

在 2018 年爱奇艺联合 PRCV 会议举办的第一届多模态视频人物识别挑战赛中,来自 Infinivision 的团队获得冠军。现在,该团队分享了他们在比赛中的经验心得,希望可以为对多模态领域研究感兴趣的朋友提供参考。
前言:
在去年,我们团队决定参加由爱奇艺联合 PRCV 会议举办的第一届多模态视频人物识别挑战赛,为了这个挑战赛爱奇艺准备了迄今为止最大的人物视频数据集(IQIYI_VID)。参赛比赛的过程中我们团队经历了沉稳-自信-压力-兴奋的心理路程,十分有趣。
挑战赛的信息是从一个技术交流的群里了解到的, 因为挑战赛的方向比较合适目前的研究方向, 就毫不犹豫的注册参加了。我们团队 WitcheR(名字来源某著名游戏)包括 3 个成员:IBUG Jiankang Deng、公司的小伙伴 JackYu 和我。我们团队的合作模式比较简单,没有特别明确的分工,在比赛过程中中团队成员会相互交流想法,共同找出当前可能存在的问题与改进点,最终由我统一汇总来实现和验证。
在这次比赛中我们不仅积累了视频特征处理、检索的一些经验,同时也认识了业界的一些伙伴、朋友,并且进行了深入的学习和交流。
一、准备策略:
爱奇艺举办的视频人物识别挑战赛是一个针对视频的人物检索竞赛,赛题逻辑比较简单:在视频数据集 IQIYI_VID 中,计算出该视频包含的人物是谁。整个数据库包含 50 万条视频,5000 名人物(噪音清理后 4934), 每条视频的长度是 1~30 秒。爱奇艺准备的这份数据集很特别,做到了数据的大和干净,其中视频数量和包含的人物数量截至目前都是最高的,并且噪音维持在了一个极低的水平, 对检验模型算法性能有很好的参考意义。
对视频人物检索问题来说,我们可能可以利用的信息有:
(1)人脸识别模型
(2)人头识别模型
(3)行人重识别模型
(4)图片场景模型
(5)声纹模型
(6)人体姿态模型
在我们这次必定的方案中只用到了(1)和(4)。理由是:
1.人头识别缺少数据集
2.ReID model 可以和 recognition model 同时存在, 但泛化性能不如, 组合后会带来提升还是下降未知
3.声纹模型不熟悉
4.人体姿态步伐做人物识别更有些虚无缥缈
5.人脸识别是最重要的特征, 在能看到脸的视频里面起决定性作用
6.图片场景模型可以对检不到脸的场景做一些补充
第一波数据公布后我利用空闲时间开始了实验, 用各种策略评估官方第一次提供的训练/验证集合的精度:
1.帧速, 即每隔多少帧抽一次人脸/图片特征
2.检测器选择, 更准的检测器是否相比 MTCNN 带来更高的精度.
3.人脸特征聚合, 如何用特征来表示一个视频
4.获得视频特征后如何更好的提升检索性能
5.用什么人脸识别模型和图片场景模型
二、正式启动:第一次提交成绩第一 但很快被超过
在官方发布了所有数据集和测试集后,因为先期积累了一些经验,我们决定专门腾了一台 8 卡 P40 来做这个任务。
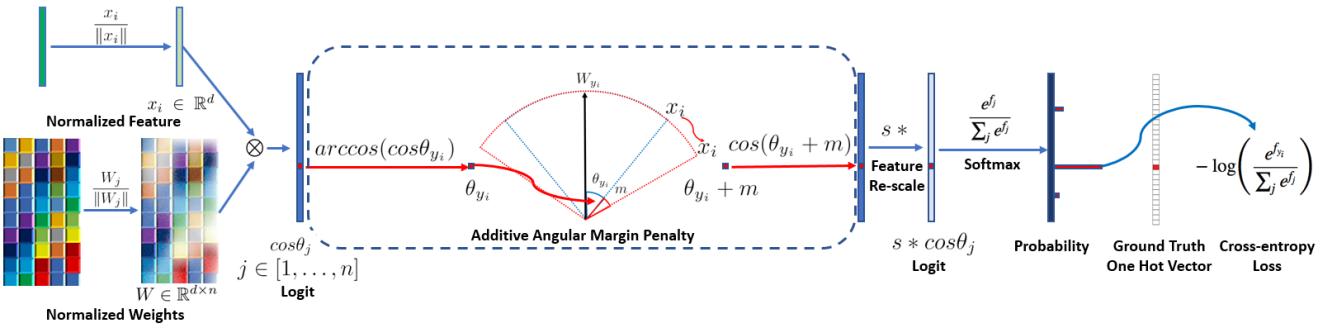
