

现代微服务架构由于业务系统模型日趋复杂,分布式系统中需要一套链路追踪系统来帮助我们理解系统行为,明确服务间调用。最近作者请到了 Zipkin 项目的主要开发维护人员 Adrian Cole 来介绍有关 Zipkin 项目的细节内容,可以让大家了解到如何在分布式追踪系统中用好 Zipkin。
Adrian 一直在从事云计算相关开源项目的开发,是开源项目 Apache jclouds 和 OpenFeign 的创始人。最近几年,他专注于分布式跟踪领域,是 OpenZipkin 项目的主要开发维护人员。Adrian 目前在 Pivotal Spring Cloud OSS 团队工作。在加入 Pivotal 之前,他还在 Twitter,Square,Netflix 工作过。
总所周知 Zipkin 项目起源于 Twitter, 您能给我们介绍一下项目的相关背景吗?
Adrian:Zipkin 是由 Twitter 内部构建的分布式追踪项目,于 2012 年开源。它最初被称为 BigBrotherBird,因此即使在今天,http 标头也被命名为“B3”。Twitter 早期因为业务发展迅猛,经常会出现系统过载情况。每当出现这种情况时,用户会看到一条搁浅的鲸鱼显示在页面上。Zipkin 这个名字也与鲸鱼有关,因为 Zipkin 是鱼叉的意思,构建初衷是为了追踪“搁浅的鲸鱼”相关的系统延迟问题。Zipkin 的成功除了和 Twitter 的的品牌加持有关,其他因素也起到很大作用:一是 Zipkin 包含了客户端、服务器、用户界面等所有你需要的部分;此外,Twitter Engineering 上一篇介绍 Zipkin 的博客也引起了轰动。随着时间的推移,Zipkin 成为了数十种可观察性工具之一。
分布式调用追踪对微服务监控有什么价值,为什么大家要为微服务建这样的追踪系统?
Adrian:这里我想引用 Netflix 的局点文档(Zipkin 的用户使用报告)中的描述来总结分布式追踪系统的价值:
其商业价值在于为系统提供了一个操作层面的可视化界面,同时提升开发人员的生产效率。
对于微服务系统来说,如果没有分布式追踪工具的帮助,要了解各个服务之间的调用关系是相当困难的。即使对于非常资深的工程师来说,如果只依靠追踪日志,分析系统监控信息,也是很难快速定位和发现微服务系统问题的。分布式调用追踪系统可以帮助开发人员或系统运维人员及时了解应用程序及其底层服务的执行情况,以识别和解决性能问题或者是发现错误的根本原因。分布式追踪系统可以在请求通过应用系统时提供端到端的视图,并显示应用程序底层组件相关调用关系,从而帮助开发人员分析和调试生产环境下的分布式应用程序。
在业界已经大量采用微服务架构的今天,Zipkin 在工业界微服务系统问题追踪方面扮演了很重要的角色,您能给我们介绍一下业界是如何使用 Zipkin 项目的吗?
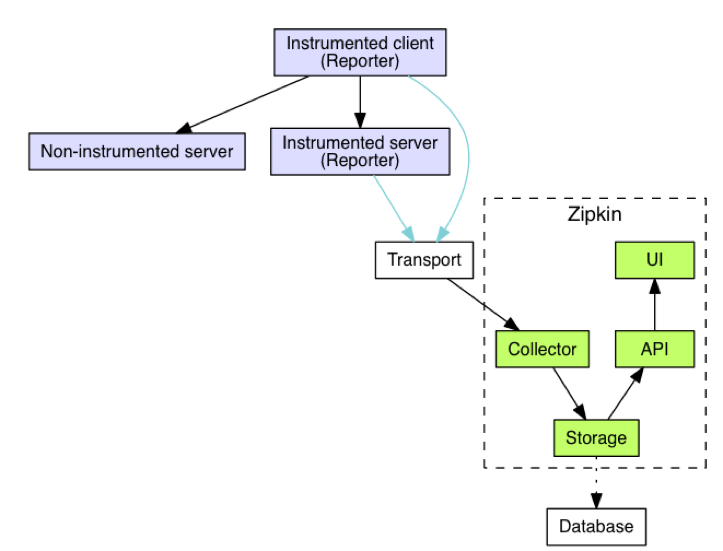
Adrian:在回答这个问题之前,我们先简单介绍一下 Zipkin 的系统架构。Zipkin 包含了前端收集以及后台存储展示两部分。为了追踪应用的调用情况,我们需要在应用内部设置相关的追踪器来记录调用执行的时间以及调用操作相关的元数据信息。一般来说这些追踪器都是植入到应用框架内部的,用户应用程序基本感知不到它的存在。如下图所示当被监控的客户端向被监控的服务器端发送消息时,被监控客户端和被监控服务器端的追踪器会分别生成一个叫做 Span 的信息通过报告器(Report)发送到 Zipkin 后台。一次跨多个服务的调用会包含多个 Span 信息,这些 Span 信息是通过客户端与服务器之间传输的消息头进行关联的。 后台会通过收集器(collector)接收 Span 消息,并进行相关分析关联,然后将数据通过存储模块存储起来供 UI 展示。
Zipkin 在项目开源之初就包含了一个完整的追踪解决方案方便大家上手,同时通过传输协议以及相关消息头开源,帮助 Zipkin 很容集地成到用户的监控系统中。这让 Zipkin 能够在众多的追踪系统中脱颖而出,成为工业界最常用的追踪工具。
在 2015 年的时候我们发现不是所有人都有分布调用追踪的系统使用经验,他们不太了解如何成功搭建分布式追踪系统。因此我们整理了很多业界使用 Zipkin 的相关资料,并在 Google Drive 上创建了相关文档目录存放这些资料。考虑到大家访问 Google Drive 可能会不太方便,后来我们创建了 wiki 来分享如何使用 Zipkin,让更多人了解其他人是如何使用 Zipkin 来解决追踪系统中存在的问题的。
