只松鼠拿着望远镜。然而,必须用某种形式的组合才能证明“一只松鼠拿着望远镜”是不太可能发生的事情。通常,在推导出恰当的结构之前,必须对背景知识进行消歧和整合。但是这个过程也可以通过某种形式的解析和组合来实现。
一些模型试图将解析和组合一起应用到实践中 [Socher 2013年],但是它们有一个限制条件,即依赖于手动标注的标准解析树,此外,它们已经被更简单的模型所超越了。
BERT 如何实现解析和组合
我们假设 Transformer 在很大程度上依赖于这两个操作,但是以一种创新的方式:由于合成和解析互相需要,Transformer 通过迭代过程,连续的执行解析和合成步骤,以解决相互依赖的问题。Transformer 是由几个堆叠的层(也称为块)组成的。每个块由一个注意力层和其后的非线性函数(应用于 token)组成。
我们将主要解释这些结构与解析-组合框架之间的联系。

Transformer 中一个块的结构,可以看作是连续的解析和组合步骤
注意力机制作为解析步骤
在 BERT 中,注意力机制让输入序列(由单词或子单词 token 构成的句子)中的每个 token 注意到其它的 token。
为了说明这一点,我们使用《Deconstructing BERT, Part 2: Visualizing the Inner Workings of Att-ention》中的可视化工具深入研究了注意力头(attention head),并在预训练的 BERT base Uncased 模型上(谷歌发布的 4 种预训练的 BERT 模型的一种)测试了我们的假设。在下面一个注意力头的例子中,“it”这个词注意到了其他所有的 token,并且似乎注意力集中在“street”和“animal”上。

第 0 层注意力头 1 对于 token“it”的注意力值可视化图
BERT 的每一层包含 12 个独立的注意力机制。因此,在每一层,每个 token 都可以关注其他 token 的 12 个不同方面。由于 Transformer 使用许多不同的注意力头(这里的 base BERT 模型用了 12*12=144 个),每个注意力头可以集中关注不同类型成分的组合。
我们省去了与“[CLS]”和“[SEP]”token 相关的注意力值。我们用几个句子做了测试,发现很难做到不过度解释结果,所以你可以随意用不同的句子在这个colab笔记本上测试我们的假设。请注意,在图中,左侧的序列关注右侧的序列。
在第 2 层中,注意力头 1 似乎会基于相关性形成组合成分。

更有意思的是,在第 3 层中,注意力头 11 似乎显示了更高级别的成分:一些 token 关注相同的中心词(if、keep、have)。

在第 5 层中,注意力头 6 采取的匹配过程似乎关注特定的组合,尤其是涉及动词的组合。像[SEP]这样的特殊 token 似乎被用来表示匹配关系的缺失。这可以使注意力头发现适合组合的特定结构。这种一致的结构可以输入给组合函数。

第 5 层注意力头 6:(we, have), (if, we), (keep, up) (get, angry)这些组合受到了更多关注
任意树可以用连续的浅层解析层表示,如下图所示:
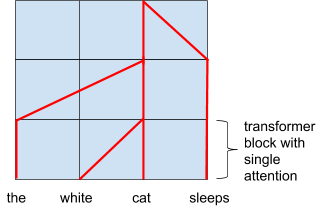
不同层的注意力可以表示树结构
通过对 BERT 注意力头的查看,我们没有发现如此清晰的树状结构,但是 Transformer 仍然有可能对其进行表示。我们注意到,由于编码是在所有层上同时进行的,因此很难正确地解释 BERT 在做什么。对给定层的分析只对其下一层和上一层有意义。解析也分布在各个注意力头上。
下图以两个注意力头为例,显示了 BERT 的注意力机制实际的情况:
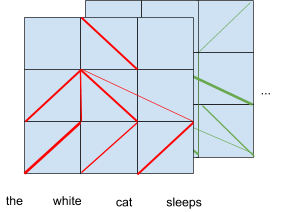
BERT 注意力值的实际情况
然而,正如我们之前所见,解析树是一个高级别的表示,它可能建立在更复杂的“根茎”结构上[Deleuze 1987]。 例如,我们可能需要找出代词所引用的内容,以便对输入进行编码(共指消解 coreference resolution:将现实世界中同一实体的不同描述合并到一起的过程,共指在自然语言中起到了超链接的作用,但也在其中增加了新的模糊成分)。在其他情况下,也可能需要全局上下文来消除歧义。
令人惊讶的是,我们发现一个注意力头(第 6 层注意力头 0)似乎真的进行了共指消解。 而且,正如文章《Understanding BERT Part 2: BERT Specifics》所指出的,一些注意力头似乎为每个单词提供了全局上下文(第 0 层注意力头 0)。

