

数据仓库、数据湖、HSAP 架构,包括 Flink 社区提的流批一体,它们到底能解决什么问题?今天将由阿里云研究员将业务问题抽丝剥茧,从技术维度娓娓道来:为什么你需要数据湖或者数据仓库解决方案?它的核心难点与核心问题在哪?如果想稳定落地,系统设计该怎么做?
一、业务背景
1.1 典型实时业务场景
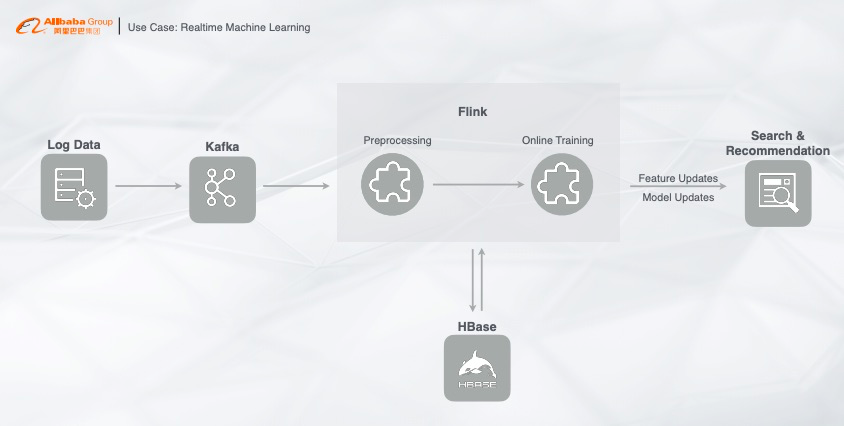
首先我们来看一个典型的实时业务场景,这个场景也是绝大部分实时计算用户的业务场景,整个链路也是一个典型的流计算架构:把用户的行为数据或者数据库同步的 Binlog,写入至 Kafka,再通过 Flink 做同步任务,订阅 Kafka 消费的实时数据。这个过程中需要做几件事情,比如 Preprocessing(预处理),在处理的过程中做 Online Training(在线训练),在线训练过程中需要关联一些维表或者特征,这些特征可能可以全量加载到计算节点里面去,也有可能非常大,就需要用 HBase 做一个高并发的点查,比如我们做一些样本也会写入到 HBase 中去,形成一个交互过程,最后实时产生的采样数据或者训练模型推到搜索引擎或者算法模块中。以上就是一个很典型的 Machine Learning 的完整链路。
1.2 越来越复杂的架构
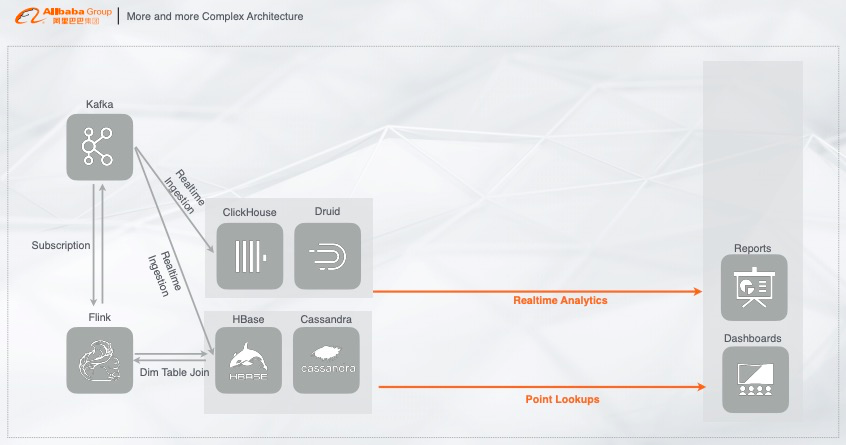
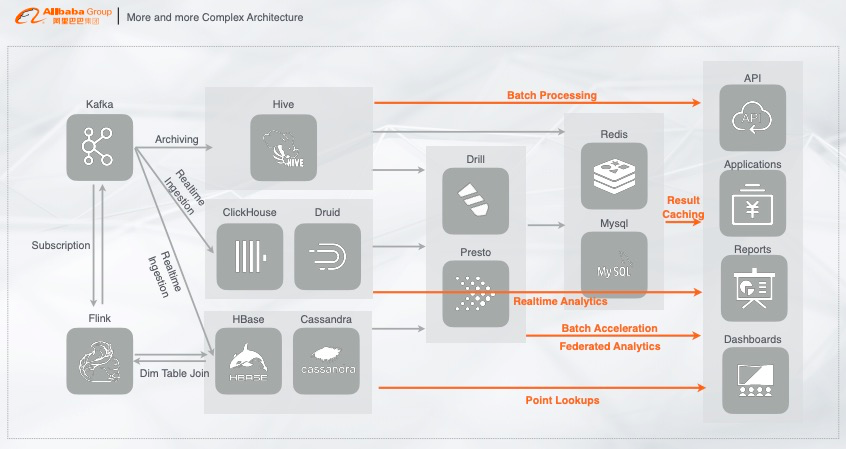