在这里你可以看到像 Netflix 这样的大厂是如何使用 Zipkin 以及 Elasticsearch 处理每天高达 5TB 的追踪数据,Ascend Money 是如何将公有云和私有云结合在一起使用 Zipkin,Line 是如何将 Zipkin 与 armeria 结合进行异步调用追踪的,以及 Sound Cloud 是如何结合 Kubernetes Pod 的元数据信息改善 Zipkin 追踪的。这里我们也欢迎更多的中国用户能够在此分享你们使用 Zipkin 的经验。
对了,如果你是 Zipkin 用户, 记着给我们的代码仓库加星,这是对我们最大的鼓励。
我们知道 Zipkin 项目目前在生产环境中大量使用,他们是直接使用这些项目还是依据自己的需要对项目进行了相关的修改?
Adrian:因为 Zipkin 项目运作是建立在用户吃自己的狗粮 (使用自己开发的软件)的基础上, 很多新工具都是先在用户内部使用,然后开源变成通用项目。例如 zipkin-forwarder 这个项目就是 Ascend 结合自己的业务需要实现的跨多个数据中心转发数据实验性项目。Yelp 实现了一个 Zipkin 代理用来读取多个 Zipkin 集群的数据。LINE 在内部开发了一个代号为“project lens”的项目来替换 Zipkin UI。
现在 Zipkin 的使用案例很多,不同使用案例对应的架构也不相同。这并不是说用户没有直接采用 OpenZipkin 组织下面的项目。例如 Mediata 就在他们的局点文档中描述了他们直接使用 Zipkin 的发行版,没有进行任何修改。
Zipkin 项目缺省是支持中等规模的使用场景, 为了支持更大规模的使用场景,我们需要做些什么?
Adrian:大规模的使用场景意味着更多的数据量,大规模用户通常会从成本以及处理或清理数据的能力来考虑这个问题。例如,SoundCloud 实现了基于 kubernetes 元数据清理数据的工具。以往几乎所有 Zipkin 大型局点都将追踪数据存储在 Cassandra。现在,Netflix 等大型局点采用 Elasticsearch 也能取得成功。 几乎所有大型局点都使用 Kafka 来进行更大的数据传输。出于效率的原因,较小的站点会采用不同的传输方式。例如,Infostellar 使用 Armeria (一个类似于 gRPC 的异步效 RPC 库)来传输数据。
大多数成熟局点也会担心数据大小而使用采样的方式来解决问题。因为我们很难为不同类型的局点设计一个通用工具,Zipkin 为大家提供了多种采样选择,其中包括基于 http 请求的表达式来进行配置,也有新的开发客户端速率限制采样器。例如,使用 Spring 的局点有时会使用配置服务器实时推送采样率。这样可以在不干扰通常的低采样率的情况下抓取有趣的痕迹。
大多数局点使用客户端采样来避免启动无用的跟踪。例如,spring cloud sleuth 的默认策略不会为健康检查等管理流量创建跟踪。这些是通过 http 路径表达式完成的。一些基于百分比的采样(例如 1%或更少的流量)在数据激增时仍然存在问题。即使采样率为 1%,当流量达到 1000%的时候也可能会出现问题。因此,我们始终建议对系统进行冗余配置,也就是说不仅要为正常流量分配带宽和存储空间,还要提供一定的余量。但这不是一个最好的解决方案,我们开玩笑的将其称为 OPP (over-provision and pray,美国流行歌曲名),通过冗余保障还有祈祷来帮我们应对数据激增的问题。
值得注意的是许多局点站并不打算“演进”到自适应(自动)采样。例如,Yelp 在定制的无索引的廉价存储中进行 100%的数据消费。这样可以在不干扰通常的低采样率的情况下直接抓取有趣的痕迹。在 Zipkin 社区中有相关自适应采样配置的设计讨论,以突出问题区域而不会增加基本采样率的复杂性。自适应是一个有趣的选择,绝对可以应对数据激增问题,但大家通常会用不同的方法来实现自适应。

目前 Zipkin 在线局点日常处理 span 的数据流大概是多少? Zipkin 缺省能支持存储一个月的数据吗?在 Zipkin 的存储方面你有什么好的建议?
