
就说饿了。你首先在哪儿寻找食物?种菜的农场,可以觅食的森林,超市,还是你自己的储藏室和冰箱?
除非你生活在前工业时代,否则你的决定看起来是这样的:

在近代史上,最后一步也许是多余的,但其主要思想仍能成立。在你饥饿时,你并不会直接寻找食物的最终来源。假如在你的食物供应链中没有食物,你需要在食物供应链中找到最接近的本地环节 (通常是你自己的食品储藏室/冰箱)。
现在的问题在于,当我们将这一过程应用到食品中时,我们并没有将其应用到我们的信息/内容中。对于软件开发者/工程师来说,这将对我们的工作效率和心理健康产生深远影响。我们是知识工作者,消费信息就像食物一样,对于我们的生存和发展至关重要。
“第二大脑”的概念就源于此。
“第二大脑”是什么?
“第二大脑”这个短语是由生产力专家 Tiago Forte 提出来的。以他的话来说:
构建“第二大脑”是一套将传入的信息转化为完成的创造性项目的完整行为集。与其不断优化自己,试图成为一台效率机器,永远不会脱离计划,不如让你优化一个比你更可靠的外部系统。那样你就能自由地想象、猜疑、走向任何能让你此时此刻生活的事物。
从本质上讲,“第二大脑”是一种个人知识管理系统,它是你大脑的延伸,这样你就不需要这么费力地思考和记忆。将思考和记忆转移到自己的“第二大脑”中。
正如 Sherlock Holmes(名侦探福尔摩斯)的“心灵宫殿”(mind palace)一样,它是一个储存你所有挥之不去的想法的地方,也是一个整理你每天从书本、互联网和其他渠道获得的信息的地方,这样你就不会被不必要的信息所淹没,并利用重要的知识采取行动。
为什么要建造第二大脑?
大部分(如果不是所有的)软件开发者都有一套找到我们解决问题或学习新事物所需要的信息的方法。假如我们有一个需要帮助的问题,我们通常会遵循这样的伪供应链:
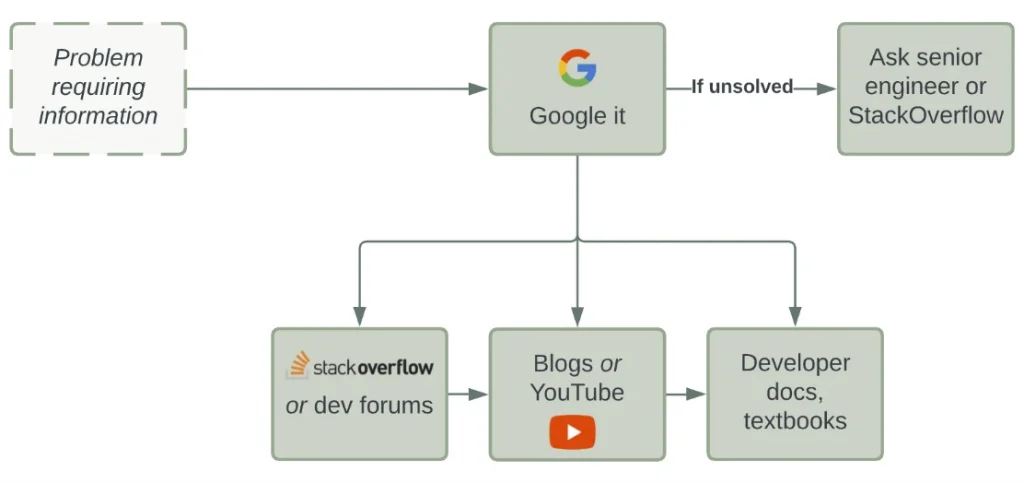
你可能知道,在我们所开发的供应链中,没有“本地环节”。谷歌是最接近的环节,这意味着我们利用庞大的、未经分类的网络,即互联网和谷歌对我们问题的解释作为我们的“第二大脑”。
通过搜索 StackOverflow 的大量问答数据库、YouTube 和个人博客上的数百万计的视频和文章,或者复杂的开发者文档,这些我们都忘记了一件事。
每当我们需要食物时,我们都会直接前往农场/森林。
“第二大脑”就是这个问题的解决方案。
藉由建立我们自己的“第二大脑”,我们可以在信息供应链中创造出自己的本地环节,并保存根据我们需要优化的相关信息,而不是每次都依赖谷歌和搜索互联网。
让我们来看看怎样能够建造“第二大脑”。
作为软件开发者,如何建造“第二大脑”
第一步·选择一个应用
你需要一些东西来作为容纳你的“第二大脑”的系统。