以上场景展示的链路与离线链路是相辅相成的,也有一些公司实时的链路还没有建立起来,用的是离线链路,不过这套链路已经是一个非常成熟的方案了。如果我们把这个链路变得更加复杂一些,看看会带来什么样的问题。首先我们把刚刚的链路做一个变化,实时数据写入 Kafka,再经过 Flink 做实时的机器学习或者指标计算,把结果写入到在线服务,例如 HBase 或者 Cassandra 用来做点查,再接入在线大盘,做指标的可视化展现。

这里面产生的一个问题就是:在线产生的数据和样本,如果想对它们做一个分析,基于 HBase 或者 Cassandra 的分析能力是非常弱的且性能是非常差的。
那么怎么办呢?
有聪明的开发者们可能就有一些实现方式如下:
HBase 或者 Cassandra 不满足分析需求,就把实时数据写入至适合数据分析的系统中,比如 ClickHouse 或者 Druid,这些都是典型的列存架构,能构建 index、或者通过向量化计算加速列式计算的分析,再对接分析软件,对数据做实时报表、实时分析展现等,以此链路来解决实时高效分析的问题。
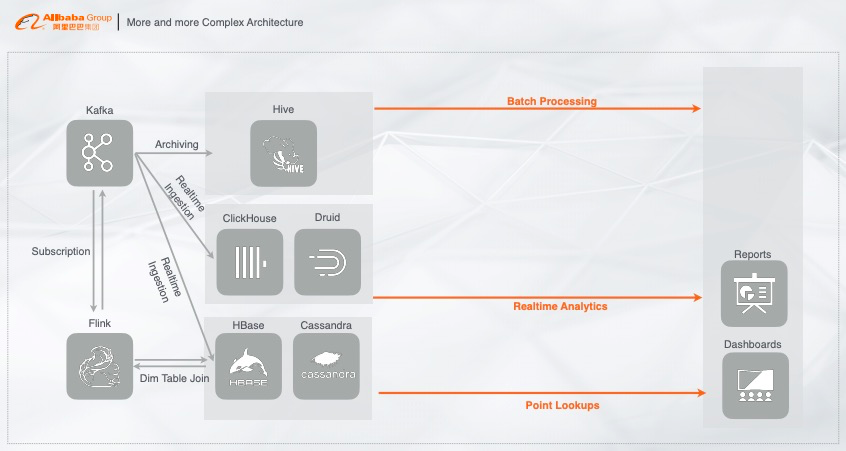
但上面的架构中,还有一些额外的需求,就是要将实时产生的数据数据归档至离线系统,对离线数据做一个基于历史的全量分析,基于此开发者们最常用的链路就是把实时数据离线的归档至 Hive 中,在 Hive 中做 T+1 天或者其他的离线算法。通过 Hive 对离线数据的处理来满足离线场景的需求。
但是业务既有实时写入的数据又有离线的数据,有时我们需要对实时数据和离线数据做一个联邦查询,那应该怎么办呢?
