

Kafka 是非常流行的分布式流式处理和大数据消息队列解决方案,在技术行业已经得到了广泛采用,在 Dropbox 也不例外。Kafka 在 Dropbox 的很多分布式系统数据结构中发挥着重要的作用:数据分析、机器学习、监控、搜索和流式处理,等等。在 Dropbox,Kafka 集群由 Jetstream 团队负责管理,他们的主要职责是提供高质量的 Kafka 服务。他们的一个主要目标是了解 Kafka 在 Dropbox 基础设施中的吞吐量极限,这对于针对不同用例做出适当的配置决策来说至关重要。最近,他们创建了一个自动化测试平台来实现这一目标。这篇文章将分享他们所使用的方法和一些有趣的发现。
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
测试平台
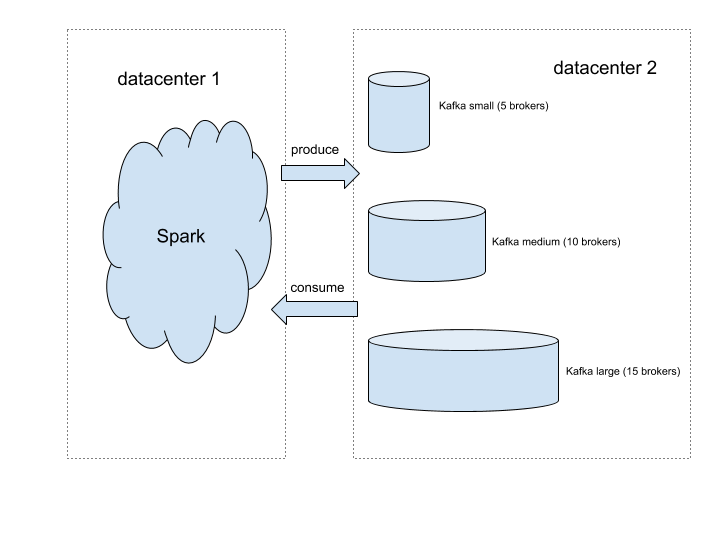
上图描绘了本文所使用的测试平台的设置。我们在 Spark 中使用 Kafka 客户端,这样就可以以任意规模生成和消费流量。我们搭建了三个不同大小的 Kafka 集群,要调整集群大小,只需要将流量重定向到不同的集群。我们创建了一个 Kafka 主题,用于生成测试流量。为简单起见,我们将流量均匀地分布在 Kafka broker 之间。为实现这一目标,我们创建了测试主题,分区数量是 broker 数量的 10 倍,这样每个 broker 都是 10 个分区的首领。因为写入单个分区是串行的,所以如果每个 broker 的分区太少会导致写入竞争,从而限制了吞吐量。根据我们的实验,10 是一个恰到好处的数字,可以避免写入竞争造成吞吐量瓶颈。
由于基础设施的分布式特性,客户端遍布在美国的不同地区。因为测试流量远低于 Dropbox 网络主干的限制,所以我们可以安全地假设跨区域流量的限制也适用于本地流量。
是什么影响了工作负载?
有一系列因素会影响 Kafka 集群的工作负载:生产者数量、消费者群组数量、初始消费者偏移量、每秒消息数量、每条消息的大小,以及所涉及的主题和分区的数量,等等。我们可以自由地设置参数,因此,很有必要找到主导的影响因素,以便将测试复杂性降低到实用水平。
我们研究了不同的参数组合,最后得出结论,我们需要考虑的主要因素是每秒产生的消息数(mps)和每个消息的字节大小(bpm)。
流量模型
