

Original URL: https://aws.amazon.com/cn/blogs/machine-learning/increasing-engagement-with-personalized-online-sports-content/
本文为 Pulselive 公司 Mark Wood 的客座文章。援引文中表述,“Pulselive 公司来自英国,是体育界众多知名品牌的最佳数字合作伙伴。”
在 Pulselive 公司,我们为体育爱好者们带来的体验已经成为体育赛事中不可或缺的组成部分:从板球世界杯官方网站,到英超联赛专属 iOS 与 Android 应用。
对我们来说,衡量客户体验的一大关键因素,在于粉丝群体在视频等数字内容层面的参与度。但就在不久之前,每一位粉丝所能看到的视频内容还仅仅只是对最新赛事的简单复制——没有任何个性化元素可言。
体育机构正在努力了解粉丝群体的身份定位,以及他们最希望看到怎样的内容。只有弄清这两个问题,才能真正从爱好者身上收集成规模的数字行为数据、理解他们的不同喜好并揣摩他们对体育内容进行互动的具体方式。随着可用数据的增加以及机器学习(ML)技术的发展,客户要求 Pulselive 提供更多量身定制的推荐内容。
在本文中,我们将分享自身经验,聊聊如何将 Amazon Personalize 作为新型推荐引擎添加至平台当中,并借此将视频观看量提升达 20%。
采用 Amazon Personalize
在开始之前,我们先来了解 Pulselive 面临的两大核心挑战:其一,我们没有任何数据科学家,因此需要一套成熟的解决方案,保证即使是对机器学习一无所知的工程师也能够理解其运作方式、并带来可以量化的成果产出。我们也考虑过使用外包企业提供协助,但成本过高只能作罢;与之相对,Amazon SageMaker 与 Amazon Personalize 等工具凭借着易于学习且成本低廉的优势吸引到我们的目光。
我们最终选择了 Amazon Personalize,具体原因包括:
这项服务的技术与经济入门门槛都比较低。
我们可以快速进行 A/B 测试,借此证明推荐引擎的实际价值。
我们可以建立简单的概念验证(PoC)项目,保证将对现有站点的影响降至最低水平。
我们其实对 Amazon Peronalize 的底层实现原理并不关注,真正重要的是它能带来怎样的影响、特别是改善效果。
与其他新业务一样,我们首先需要保证的是新方案的引入不致对原有日常运营产生不利影响。同时,我们还需要确保新的解决方案对于当前业务环境切实有效。为此,我们决定在概念验证阶段中进行 A/B 测试,借此建立一轮能够在几天内启动并顺利执行的前期试验。
通过与 Amazon Prototyping 团队开展合作,我们将首轮集成的范围缩小到几乎无需对网站进行更改,且易于进行 A/B 测试的程度。在全面筛查了用户观看视频的各具体位置之后,我们认为对视频列表进行重组排列,应该是实现内容个性化的最快方法。对于这套原型方案,我们使用 AWS Lambda 函数,并由 Amazon API Gateway 提供新的 API。此 API 负责捕获相关视频推荐,并使用 Amazon Personalize GetPersonalizedRanking API 对其进行重新排序。
为了证明调整是否成功,我们要求此轮试验必须在视频总观看次数或者视频观看完成率等方面具有统计学意义上的显著改善。为了达成这个目标,我们需要设定足够长的测试周期,以保证验证流程能够同时涵盖大赛日以及暂无赛事活动的常规日期。我们希望测试不同的使用模式,借此消除近期赛事活动对概念验证结果造成的重大影响。我们最终决定将试验周期设定为两周,在此期间收集初始数据。所有用户都将被纳入实验范围,且以随机方式被分配至对照组或者测试组当中。为了尽可能降低试验难度,我们还将所有站内视频都划入测试范围。下图所示,为这套解决方案的基本架构。
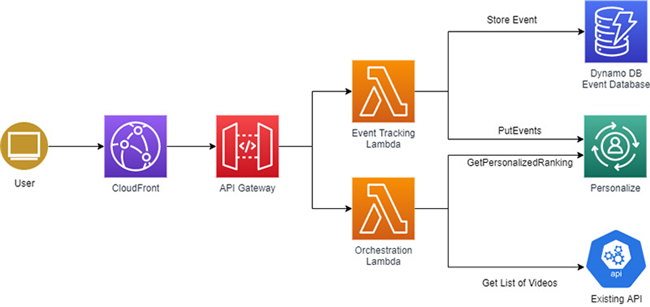
在起步阶段,我们首先构建了一套 Amazon Personalize 解决方案作为本次试验的起点。要实际定义解决方案并生成面向用户的视频推荐列表,Amazon Personalize 要求我们提供一套用户-视频交互数据集。我们为此创建了一个 CSV 文件,其中包含几个星期之内各视频视图的时间戳、用户 ID 以及视频 ID 等元数据。在将交互历史记录轻松上传至 Amazon Personalize 之后,我们即可在 AWS 管理控制台上测试推荐结果。为了完成模型训练,我们使用的数据集内包含 30000 条近期用户交互记录。
为了比较视频的总体观看次数与视频完成度百分比指标,我们还构建了另一个 API,用于记录 Amazon DynamoDB 中的所有视频交互活动。这个 API 负责通过 PutEvents API 向 Amazon Personalize 告知新的交互操作,借此帮助 ML 模型始终保持更新。