基于现市面上的开源体系,开发者们最常用的架构就是基于 Drill 或者 Presto,通过类似 MPP 的架构层做多数据的联邦查询,若是速度不够快,还能通过 Druid、ClickHouse 等做查询加速。
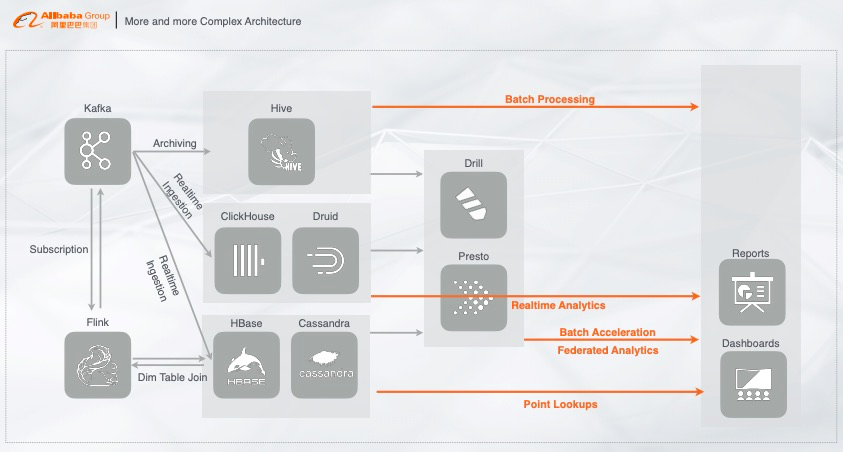
以上联邦查询的链路有个问题就是,QPS 很难上去,比如前端调用需要每秒钟几百上千的 QPS,如果几百上千的 QPS 全部通过加速层来做,那性能肯定是有所下降的,这时应该怎么办呢?最常见的解决方案就是在常见的加速层再加一个 cache,用来抵挡高并发的请求,一般是加 Redis 或者 MySQL 用来 cache 数据,这样就能提供 server 以及在线服务的能力。
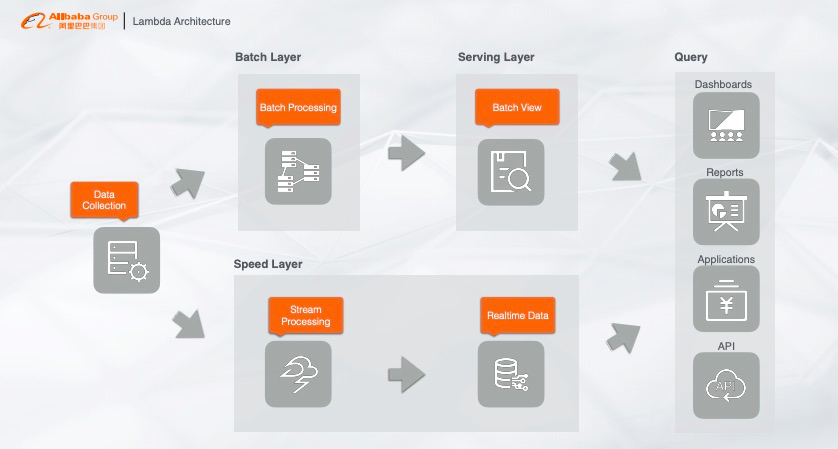
1.3 典型的大数据 Lambda 架构
以上就是绝大部分公司所使用的大数据架构,也有很多公司是根据业务场景选择了其中一部分架构,这样既有实时又有离线的大数据完整架构就搭建出来,看起来很完美,能实际解决问题,但是仔细想想,里面藏了很多坑,越往后做越举步维艰,那么问题在哪呢?现在我们来仔细看一下。
其实这套大数据方案本质上就是一个 Lambda 架构,原始数据都是一个源头,例如用户行为日志、Binlog 等,分别走了两条链路:一条是实时链路,也就是加速层(Speed Layer),通过流计算处理,把数据写入实时的存储系统;另一条链路就是离线链路,也就是批计算,最典型的就是将数据归档至 Hive,再通过查询层如 Spark 对数据做加速查询,最后再对接在线应用、大盘或者第三方 BI 工具。
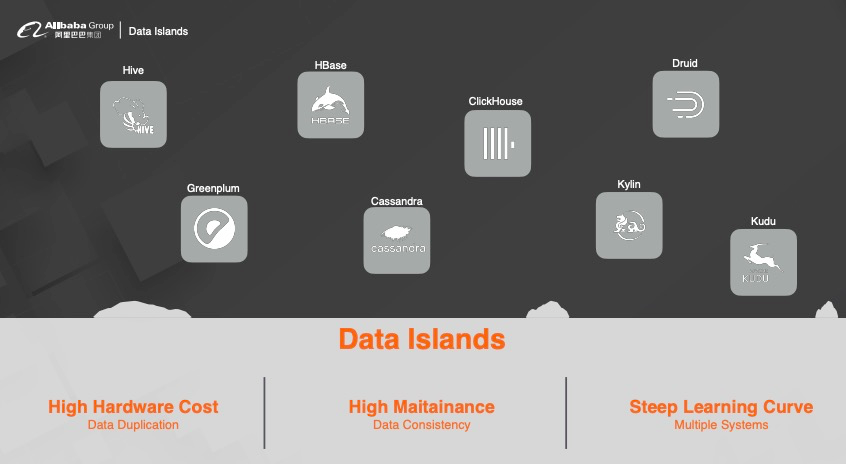
1.4 典型大数据架构的痛点
针对市面上这些开源产品,就存储而言,我们来逐一分析,这些产品是否都能具备满足业务需求的能力。