就像 Tiago Forte(第二大脑概念的最初创造者)所指出的,理想的第二大脑系统有 15 种品质,分为决定条件、必备因素和锦上添花:
决定条件
1. 快速捕捉和编辑。
2. 在演奏中,音阶达到数千个音符,没有滞后性。
3. 基本的格式设置选项。
4. 强大的搜索功能。
5. 处理图像和附件的能力。
6. 可公开共享的私有空间。
必备因素
7. 具有至少 3 层结构。
8. 多种捕捉信息的方法。
9. 本地和网络版本。
10. 捕捉并同步多种设备上的信息。
11. 可输出为纯文本。
锦上添花
12. 并排阅读
13. 子弹或列表
14. 自动打上日期戳
15. 标签
尽管可以使用像笔记本或便笺这样的手工方法,但是很难将这些方法扩展到成千上万的笔记、处理图片和代码段,允许快速捕捉/编辑的便携性,最重要的是要允许搜索。
因此,为什么数字系统必不可少(尤其是在软件开发的背景下)。
在撰写本文时,市场上有大量的数字笔记应用。然而,在本文中,我只想列出那些使用最广泛的“第二大脑”/个人知识管理系统。
所有列出的应用都符合“第二大脑”/个人知识管理系统的要求。每种应用的工作方式各不相同,也有其优点和缺点,因此要选择最适合你的应用程序。你的第二大脑是给你看和用的,不是给别人看的。
第二步·创建通用结构/线框
接下来,我们需要构建我们所选择的应用程序,以便有效地捕捉、分类和检索相关信息。以下两个组织系统较为突出:
Zettlekasten 方法提倡用一种规则的方式记笔记,笔记被“原子化”,并以尽可能短和最模块化的方式捕捉。当你捕捉并分解为组件后,你可以搜索你以前所做过的相关笔记,并将它们链接起来。最终,更新整个笔记网络,以便可以访问你最近捕捉的笔记。拥有一个笔记网络很有价值,但是需要花费很多时间和精力。
PARA 方法减少了信息采集的疲劳。无需链接。这只是把所有信息按目的和及时相关性分成四类:
(任务)——存储在项目或内存中的信息
项目——要达到的目标,有截止日期——现在需要的信息
领域——标准/宽泛类别,没有结束日期——稍后需要的信息
资源——持续关注的话题/主题——有一天需要的信息
档案——你暂时不会用到的信息,不适合其他三个类别——不需要的信息/仅供保存以备万一的信息。
这些类别都是嵌套的。任务被嵌套在项目之下,而项目又属于资源之下的领域,而资源又属于档案,档案则是一个包罗万象的类别。
项目作为你的短期记忆,保存着你现在/不久就可能需要的信息,而你越深入(即领域→资源→档案),就越晚需要这些信息。
在将所有捕捉到的信息分类到上述类别之前,为它们设立一个入口(或收件箱)也是一个好主意。
第三步·为捕获的信息创建数据结构
上述通用的线框描述了在哪里定位和分类信息,但是没有描述如何描述信息来满足我们的需求。在所捕捉的信息中,我们需要提供正确的元数据,以便日后更容易地组织和检索。
