

一、平民数据科学的发展
Gartner 在罗列企业组织在 2019 年需要探究的十大战略性技术趋势时,指出“平民数据科学”会使其主要职责不是从事统计和分析工作的用户能够从数据中获取预测性和规范性的洞察力。Gartner 将平民数据科学家(citizen data scientist)定义为创建或生成模型的人,这些模型运用高级诊断分析,或者具有预测性功能。不过这些人的基本工作职能却是在统计和分析领域之外。Gartner 认为机器学习相关专家的缺乏以及行业实践的缺乏是企业应用机器学习等技术的主要障碍,平民数据科学家能够执行在以前需要更多的专业知识才可以进行的复杂分析,这使他们能够完成高级分析,而无需具备数据科学家们应具备的高级技能,这将极大降低企业将机器学习运营到实际业务中的门槛。(注一)
二、企业落地机器学习项目的流程和难点
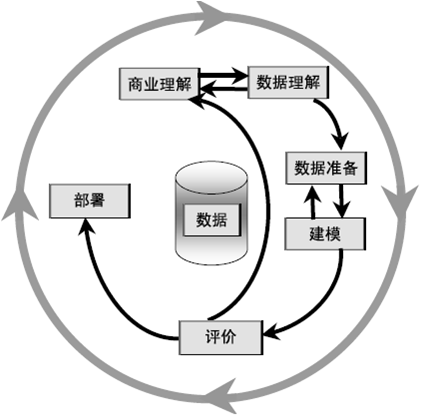
业内较为常见的规划流程是 CRISP-DM,这个流程确定了一个数据挖掘项目的生命周期。CRISP-DM 是 Cross-Industry Standard Process for Data Mining 的缩写,也就是数据挖掘的跨行业标准流程,是一个已被业界证明的有效指南。CRISP-DM 提供了对数据挖掘生命周期的一个概览。这个生命周期模型包含了六个阶段,模型里的箭头指明了各阶段间最重要和频繁的依赖项。大多数项目在需要的时候,会在各阶段之间来回反复。(注二)
2.1 业务理解
确定商业目标,发现影响结果的重要因素,从商业角度描绘客户的首要目标,查找所有的资源、局限、设想以及在确定数据分析目标和项目方案时考虑到的各种其他的因素,接下来确定数据挖掘的目标,制定项目计划。
2.2 数据理解
数据理解阶段开始于数据的收集工作。接下来就是熟悉数据的工作,具体如:检测数据的量,对数据有初步的理解,探测数据中比较有趣的数据子集,进而形成对潜在信息的假设。收集原始数据,对数据进行装载,描绘数据,并且探索数据特征,进行简单的特征统计,检验数据的质量,包括数据的完整性和正确性,缺失值的填补等。
2.3 数据准备
数据准备阶段涵盖了从原始粗糙数据中构建最终数据集(将作为建模工具的分析对象)的全部工作。
2.4 建模
在这一阶段,会选择和使用各种各样的建模方法,并反复评估模型将其参数将被校准为最为理想的值。一般包括模型选择,测试设计,模型参数设置(调参),模型评估等步骤,并经常会返回到数据准备阶段。
2.5 评估
从数据分析的角度考虑,在这一阶段中,已经建立了一个或多个高质量的模型。但在进行最终的模型部署之前,更加彻底的评估模型,回顾在构建模型过程中所执行的每一个步骤,是非常重要的,这样可以确保这些模型是否达到了企业的目标。
2.6 部署
获得的知识需要便于用户使用的方式重新组织和展现。根据需求,这个阶段可以产生简单的报告,或是实现一个比较复杂的、可重复的实现过程。
在上述的流程中,对于很多没有太多机器学习应用经验的企业来说,业务理解部分往往是最难的,例如一个中等规模的餐饮连锁企业在有了 30 多家门店后,想开始客流量预测/销量预测的,应该如何下手?
在确定了业务目标后,后面的数据理解、数据准备、建模阶段,也并不容易,或是效率不高,如何整合企业内多种数据源的数据,如何进行数据的准备,如何进行模型的选择,如何进行高效的训练,都需要各类的专业人员进行支撑,对于普通的企业依然不容易实现。
有了模型,如何大规模的、快速部署到生产环境,对企业依然是个挑战。
三、平民化数据科学和机器学习平台-KNIME
针对上述问题,AWS 一直致力于帮助企业实现”数据平民化”和”数据科学家平民化”,降低企业落地机器学习的门槛,比如在 2018 年 11 月推出了 Amazon Forecast ,这是一项完全托管的服务,可以让使用者无需构建、培训或部署机器学习模型,只需要提供历史数据,以及您认为可能会影响预测结果的任何其他数据就可以进行时间序列预测,类似的还有个性化推荐服务 Amazon Personalize。同时 Amazon SageMaker 为每位开发人员和数据科学家提供快速构建、训练和部署机器学习模型的能力。
为了进一步覆盖更多的应用场景,AWS 也和合作伙伴一起提供可以覆盖更多行业应用场景的软件并提供行业最佳实践。下面介绍的就是 AWS 合作伙伴 KNIME(knime.com)的数据科学和机器学习平台。在 Gartner 2019 年数据科学和机器学习平台魔力象限的报告中,KNIME 处于强势领导地位。