首先是基于离线存储的 Hive,其次是提供点查询能力的 HBase、Cassandra、然后是 MPP 架构号称能面向 HTAP 的 Greenplum、以及最新兴起的用于做快速分析的 Clickhouse 等等都是基于解决方案而面世的存储产品。
但以上的每个存储产品都是一个数据的孤岛,比如为了解决点查询的问题,数据需要在 HBase 里面存储一份;为了解决列存的快速分析,数据需要在 Druid 或者 Clickhouse 里面存一份;为了解决离线计算又需要在 Hive 里面存储一份,这样带来的问题就是:
1)冗余存储
数据将会存储在多个系统中,增加冗余存粗。
2)高维护成本
每个系统的数据格式不一致,数据需要做转换,增加维护成本,尤其是当业务到达一定量级时,维护成本剧增。
3)高学习成本
多个系统之前需要完全打通,不同的产品有不同的开发方式,尤其是针对新人来说,需要投入更多的精力去学习多种系统,增加学习成本。
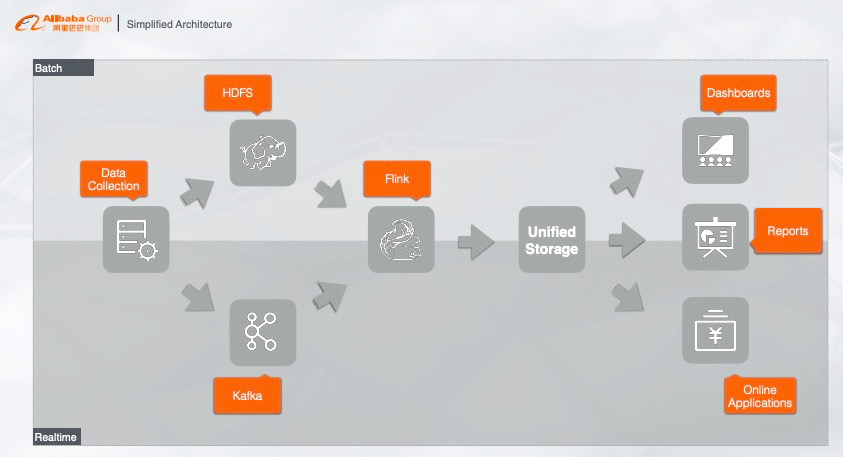
1.5 简化的大数据架构
面对这样一个无比冗余无比复杂的系统,我们应该怎么去解决这些问题呢?我们可以对 Lambda 架构做一个简化。其实业务的本质就是将数据源做一个实时处理或者离线处理(批处理),从业务场景出发,我们希望不管是实时数据还是离线数据,都能统一存储在一个存储系统里面,而且这个存储还必须要满足各种各样的业务需求。这样听起来很玄乎,感觉这个产品需要支持各种各种的场景,非常复杂。但是如果我们能把架构做成这样,将会非常完美,这样就从本质上解决了流批统一的计算问题,一套 SQL 既能做流计算又能做批计算,再深挖其底层原理,还解决了存储问题,流数据和批数据都统一存储在同一个产品。
二、看起来很完美的 Data Lakes
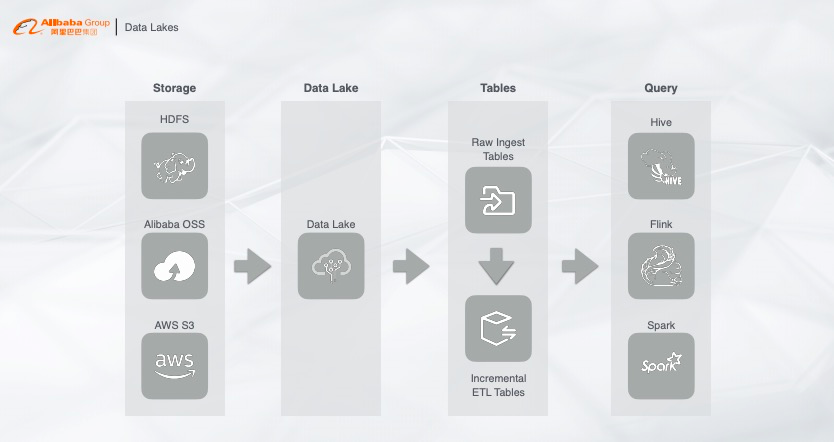
针对以上简化的架构,我们可以看看开源社区为了解决这些问题所推出的一些产品,例如 Data Lakes。
首先采集的数据有统一的存储,不管是 HDFS、OSS 还是 AWS,数据以增量的形式存储在数据湖里,再通过查询层不管是 Hive、Spark 还是 Flink,根据业务需求选择一个产品来做查询,这样实时数据以及离线数据都能直接查询。整个架构看起来很美好,但是实际问题在于:
1)数据增量写入不满足实时性
开源的实时写入并不是实时写入,而是增量写入。实时和增量的区别在于,实时写一条数据就能立马查询可见,但是增量为了提高吞吐会将数据一批一批的写入。那么这套方案就不能完全满足数据实时性的要求。
2)查询的 QPS
我们希望这个架构既能做实时分析,又能做流计算的维表查询,存储里面的数据能否通过 Flink 做一个高并发的查询,例如每秒钟支持上千万上亿 QPS 的查询?
3)查询的并发度
整个方案本质都是离线计算引擎,只能支持较低的并发,如果要支持每秒钟上千的并发,需要耗费大量的资源,增加成本。
综上所述,这个方案目前还不能完全解决问题,只能作为一个初期的解决方案。
三、HSAP 之我见
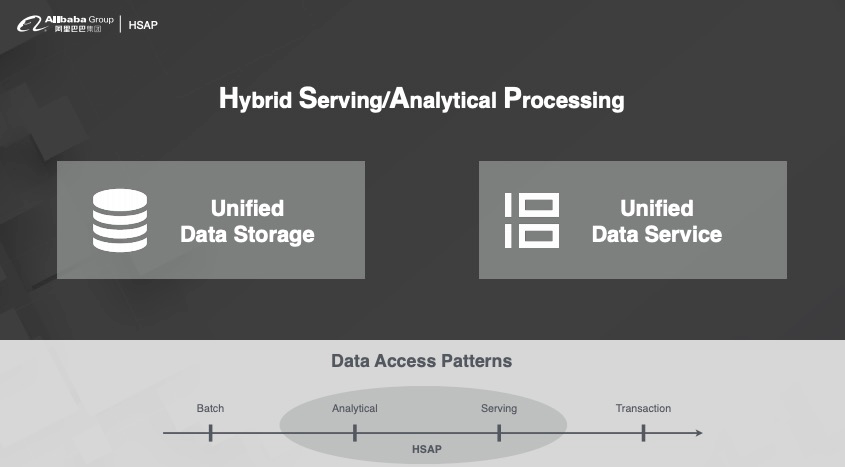
3.1 什么是 HSAP
针对以上问题我们做了一个细致的分析,大致根据查询并发度要求或者查询 Latency 要求,将 Patterns 分为四类:
Batch:离线计算
Analytical:交互式分析
Servering:高 QPS 的在线服务
Transaction:与钱相关的传统数据库(绝大多数业务并不需要)
目前市面上都在说 HTAP,经过我们调研 HTAP 是个伪命题,因为 A 和 T 的优化方向不一样。为了做 T,写入链路将非常复杂,QPS 无法满足需求。若是对 T 的要求降低一点,就会发现 Analytical 和 Severing 的联系非常紧密,这两块的技术是可以共用的,所以我们放弃了 T 就相当于放弃了 Transaction,于是我们提出新的一个架构叫做 HSAP,那我们需要做的就是把提供服务和分析的数据存储在一个系统里,通过一套分析引擎来做处理。
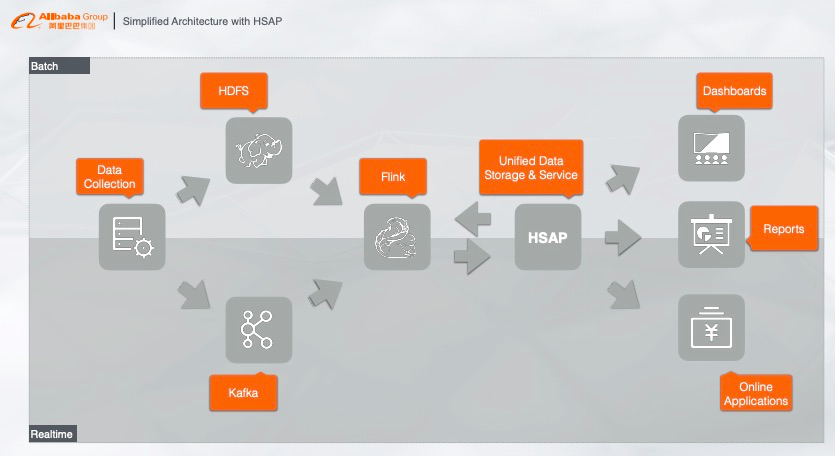
3.2 基于 HSAP 的大数据架构