本文绝不可能希望将每一位软件开发者所需的所有信息都包括在内。然而,大多数开发者都需要以下一些信息示例,以及他们如何有效地存储这些信息。
常见问题:构建自己的 StackOverflow
常见问题是信息最原始、最直接的形式。信息搜索始于我们想要答案的问题或者我们想要解决的问题。通常可以在 StackOverflow 或者开发者论坛,或者在线社区中找到常见问题。
问题——你的问题(不一定是信息来源作者的问题)。
答案——对你有帮助的答案(如果可能的话,重写原始答案,使其与你的原始问题更加相关)。
标签——关键词,这样以后搜索起来就很容易了。
链接/相关阅读——指向其他有用信息的链接(尽量使你的笔记保持精简)。
(日期)——应该由笔记应用自动捕捉。
代码片段和样板文件
为了在特定的环境中复制粘贴,代码片段和样板文件非常容易操作。当考虑到这些数据结构时,要注意一种语言和一种背景的代码不一定适用于不同语言/背景的项目。
另外,与常见问题不同,代码片段不容易基于文本内容搜索。因此,要将所有代码片段放入一个通用结构(例如 Notion 数据库或带有过滤器的表格),这很重要,你就可以基于语言、类型和上下文进行搜索。举例来说,你应该能够搜索带有样式上下文的所有前端 JavaScript 代码片段。
语言——例如 JavaScript、Python、Go。
类型——例如前端、后端、部署/DevOps。
背景——创建你自己的多选类别,以进一步描述片段的目的,例如,这是否与样式、进行 API 调用、创建实用函数等有关。
(描述)——代码段的基于文本的描述。
片段——实际的代码段/样板文件(用代码标签包装)。
(依赖关系)——链接到任何其他相关的代码或包,或者需要使用这个代码段的链接。
文档模板
这些基本上是文本段。你项目所需的每一份文档的模板,例如 README(自述文件)、CONTRIBUTING(贡献文件)文件、代码审查过程或测试计划,都应该存储在这里。
尽管这些都是基于文本的,但是搜索一个特定的文档(比如 README)仍然没有听起来那么简单。正因为如此,像代码段一样,将文档模板保持在一个能够被过滤的通用结构中很重要。
类型——例如前端、后端、部署/DevOps。位置——这个模板放在哪里? 例如:存储库、项目管理、客户端。标题——例如:README、CONTRIBUTING、QA 计划。模板——实际的模板。(描述)——代码段的基于文本的描述。
资源
资源是可操作性最差、但最有教育意义的信息形式。当你想要更多地了解一个宽广的领域,而非解决某个特定问题时,你需要看视频、课程、教程(等等)。
例如,如果你想学习 Python,你会把你遇到的最好的 Python 学习资源(即教程、视频、文章和课程)保存在你的“第二大脑”中,那样的话,如果你将来想学习 Python,你就不需要重复搜索。