Gartner 2019 Magic Quadrant for Data Science and Machine Learning Platforms (发布于 2018.11)
KNIME 通过其模块化的数据流水线概念集成了机器学习和数据挖掘的各种组件。图形化用户界面和 JDBC 的使用允许混合不同数据源的节点的组装,包括预处理(ETL:提取、转换、加载),用于建模、数据分析和可视化,几乎不需要编程;并且 KNIME 将常用的机器学习应用场景按照行业进行了分类,并提供了数据流模板,用户只需要具备业务常识和一些基本的统计知识,就可以按照说明一步步操作得到结果。比如下面这个制造或零售行业中库存优化的应用(注三):

更多应用说明可以访问:
https://www.knime.com/solutions(官方提供8个行业的模板)
https://nodepit.com/(目前有2151个工作流和3857个节点模板)
KNIME 提供开源的 KNIME Analytics Platform 以及企业级的 KNIME Server,这两款软件在 AWS Marker Place 上可以找到,并和 AWS 的服务有很好的集成,可以方便的连接到 AWS 上的数据源,例如 AWS RDS MySQL, PostgreSQL, and SQL Server,或是 Redshift 数据仓库,或是 Athena 查询 S3 上的数据,或是直接访问 S3,还可以通过”Big Data Connectors”访问 AWS EMR 上的 Hive 或 Impala,或通过” Extension for Apache Spark” 调用 Spark 平台资源进行执行机器学习操作。
在这个系列的第一篇中,将以 Kaggle 上”泰坦尼克号幸存预测”为向大家介绍使用 KNIME 的平台搭建一个数据处理工作流。后续将陆续介绍 KNIME 平台与 AWS 托管服务的结合以及企业环境的部署。
四、快速搭建机器学习工作流
4.1 软件安装
KNIME Analytics Platform 可以运行在 Windows、Linux、Mac 平台,为了快速安装并后续调用 AWS 服务,此处选择从 AWS marketplace 安装,操作系统为 Windows,也可从 KNIME 网站自行下载安装;
进入 AWS marketplace 中,选择 KNIME Analytics Platform for AWS,点击订阅
选择软件版本和部署区域,这里软件版本推荐选择次新的 3.7.2 版
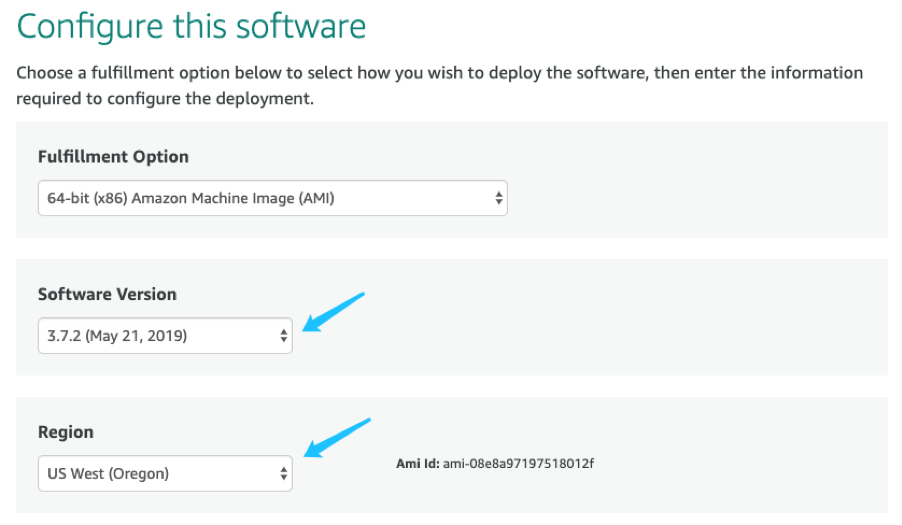
进入安装配置界面,选择实例类型,这里选择了”M5.Xlarge”