HASP 系统接入到我们刚刚简化的架构中就成为非常的完美的大数据架构。HSAP 系统与 Flink 做维表关联,对离线数据做批处理,然后对接在线应用提供在线服务,例如报表、大盘等。
3.3 PostgreSQL 生态
那么接入 HSAP 系统之后,在线应用和系统怎么样来用呢?为了减少使用难度,就要引需要一个生态系统来做支撑,经过我们反复调研,我们认为是 PostgreSQL,主要有以下几点:
1)丰富的工具对接
PostgreSQL 具有非常完备的工具对接,不管是开发工具还是 BI 分析工具,都有着丰富的支撑能力。
2)详尽的文档支撑
通常来讲写文档需要耗费大量的时间,PostgreSQL 有着非常详尽的文档,如果能够直接复用 PostgreSQL 的文档,将会减少工作量。同时开发者们只需要根据 postgreSQL 文档来开发,减少学习成本。
3)多元化的扩展
PostgreSQL 有着非常多元化的扩展,例如地理信息的 PostGis,Matlab 等,开发者们可以根据业务需求选择对应的扩展。

四、新一代的实时交互式引擎——Hologres
基于以上所有内容,进入到我们今天的重点,也就是我们在阿里云重磅发布的新一代实时交互式引擎,中文名叫交互式分析,英文名叫 Hologres。Hologres 这个名字怎么来的呢?Hologres 由 Holographic(全息宇宙)和 Postgres 组成。

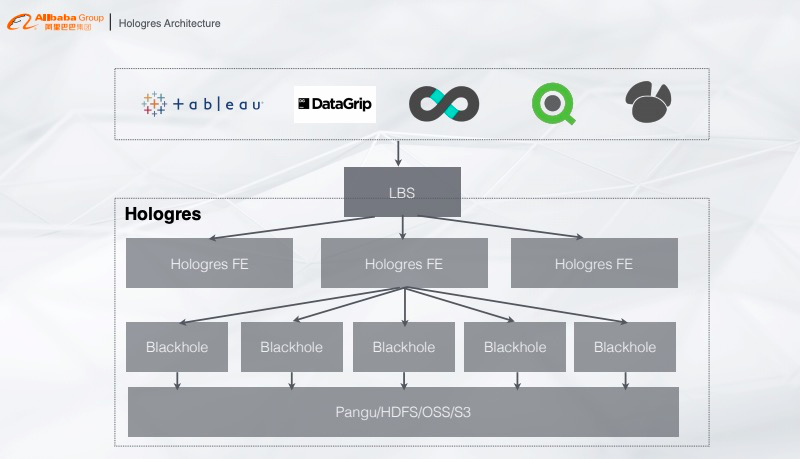
4.1 Hologres 的架构
Hologres 的架构比较简单,从下往上看,最底层是统一的存储系统,可以是阿里云统一的 Pangu、业务的 HDFS 或者 OSS、S3 等,存储上面是计算层,提供类似的 MMP 架构计算服务,再往上是 FE 层,根据查询信息将 Plan 分发到各个计算节点,再往上就是 PostgreSQL 生态的对接,只要有 JDBC/ODBC Driver 就能对 Hologres 做查询。
4.2 Hologres:云原生