由于资源是你的长期记忆版本,所以你必须付出一些努力,使它们在将来容易被检索到。
名称——资源的搜索优化的名称。
作者——资源的原作者。
类别——例如,视频、文章、书籍、推文、课程、网站。
URL——可以在哪里访问该资源(注意:你并不需要数据库中的全部资源,你只需要一个链接,以尽量减少臃肿)。
状态——是否已经完成对该资源的审阅?
标签——不在名称中的关键词,以便将来可以方便地进行搜索。
(评价)——该资源是怎样有效地解决你的问题或者教你点什么。
第四步·确定信息工作流
现在的首要任务是弄清楚:
如何寻找解决问题所需的信息?
当信息进入第二大脑后,将如何进行分类?
寻找信息
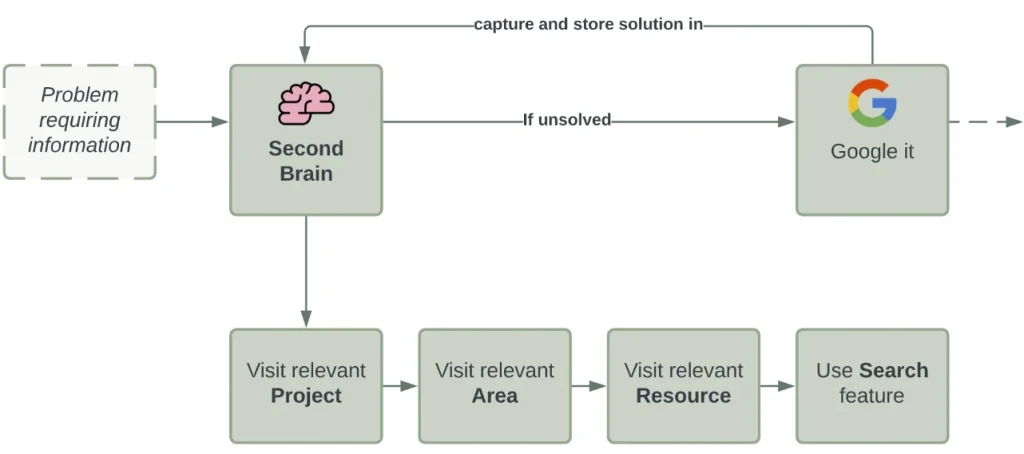
这是你在信息供应链中加入你的“第二大脑”的部分。如果你有一个特别的问题,你现在不是直接去找谷歌,而是先去找你的“第二大脑”。
既然我们已经根据内容的目的、相关性和及时性整理好了内容,以下是我们所需信息的工作流,
下面是我们寻找解决遇到的问题所需信息的工作流程:
分类信息
理想情况下,你将拥有一个收件箱部分,所有传入的捕捉信息都将进行初始存储。从这里开始,需要按 PARA 方法将其分类到适当的类别。
根据它的相关性和及时性,它需要进入适当的项目、区域或资源总括。

例如,如果你正在做一个 MERN 堆栈项目,那么关于“如何使用 Express 设置 MongoDB”的代码段就非常相关,应该被放在适当的项目部分。而“如何用 Django 创建 REST API”的教程与此无关,可将其放在资源部分中,供将来使用。
你最好每天进行分类,审阅传入信息,避免信息过载。
摘要·流程图
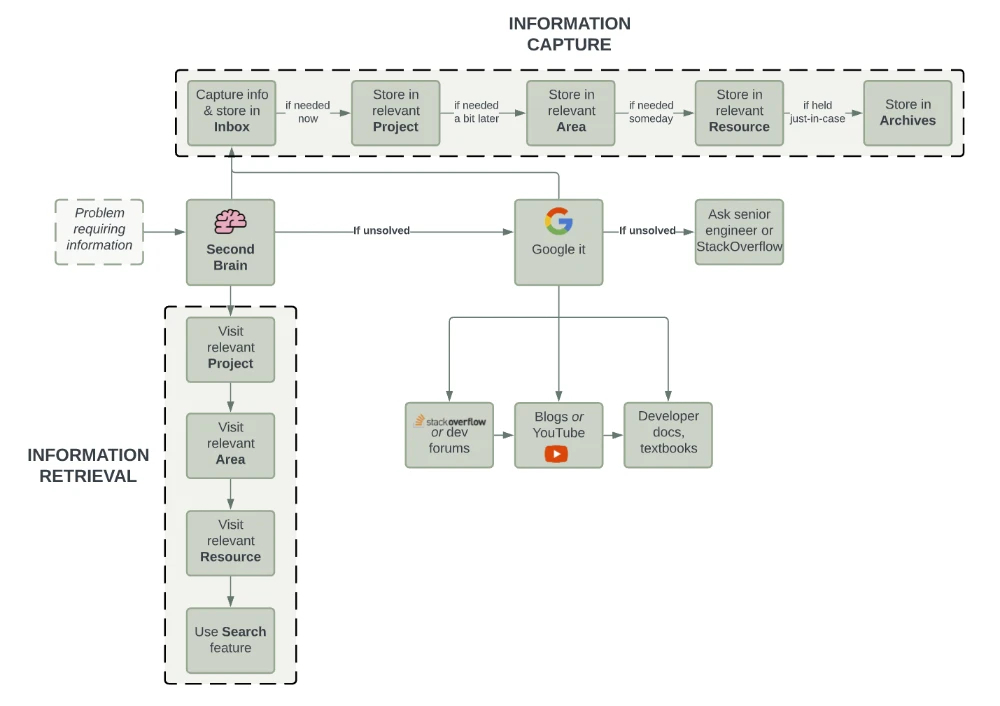
这绝不是一个全面的指南。但我承认,我可能漏掉了许多你需要的信息,以使一个运转良好的第二大脑系统发挥作用。要想获得更全面的建立“第二大脑”的通用指南,请查阅 Tiago Forte 的课程。他在个人知识管理/第二大脑系统方面比我更有权威。
本文的主要目的就是要告诉所有的开发者,用谷歌找到他们遇到的所有问题的方法都是低效和无益的。但愿我能做到这一点,并向你们展示一种做事的方法。
作者介绍:
Aseem Thakar,白天是软件工程师,晚上是独立黑客/企业家。
原文链接:
https://aseemthakar.com/how-to-build-a-second-brain-as-a-software-developer/
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论