我们采取了正式的方法来了解 Kafka 的吞吐量极限。特定的 Kafka 集群都有一个相关联的流量空间,这个多维空间中的每一个点都对应一个 Kafka 流量模式,可以通过参数向量来表示:<mps、bpm、生产者数量、消费者群组数量、主题数量……>。所有不会导致 Kafka 过载的流量模式都形成了一个封闭的子空间,其表面就是 Kafka 集群的吞吐量极限。
对于初始测试,我们选择将 mps 和 bpm 作为吞吐量极限的基础,因此流量空间就降到二维平面。这一系列可接受的流量形成了一个封闭的区域,找到 Kafka 的吞吐量极限相当于绘制出该区域的边界。
自动化测试
为了以合理的精度绘制出边界,我们需要用不同的设置进行数百次实验,通过手动操作的方式是不切实际的。因此,我们设计了一种算法,无需人工干预即可运行所有的实验。
过载指示器
我们需要找到一系列能够以编程方式判断 Kafka 健康状况的指标。我们研究了大量的候选指标,最后锁定以下这些:
IO 线程空闲低于 20%:这意味着 Kafka 用于处理客户端请求的工作线程池太忙而无法处理更多工作负载。
同步副本集变化超过 50%:这意味着在 50%的时间内至少有一个 broker 无法及时复制首领的数据。
Jetstream 团队还使用这些指标来监控 Kafka 运行状况,当集群承受过大压力时,这些指标会首当其冲发出信号。
找到边界
为了找到一个边界点,我们让 bpm 维度固定,并尝试通过更改 mps 值来让 Kafka 过载。当我们有一个安全的 mps 值和另一个导致集群接近过载的 mps 值时,边界就找到了。我们将安全的值视为边界点,然后通过重复这个过程来找到整条边界线,如下所示:
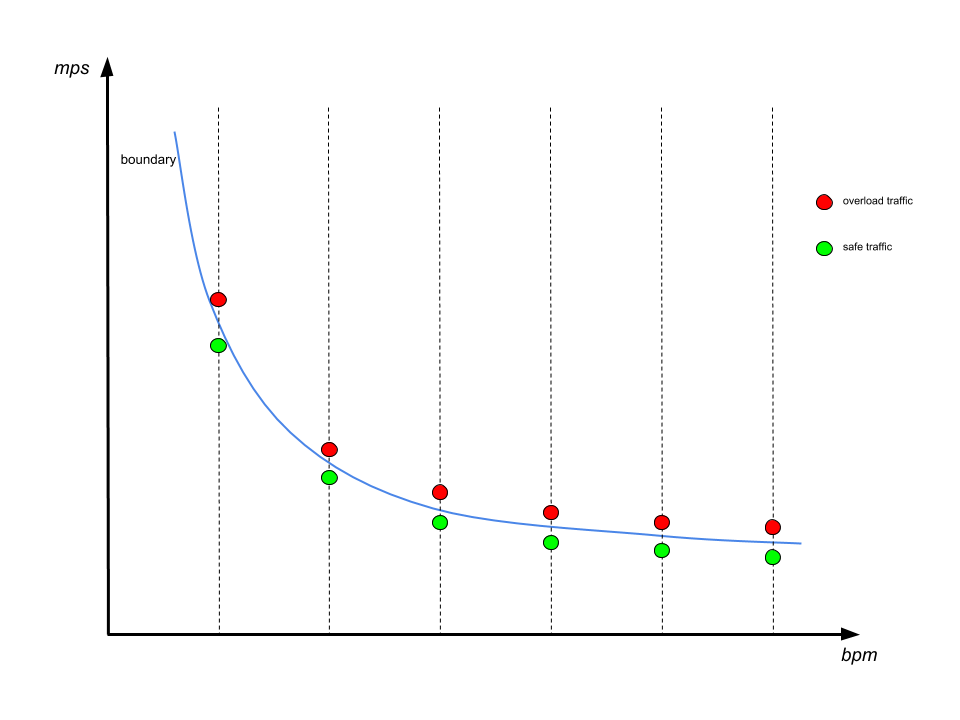
值得注意的是,我们调整了具有相同生产速率的生产者(用 np 表示),而不是直接调整 mps。主要是因为批处理方式导致单个生产者的生产速率不易控制。相反,改变生产者的数量可以线性地缩放流量。根据我们早期的研究,单独增加生产者数量不会给 Kafka 带来明显的负载差异。
我们通过二分查找来寻找单边界点。二分查找从一个非常大的 np[0,max]窗口开始,其中 max 是一个肯定会导致过载的值。在每次迭代中,选择中间值来生成流量。如果 Kafka 在使用这个值时发生过载,那么这个值将成为新的上限,否则就成为新的下限。当窗口足够窄时,停止该过程。我们将对应于当前下限的 mps 值视为边界。
结果
