
当今世界,数据就是金钱。各公司都在竭力收集尽可能多的数据,并力图找出数据中隐藏的模式,进而通过这些模式获得收入。然而,如果未能使用收集到的数据,或者未能通过分析数据挖掘出隐藏的宝石,那数据就一文不值。
当开始使用 Hadoop 构建大数据解决方案时,了解如何利用手中的工具并将这些工具衔接起来是最大的挑战之一。 Hadoop 生态系统中包括很多不同的开源项目。我们该如何选择正确的工具呢?
又一个数据管理系统
大多数数据管理系统至少可以分为数据获取(Data Ingestion)、数据存储(Data Storage)和数据分析( Data Analysis)三个模块。这几个模块之间的信息流动可以用下图表示:
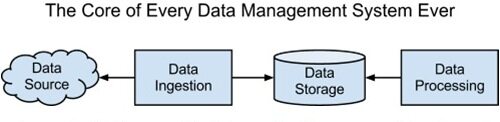
数据获取系统负责连接起数据源和数据的静态存储位置。数据分析系统用于处理数据,并给出可行的见解。转换为关系架构的话,我们可以用通用术语替换一下:
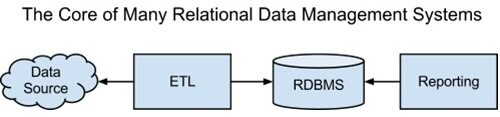
我们也可以将这一获取、存储和处理的基本架构映射到 Hadoop 生态系统,架构如下:
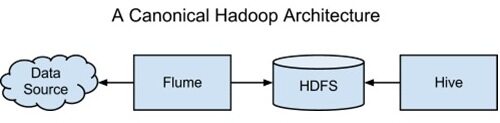
当然,这并非唯一的 Hadoop 架构。通过引入该生态系统中的其他项目,我们可以构建更为复杂的项目。不过这的确是最常见的 Hadoop 架构了,而且可以作为我们进入大数据世界的起点。在本文的其余部分,我们会一起完成一个例子应用程序,使用 Apache Flume 、 Apache HDFS 、 Apache Oozie 和 Apache Hive 来设计一个端到端的数据处理流水线系统,之后我们可以将其用于 Twitter 数据的分析。实现该系统所有必要的代码和说明都可以从 Cloudera Github 下载。
动机:测量影响力
社交媒体很受营销团队的欢迎,而 Twitter 就是一种能引起大众对产品的热情的有效工具。利用 Twitter,更容易吸引用户,还可以直接与用户交流;反过来,用户对产品的讨论又会形成口碑营销。在资源有限并且确定无法与目标群体中的每个人直接交流时,通过区别对待可接触到的人,营销部门的工作可以更为高效。
为了了解哪些人才是我们的目标人群,我们先来看看 Twitter 的运作方式。一个用户——比如说 Joe——关注了一些人,也有一些人关注他。当 Joe 发布一条更新后,所有的关注者都能看到该更新。Joe 也可以转发其他用户的更新。如果 Joe 看到 Sue 的一条 tweet 并加以转发,那么 Joe 的所有关注者都能看到 Sue 的这条 tweet,即便他们没有关注 Sue。通过转发,消息不止传给最初发送者的关注者,还能传得更远。知道了这一点,我们可以尝试吸引更新转发量非常大的那些用户。因为 Twitter 会跟踪所有 tweet 的转发数,我们可以通过分析 Twitter 数据发现我们所要寻找的用户。
现在知道了我们想问的问题:哪个 Twitter 用户被转发的信息最多?哪个人在我们这个行业影响力比较大?
如何回答这些问题?