我们用了自己研发和训练的一个 one stage 检测器来同时检测人脸和关键点做对齐,相比 MTCNN,在 phase1 的 validation set 上能有差不多 1 个点的 mAP 提高。不管是在这个比赛中,还是其他的应用里,我们都发现关键点的精度是非常重要的,更精准的关键点能带来更好的识别性能。这个检测器也会很快在 insightface 上开源。人脸识别的模型训练数据我们用了 MS1M-Arcface(emore)+ Glint-Asia 的组合, 没有采用任何私有数据。 Loss function 用我们刚刚被 CVPR 2019 接收为 oral 的 Arcface:
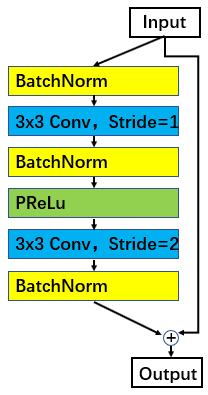
网络结构沿用了 paper 里面提出的 ResNet100 和 IR Block:
更多细节可以参考我们的文章:
对每段视频我们间隔 3 帧抽一次特征(~8FPS), 并对所有特征取平均来获得该视频的特征. 在这个过程中我也尝试了一些其他方法:
1.根据 feature norm 去掉模糊人脸,有提升
2.增加 flip augmentation,没有提升
3.增加 color jittering augmentation,性能下降
4.根据人脸 5 点估计姿态,并进行分组处理,没有提升
在获取每个视频的特征向量后,我们就可以通过简单的向量夹角来衡量视频之间的相似度,并根据测试视频和所有训练视频中最相似的视频来输出预测结果。这时候我提交了第一个结果,test mAP:79.8. 当时只有不到 10 个人提交,暂列第一, 但很快被超过。
三、调整策略:加速
A) MLP:
在上面的方法中有一个缺陷,实际上我们并没有用到训练集视频来做训练。我也尝试过把训练集的视频人脸图片抽取出来放到识别的训练集里,但效果并不好。那如何才能用到这些训练集信息? 答案是直接用视频向量做为输入训练一个多层感知机(MLP)。最简单的多层感知机很直观,输入 512 embedding,通过 2 个全连接层,来预测该向量属于某个人物分类的概率,最后加 softmax loss 来 BP。但这里面的设计就又有不同,多少层最好,每层的宽度多少, 用不用 BN,是否需要 shortcut connection,用不用 dropout, batch-size 多大等等这些因素都会很大程度影响最终结果。我们最终选取了如下策略:
1.三层感知机
2.层宽 channel size = 1024
3.PRelu 代替 Relu
4.在中间层使用 shortcut connection, 因输入输出分辨率一致.
5.使用 BN, 不使用 Dropout
6.用非常大的 batch-size 训练, 单卡 4096
7.Softmax 层之前添加一个 fix gamma 的 BN, 并和原始不加 fix gamma BN 的版本联合预测
这 7 个技巧是我们的 best setting。在使用最简单的 MLP 配置时,提交的 test mAP 为 82.9。加上这 7 个技巧以后,mAP=86.4, 足足提高了 3.5 个点。
B). 模型融合