第 6 层注意力头 0 出现了共指消解。
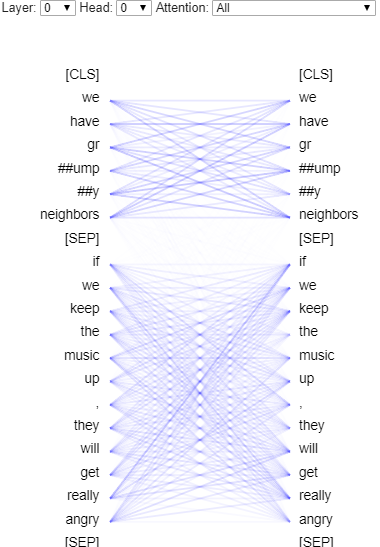
在一个句子中,每个词都注意到其他的词,这或许可以对每个词进行粗略的语境化。
组合过程
在每一层中,所有注意力头的输出被级接,并输入到一个可以表示复杂非线性函数的神经网络(这是实现一个有表达能力的组合过程所需要的)。
依靠来自注意力头的结构化输入,该神经网络可以进行各种组合。 在之前展示的第 5 层中,注意力头 6 可以引导模型进行以下组合: (we, have),(if, we),(keep, up),(get, angry)。 该模型将它们进行非线性组合,并返回组合后的表示。因此,多注意力头可以视作为组合过程铺平道路的工具。
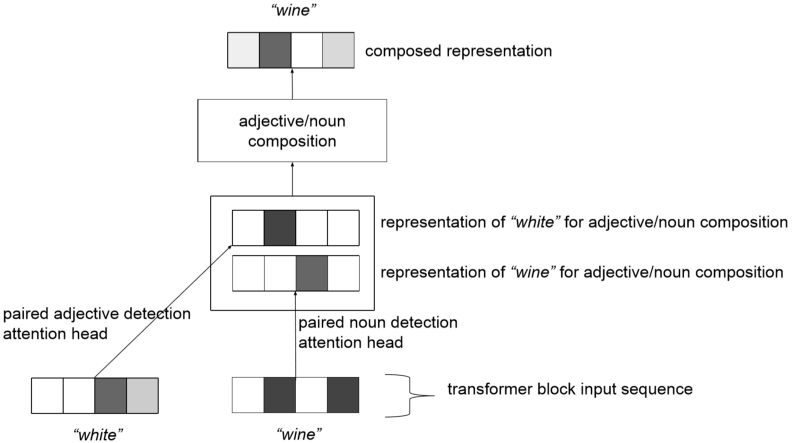
注意力头如何用于为特定的组合,例如形容词/名词
虽然我们没有发现注意力头关注某些更一致的组合,如形容词/名词,但是动词/副词的组合与模型所利用的其他组合之间可能存在一些共同点。
除了以上的组合,还存在许多可能相关的组合(单词-子词,形容词-名词,动词-介词,从句-从句)。进一步讲,我们可以将消歧(disambiguation)看作是把一个歧义词(bank)和相关语境词(river 或 cashier)进行组合的过程。在组合期间,模型也可以将给定上下文中与概念相关的背景知识进行整合。这种消歧也可能出现在其他层面(例如句子层面,从句层面)。

消歧作为组合过程
此外,组合过程还可能涉及词序推理。有人认为,位置编码(positional encoding)(位置编码是一个矢量,与输入内嵌表示求平均,以便生成输入序列中每个 token 的位置感知表示)可能不足以正确地编码单词的顺序。然而,位置编码的目的是编码每个 token 粗粒度、细粒度,甚至准确的位置。因此,基于两个位置编码,非线性合成在理论上可以基于单词相对位置进行关系推理。
综上所述,我们认为在 BERT 自然语言理解中,组合阶段也起到了重要作用,因此你所需要的并不只有注意力(Attention isn’t all you need)。
总结
我们提出了对 Transformer 的归纳偏置的一些见解。然而,我们必须记住,我们的解释可能对 Transformer 的能力持乐观态度。需要注意的是,LSTM 能够隐式处理树状结构[Bowman 2015]和组合过程[Tai 2015]。但是 LSTM 有其局限性,其中一些是由于梯度消失问题所导致的[Hochreiter 1998]。因此,要解释 Transformer 的局限性还需要进一步的工作。
查看英文原文:Understanding BERT Transformer: Attention isn’t all you need
公众号推荐:
2024 年 1 月,InfoQ 研究中心重磅发布《大语言模型综合能力测评报告 2024》,揭示了 10 个大模型在语义理解、文学创作、知识问答等领域的卓越表现。ChatGPT-4、文心一言等领先模型在编程、逻辑推理等方面展现出惊人的进步,预示着大模型将在 2024 年迎来更广泛的应用和创新。关注公众号「AI 前线」,回复「大模型报告」免费获取电子版研究报告。


暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论