1)存储计算分离
Hologres 的架构是完全是存储计算分离,计算完全部署在 K8s 上,存储可以使用共享存储,可以根据业务需求选择 HDFS 或者云上的 OSS,这样用户就能根据业务需求对资源做弹性扩缩容,完美解决资源不够带来的并发问题。
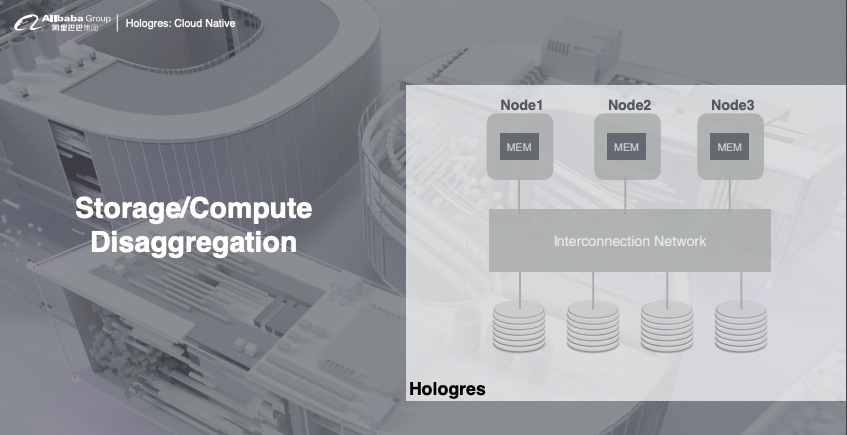
2)存储优势
全异步:支持高并发写入,能够将 CPU 最大化利用;
无锁:写入能力随资源线性扩展,直到将 CPU 全部写满;
内存管理:提供数据 cache,支持高并发查询。

3)计算优势
高性能混合负载:慢查询和快查询混合一起跑,通过内部的调度系统,避免慢查询影响快查询;
向量化计算:列式数据通过向量化计算达到查询加速的能力;
存储优化:能够定制查询引擎,但是对存储在 Hologres 数据查询性能会更优。

4.3 基于 Hologres 的典型应用
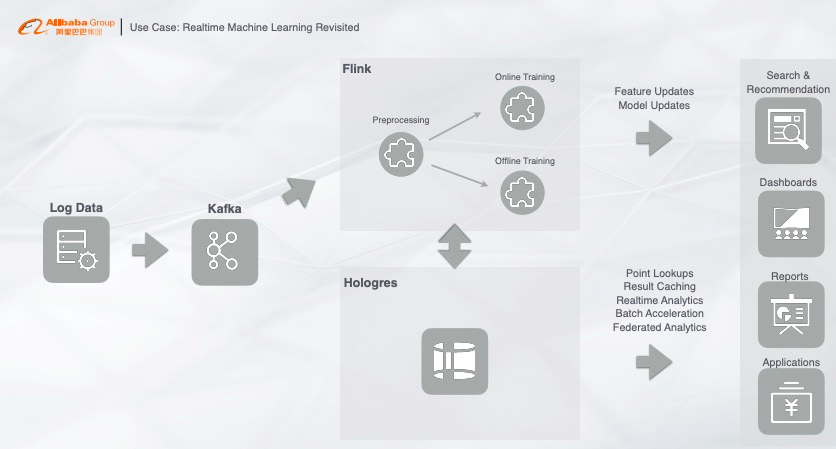
下面给大家介绍一下,Hologres 在阿里巴巴内部的一个典型应用。
数据实时写入至 Flink,经由 Flink 做实时预处理,比如实时 ETL 或者实时训练,把处理的结果直接写入 Hologres,Hologres 提供维表关联点查、结果缓存、复杂实时交互、离线查询和联邦查询等,这样整个业务系统只需要通过 Hologres 来做唯一的数据入口,在线系统可以通过 PostgreSQL 生态在 Hologres 中访问数据,无需对接其他系统,这样也能解决之前架构的各种查询、存储问题。
4.4 真正的实时数仓:Flink+Hologres
综上所述,我们认为,真正的实时数仓只需要 Flink+Hologres 即可,Flink 做流、批数据的 ETL 处理,将处理的数据写入 Hologres 做统一的存储和查询,这样业务端直接对接 Hologres 提供在线服务。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 5 条评论