我们还跟踪了视频的总观看次数,以及在试验阶段向用户展示的推荐视频视图。这部分视频展示包括直接链接(例如社交媒体)、网站内链接以及视频列表提供的链接。每当有用户观看视频页面时,系统都会向其展示原有视频列表或者经过 Amazon Personalize 重新排序的新列表——具体取决于用户归属于对照组还是测试组。我们首先将总用户中的 5%纳入测试组,并在确认新方案不会产生意外问题时(即视频观看量未出现明显下降,API 错误也没有增加),将测试比例逐步提升至 50%——其余用户作为对照组——并开始收集数据。
从试验中汲取经验
经过为期两周的 A/B 测试,我们提取了由 DynamoDB 收集的 KPI,并比较了这两种解决方案在多个项目上的 KPI 结果。由于只是初始试验,因此初步 KPI 的选择较为简单,大家在实际应用中可能会选择不同的 KPI。
我们的第一项 KPI 为每项会话中每位用户的视频观看次数。我们的初步假设是,由于只是对推荐视频列表进行重新排序,因此不大可能出现显著的观看次数影响;但通过统计,我们发现每位用户的平均观看次数增加了 20%。下图所示,为各组用户的视频观看次数。
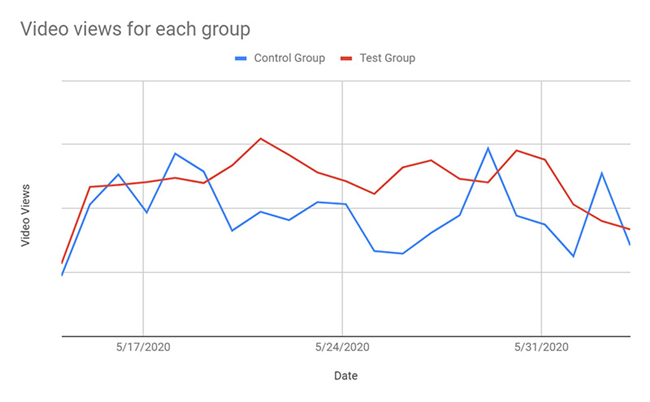
除了总观看次数之外,我们还希望保证用户能够从头到尾看完视频内容。为此,我们将视频内容划分为四段,每隔 25%发送一项事件以进行观看跟踪。在这方面,我们发现无论是使用 Amazon Personalize 提供的新列表,还是原始推荐视频列表,平均完成率都没有出现太大变化。结合视频的总观看次数,我们得出结论,在向每位用户展示个性化推荐视频列表时,其总观看时长确实有所增加。
我们还跟踪了各视频在用户“推荐视频”列表中的具体位置,以及用户实际选择了哪段推荐视频。以此为基础,我们得以比较个性化列表与原有固定排序的推荐效果,并发现二者之间并没有太大的区别。这表明我们的用户更倾向于直接选择当前屏幕中显示的推荐视频,而非向下滚动以查看完整的推荐列表。
在对结果进行分析之后,我们向客户展示了分析结论,并建议启用 Amazon Personalize 以作为后续推荐视频的默认排序方法。
经验与教训
在整个试验过程中,我们总结出以下经验教训供大家参考:
请认真为用户-视频交互收集历史数据;我们在训练中使用了约 30000 条交互记录。
关注近期历史数据。虽然视频网站一般不缺乏历史数据,但使用的交互数据越新,训练效果往往越好。如果您的历史交互数据集极为庞大,不妨过滤掉其中较为陈旧的部分,借此降低数据集体积以缩短训练时长。
确保使用单点登录解决方案或者生成会话 ID,为用户提供统一且唯一的 ID。
在您的站点或应用程序中找到理想位置,以此为基础运行 A/B 测试,或者对现有列表进行重新排序/直接显示原有推荐条目列表。
更新您的 API 以调用 Amazon Personalize,并获取新的推荐条目列表。
部署 A/B 测试,并逐渐增加实验组部分的用户百分比。
进行跟踪与量化,保证准确了解实验结果。
总结与后续计划
Amazon Personalize 为我们开启了新世界的大门,我们也对首次迈入 ML 领域感到无比激动。我们发现,将经过训练的模型纳入我们的工作流程其实非常简单易行。与使用 Amazon Personalize 相比,更耗费时间的反而是选择正确的 KPI 并捕捉必要数据,借此证明本轮试验的实际有效性。
着眼于未来,我们还将开发出以下增强功能:
将 Amazon Personalize 更深入地整合至完整工作流当中,包括在一切涉及推荐列表的部分使用 Amazon Personalize。
在重新排序之外扩展更多其他用例,包括由 Amazon Personalize 生成全新推荐内容,借此帮助用户发掘他们可能感兴趣的旧有内容。
调整模型的重新训练频率——向模型当中实时插入新的交互记录,是保持其始终紧跟最新趋势的好办法。事实上,将重新训练设定为模型的日常运营组成部分,将极大提升其运行效果。
探索如何与全体客户一道使用 Amazon Personalize,包括以各种方式推荐相关度最高的内容,借此提升体育爱好者们的参与度。
使用推荐过滤器扩展每项请求中的可用参数范围。我们还将尽快定位其他选项,例如通过筛选为您提供专属于特定选手的精彩视频。
作者介绍:
Pulselive 公司产品解决方案总监。Mark 在 Pulselive 供职超过六年,曾先后担任技术总监与软件工程师等职务。在加入 Pulselive 之前,Mark 曾任 Roke 公司高级工程师与 Querix 公司开发人员。Mark 毕业于南安普敦大学,拥有数学与计算机科学学位。
本文转载自亚马逊 AWS 官方博客
原文链接:
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论