Adrian:Yelp 处理的 Span 数据可能是最多的,因为它们会将 100%的数据集中到专用存储群集中。但是他们也没有公布数字。Netflix 的系统大约会将 240 MB / 秒的 span 数据推送到后台(大家可以算算这里有多少条 span 信息),一般来说一条 Span 数据通常不会超过 1KiB,甚至远远低于 1KiB。
关于数据存储,大多数网站出于成本的考虑只保留数天的数据。不过有些用户自己提供“最喜欢的追踪”功能来长时间保留追踪数据。关于 Span 大小,我们建议大家使用 brave 或 zipkin-go 等工具中自带的默认值,然后根据大家的具体需求添加一些数据标签(决定是否保留数据)来提升资源利用率。
我们也不建议把 span 作为日志记录器。 OpenTracing 开了这个坏头,他们把日志工具和分布式追踪 API 相混淆,甚至在 Span 中的 API 定义了“microlog”。据我所知没有一个追踪系统能在系统内部把常规日志记录工作做得很好的,因为追踪系统和常规日志记录系统是两个完全不同的系统, 这样做只会损害追踪系统运行效率。
我们建议大家根据自己的需要选择最佳的存储方式。 例如,Infostellar 直接将追踪数据转发到 Google Stackdriver 上进行存储。 如果你更熟悉 Elasticsearch 而不是 Cassandra,那么请使用 Elasticsearch,反之亦然。 但是我们建议大家不要使用 MySQL,因为我们的 MySQL 架构不是为了高性能而编写的。
Zipkin 是如何对接分析系统(如 Amazon X-Ray, Apache SkyWalking 以及 Expedia HayStack)的?对此你有什么好的建议?
Adrian:你提到的所有项目都是通过接收 Zipkin 数据实现集成的,Infostellar 在这方面有比较好的网站文档可以参考。
Skywalking 也提供了接入 Zipkin 数据的集成方式。 Skywalking 可以接受 Zipkin 格式的数据,这样无论是 Zipkin 的探针,还是其他工具,如 Jaeger,只要使用相同格式的工具都可以接入到 Skywalking 中。需要指出的是现在很多追踪工具都支持 Zipkin 格式,通过支持 Zipkin 格式可以很容易完成对其他追踪系统的集成工作。
我对 Haystack 与 Zipkin 集成工作的有一定的了解。他们通过 Hotels.com 提供的 Pitchfork 这个工具,将数据分别发送给 Zipkin 和 Haystack。Haystack 的系统可以对 Zipkin 数据进行服务图聚合等处理,这样就不需要使用 Zipkin 的 UI 来处理数据了。
OpenZipkin 是什么?这些年 Zipkin 社区是怎么发展起来的?如何加入到 Zipkin 社区中?
Adrian:2015 年,社区有人呼吁把项目迁移到一个更开放的地方,以便更快地发展项目。我们经过三个月的努力,于 2015 年 7 月在 Github 上成立了“OpenZipkin”小组。社区在此之后快速发展,大量用户在社区中交流他们在构建分布式追踪系统所遇到的问题和挑战。当社区决定把首选语言定为 Java 而不是 Scala 后,我们重新编写了服务器。我们有许多示例项目帮助大家上手,而且我们认为与他人交流是最好的学习方式。如果你不熟悉追踪,最容易参与的方法就是参与到我们的 gitter 讨论中来。
Zipkin 最近加入 ASF 孵化器,这对于 Zipkin 来说意味着什么?
Adrian:Zipkin 发展了一段时间后,CNCF 联系我们加入,而我们考虑的是加入阿帕奇软件基金会(ASF) 或者什么也不加入。当时的社区看不到加入基金会的好处,我们当时选择了什么不加入基金会。然而,社区不断发展壮大,我们也有责任成长。特别是当我们通过 SkyWalking 的在 ASF 孵化对 ASF 有了更深入的了解。 因为基金会要求旗下项目站在厂商中立的角度来考虑问题的,这样可以帮助 Zipkin 站在社区的角度上考虑如何独立发展。ASF 的文化和我们也更匹配,因此 Zipkin 于今年 8 月份刚成为 Apache 孵化器项目。
作者简介
姜宁,华为开源能力中心技术专家,前红帽软件首席软件工程师,Apache 软件基金会 Member,有十余年企业级开源中间件开发经验,有丰富的 Java 开发和使用经验,函数式编程爱好者。从 2006 年开始一直从事 Apache 软基金会开源中间件项目的开发工作,先后参与 Apache CXF, Apache Camel,Apache ServiceMix,Apache ServiceComb 的开发。对微服务架构,WebServices,Enterprise Integration Pattern,SOA, OSGi 有比较深入的研究。
微博 ID:https://weibo.com/willemjiang
个人博客地址 :https://willemjiang.github.io/

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 1 条评论