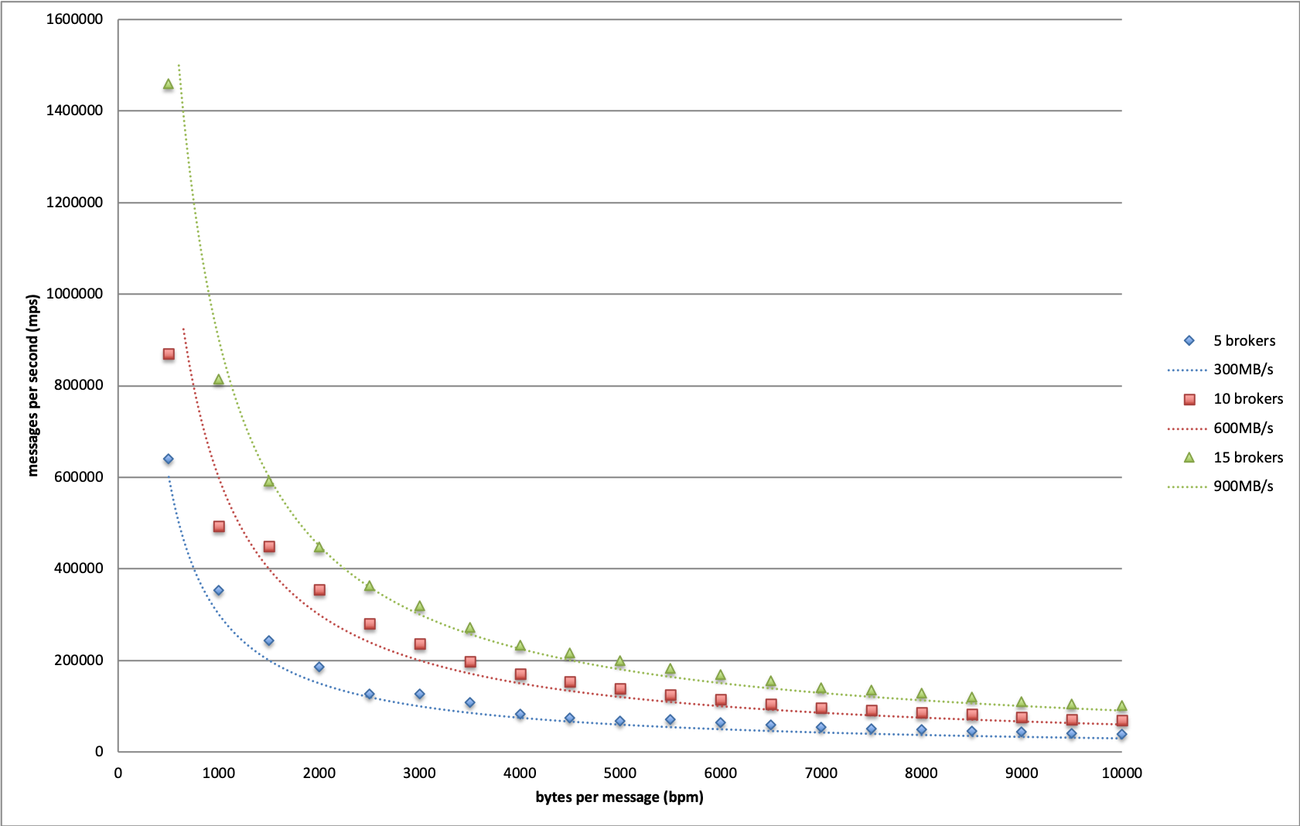
我们在上图中绘制了不同大小的 Kafka 的边界。基于这个结果,我们可以得出结论,Dropbox 基础设施可以承受的最大吞吐量为每个 broker 60MB/s。
值得注意的是,这只是一个保守的极限,因为我们测试用的消息大小完全是随机的,主要是为了最小化 Kafka 内部消息压缩机制所带来的影响。在生产环境中,Kafka 消息通常遵循某种模式,因为它们通常由相似的过程生成,这为压缩优化提供了很大的空间。我们测试了一个极端情况,消息全部由相同的字符组成,这个时候我们可以看到更高的吞吐量极限。
此外,当有 5 个消费者群组订阅测试主题时,这个吞吐量限制仍然有效。换句话说,当读取吞吐量是当前 5 倍时,仍然可以实现这样的写入吞吐量。当消费者群组增加到 5 个以上时,随着网络成为瓶颈,写入吞吐量开始下降。因为 Dropbox 生产环境中的读写流量比远低于 5,所以我们得到的极限适用于所有生产集群。
这个结果为将来的 Kafka 配置提供了指导基础。假设我们允许最多 20%的 broker 离线,那么单个 broker 的最大安全吞吐量应为 60MB/s * 0.8 ~= 50MB/s。有了这个,我们可以根据未来用例的估算吞吐量来确定集群大小。
对未来工作的影响
这个平台和自动化测试套件将成为 Jetstream 团队的一笔宝贵的财富。当我们切换到新硬件、更改网络配置或升级 Kafka 版本时,可以重新运行这些测试并获得新的吞吐量极限。我们可以应用相同的方法来探索其他影响 Kafka 性能的因素。最后,这个平台可以作为 Jetstream 的测试平台,以便模拟新的流量模式或在隔离环境中重现问题。
总结
在这篇文章中,我们提出了一种系统方法来了解 Kafka 的吞吐量极限。值得注意的是,我们是基于 Dropbox 的基础设施得到的这些结果,因此,由于硬件、软件栈和网络条件的不同,我们得到的数字可能不适用于其他 Kafka 实例。我们希望这里介绍的技术能够帮助读者去了解他们自己的 Kafka 系统。
英文原文:
https://blogs.dropbox.com/tech/2019/01/finding-kafkas-throughput-limit-in-dropbox-infrastructure/


暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 1 条评论