可以使用 SQL 查询来回答这个问题:将转发降序排列,我们希望找出最大的转发量是由哪些用户导致的。不过在传统的关系数据库中查询 Twitter 数据并不方便,因为 Twitter Streaming API 是以 JSON 格式输出 tweet 的,这可能会非常复杂。在 Hadoop 生态系统中,Hive 项目提供了查询 HDFS 中数据的接口。Hive 的查询语言与 SQL 非常相似,但利用它为复杂类型建模很容易,因此我们可以轻松地查询我们所拥有数据的类型。看来这是个不错的起点。那么如何把 Twitter 数据导入到 Hive 中呢?首先,我们需要将 Twitter 数据导入到 HDFS 中,然后告知 Hive 数据的位置以及如何读取。
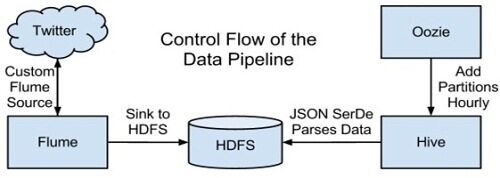
为回答上面的问题,我们需要构建数据流水线,上图就是汇集了某些 CDH 组件的高层视图。
使用 Apache Flume 收集数据
Twitter Streaming API 将为我们提供一个来自 Twitter 服务的稳定 tweet 流。使用像 curl 这样的实用工具来访问该 API,然后周期性地加载文件,这是一个选择。然而,这就需要我们编写代码来控制数据在何处进入 HDFS,而且,如果使用了安全集群,还必须集成安全机制。利用 CDH 内部的组件将文件自动从 API 移到 HDFS 就简单得多,并且无需手工干预。
Apache Flume 是一个数据获取系统,通过定义数据流中的端点来配置,这里的端点分别称作源(source)与汇(sink)。在Flume 中,每段数据(在我们的例子中就是tweet)都称为事件;源负责生成事件,并通过连接起源与汇的通道传递事件。汇负责把事件写入预定义位置。Flume 支持一些标准的数据源,如syslog 或netcat。对这里的例子而言,我们需要设计定制的源,使之能够使用Twitter Streaming API,然后将tweet 通过通道发送给汇,最后由汇负责将数据写入HDFS 文件。此外,我们还可以在定制的源上通过一组搜索关键词来过滤tweet,这样就可以识别出相关tweet,从而避免Twitter 的数据洪流。定制Flume 源的代码见该链接。
使用Apache Oozie 管理分区
一旦将Twitter 数据加载到HDFS 中,就可以通过在Hive 中创建外部表来查询了。利用外部表,不需要改变HDFS 中数据的位置,即可对表进行查询。为确保可伸缩性,随着添加的数据越来越多,我们也需要对表进行分区。分区表允许我们在查询时剪掉已经读过的文件,这在处理大规模数据集时会带来更好的性能。然而,Twitter API 将继续输出tweet,而Flume 也会不断地创建新文件。我们可以将随着新数据进入而向表中添加分区的周期性过程自动化。
Apache Oozie 是一个工作流协同系统,可用于解决这里的问题。对于作业工作流的设计而言,Oozie 非常灵活,可以基于一组条件调度运行。我们可以配置工作流来运行ALTER TABLE 命令,该命令负责向Hive 中添加一个包含上一小时数据的分区。我们还可以控制这个工作流每小时执行。这就能确保我们看到的总是最新的数据。
Oozie 工作流的配置文件见链接。
使用Hive 查询复杂数据
在开始查询数据之前,我们需要确保Hive 表可以正确地解释JSON 数据。Hive 默认希望输入文件采用分隔的行格式,但我们的Twitter 数据是JSON 格式的,因此在默认情况下无法工作。实际上这是Hive 最大的优势之一。Hive 允许我们灵活定义或重定义数据在磁盘上的表现方式。模式只有读数据的时候才需要真正保证,而且我们可以使用 Hive SerDe 接口来指定如何解释加载的数据。SerDe 代表的是 Serializer 和 Deserializer,这些接口会告诉 Hive,它如何将数据转换为 Hive 可以处理的东西。特别的是,Deserializer 接口用于从磁盘读数据时,该接口还会将数据转换为 Hive 知道如何操作的对象。我们可以编写一个定制的 SerDe,负责读入 JSON 数据并为 Hive 转换对象。上述工作实施之后,我们就可以开始查询了。JSON SerDe 代码见链接。SerDe 会接收 JSON 格式的 tweet 并将 JSON 实体转换为可查询的列:
SELECT created_at, entities, text, user FROM tweets WHERE user.screen_name='ParvezJugon' AND retweeted_status.user.screen_name='ScottOstby';
结果是:
created_at entities text user Mon Sep 10
21:19:23 +0000
2012 {“urls”:[],“user_mentions”:
[ {“screen_name”:“ScottOstby”,
“name”:“Scott Ostby”}],