模型融合可以说是打比赛必备的 trick, 多个模型一般来说总能提升最终结果的精度. 我们保持同样的数据集和训练方法,并采用不同的 random seed 训练了 4 个人脸识别模型。对这些识别模型也做同样的 MLP 训练来输出最终的预测概率, 并加权得到最终结果. 此时 mAP 得分来到 88.2。
C). 场景分类模型
对那些无法检出人脸的视频, 我们从 mxnet model zoo 里找到 imagenet11k+place365 预训练的 resnet152 模型做为基准模型,用抽取的视频图片做微调来预测每张图片属于哪个明星。做完分类处理后, mAP 最终定格在 88.6。
结果汇总:
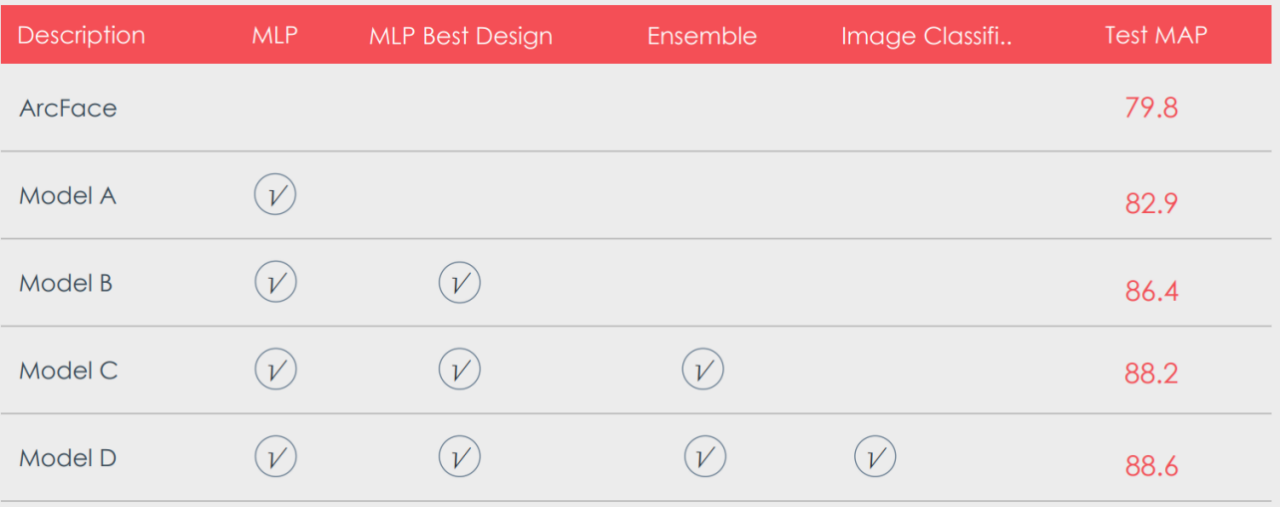
四、最后的决战:压力
在提交截止前的 2-3 天, 排名第二的队伍得分突然一下提高了很多, 离我们只差不多 1 个点的距离。而当时我们手上其实已经没什么牌可以打了。领跑了大半个赛季的我们,在最后一个夜晚还是比较担忧最终的成绩会被翻盘。焦虑不安的渡过了一个夜晚,第二天上午看到最终结果才放松下来。最终以总分比较高的优势拿到了这次比赛的第一名。
五、比赛经验:策略如何更容易的验证
纵观整个比赛过程, 付出最大精力的可能是如何使我们的 idea 更容易的去验证。Idea 很容易想, 可能一天会有好几个,在确定了方案之后,怎么能在现有的机器资源的条件下更快速的去验证,是比赛的一个关键。
尤其在数据量很大比赛中, 如果没有一个优质的流程, 不但会引起效率低, 更会忙中出错,简单介绍其中几种方法:
1.根据视频的 hash id 切分多卡跑检测, 并序列化中间结果. 对视频按帧检测比较耗时, 所以在检测策略没有发生变化的情况下可以保证复用结果;
2.对每个识别模型, 保存其对每一个视频的特征抽取结果. 在视频特征抽取算法不变的情况下保证可复用, 做为训练 MLP 的输入;
3.序列化保存每个训练的 MLP 模型和预测的概率信息, 做为最终模型融合的输入。
五、后记
在 PRCV2018 的颁奖现场我也与主办方和通过比赛认识的小伙伴们进行了亲切和友好的交流,结下了深厚友谊。针对如何提高视频、图像人物检索性能达成了一系列共识。2019 年的视频人物识别挑战赛已经开始了,这次比赛的数据集有了新的升级,也是业界中最接近实际媒体应用场景的视频人物数据集,在原有的基础上新增了短视频人物 ID 约 5000 个,包括一些特效、滤镜、换妆等。数据集 iQIYI-VID-2019 在复杂场景下 10000 名明星人物、200 小时、20 万条影视剧与短视频数据集,对于挑战者来说更具挑战性,我们团队会继续参加,并希望能有更多的志同道合的团队能来一起参与, 把成绩再提高更好的水平,也能为工业界多做贡献。本文里面提交的技巧和代码都有在 insightface 里面开源,可自行取用参考。
insightface 开源项目链接:https://github.com/deepinsight/insightface
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论