“hashtags”:[{“text”:“Crowdsourcing”}]} RT @ScottOstby: #Crowdsourcing
– drivers already generate
traffic data for your smartphone
to suggest alternative routes
when a road is … {“screen_name”:“ParvezJugon”,
“name”:“Parvez Jugon”,
“friends_count”:299,
“followers_count”:70,
“statuses_count”:1294,
“verified”:false,
“utc_offset”:null,
“time_zone”:null}我们现在已经设法装配好了一个端到端的系统,能够从 Twitter Streaming API 收集数据,将 tweet 通过 Flume 发送到 HDFS 上的文件中,并且使用 Oozie 周期性地将文件加载到 Hive 中,还能通过 Hive SerDe 查询原始的 JSON 数据。
一些结果
在我的测试中,我让 Flume 收集了大约三天的数据,并使用下列关键字进行过滤:
Hadoop、big data、analytics、bigdata、cloudera、data science、data Scientist、business intelligence、mapreduce、data warehouse、data Warehousing、mahout、hbase、nosql、newsql、businessintelligence、cloudcomputing
如上面的 tweet 信息,大约收集到 0.5GB JSON 数据。数据有一定的结构,但某些字段可能存在,也可能不存在。比如 retweeted_status 字段,只有当该 tweet 是转发信息时才会存在。此外,某些字段可能会非常复杂。话题标签(hashtags)字段是 tweet 中出现的所有话题标签组成的数组,但大部分关系数据库不支持将数组作为列类型。这种半结构化数据在传统的关系数据库中很难查询,但 Hive 却能优雅地处理。
下面的查询会在我们的所有 tweet 数据中找出用户名以及他们生成的转发数:
SELECT t.retweeted_screen_name, sum(retweets) AS total_retweets, count(*) AS tweet_count FROM (SELECT retweeted_status.user.screen_name as retweeted_screen_name, retweeted_status.text, max(retweet_count) as retweets FROM tweets GROUP BY retweeted_status.user.screen_name, retweeted_status.text) t GROUP BY t.retweeted_screen_name ORDER BY total_retweets DESC LIMIT 10;
利用这几天的数据,我发现了该行业 tweet 转发最多的用户:
retweeted_screen_name total_retweets tweet_count mauricefreedman 493 1 HarvardBiz 362 6 TechCrunch 314 7 googleanalytics 244 10 BigDataBorat 201 6 stephen_wolfram 182 1 CloudExpo 153 28 TheNextWeb 150 1 GonzalezCarmen 121 10 IBMbigdata 100 37 从这些结果中我们能够看到听众最广的 tweet,还能确定这些人是否会定期与大家交流。可以利用该信息让我们的消息更有目的性,以便让他们谈论我们的产品,而这又会带动其他人一起谈论。
结论
本文中,我们看到了如何利用 CDH 的某些组件,以及如何将他们组合起来创建一个端到端的数据管理系统。类似架构可用于各种查看 Twitter 数据的应用,比如识别垃圾账号或识别成群的关键字。再深入一步,更一般的架构可以跨多个应用使用。通过插入不同的 Flume 源和 Hive SerDes,这种应用可以针对其他很多应用加以定制,如 Web 日志分析。请下载代码,亲自尝试一下。
关于作者

Jon Natkins (@nattybnatkins) 是 Cloudera 的一名软件工程师,他的主要工作是教育用户更高效地使用 Hadoop 和 CDH。他是相关 Apache 项目的固定贡献者,之前他是 Cloudera Manager 的开发者。
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


略懂技术的运营同学。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论