VPC、子网、安全组等网络配置默认或根据需要选择。选择或新建自己的”密钥对”

之后,进入控制台,通过 Windows 远程桌面进入部署好的 KNIME Analytics Platform,步骤参考:
https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/WindowsGuide/connecting_to_windows_instance.html

4.2 软件界面介绍

进入 KNIME Analytics Platform 后,可以看到如上界面,其中节点(Node)是任何数据操作的基本处理点。节点库中有常用各种处理的节点,可以覆盖绝大部分需要的处理。
工作流(Workflow):工作流是你在平台上完成特定任务的步骤或操作的序列。首先可以查看官方的工作流样例。

4.3 案例介绍
1912 年 4 月 10 日,泰坦尼克号展开首航,也是唯一一次载客出航,它是从南安普敦出发的,最终的目的地为纽约。除了约 908 名船员外(男性船员 885 名,女性船员 23 名),还有乘客约 1316 人,分布在不同的仓位(头等、二等、三等),泰坦尼克号在中途碰撞冰山后沉没。2224 名船上人员中有 1514 人罹难。
Kaggle 是世界上最大的数据科学家以及机器学习爱好者的社区,他经常会举行很多数据比赛,吸引众多从业者以及爱好者参加,它的入门练习比赛就是分析这次船难的数据,通过机器学习得到一个模型,预测哪些人是幸存者。因为哪些人存活下来已经成为了一个事实,所以这个比赛提供一部分的船上人员的数据去构建模型,去预测另外一部分船上人员的存活情况,并与事实进行对比,来验证构建出来模型的准确性。
详情可访问:https://www.kaggle.com/c/titanic
4.4 工作流搭建
首先设置本地工作路径,设置好后,开始搭建”泰坦尼克号幸存预测”的工作流,这个预测是根据乘客信息来判断乘客是否能生存下来;按照机器学习的通用步骤,工作流包括数据读取、数据处理、模型训练与测试、模型评价等步骤。
首先从https://www.kaggle.com/c/titanic/data下载数据,包括训练数据和测试数据。

4.4.1 读取数据
原始数据是以 CSV 文件提供的,train.csv , 共有 891 行,12 列,各列的解释如下:
从节点库中查找”CSV Reader”,读取 train.csv,(不要选择‘Has Row Header’) 。
右键点击节点,下拉菜单中选择”Execute”,之后点击”File table”可以看到下表。

4.4.2 数据处理
数据处理包括删除无关列、数据转换、缺失值处理三个环节。

删除无关列
由于乘客 ID(PassengerId)和主题无关,因此删除,选择”Column filter”节点,并用拖拽箭头,将”CSV Reader”输出和”Column filter”输入连接。
点击”Configure”–Column filter,将 ID 删除。

数据类型转换
在原始数据中,”Survived”和”Pclass”是分类数据,但却是数字的形式,需要转变为”String Value”。加入”Column Rename”节点,并将”Survived”和”Pclass”的数据类型修改为”String Value”。

之后用可视化工具对数据进行探索,详见 3.4.3 数据可视化
处理缺失数据
在实际工作中,缺失数据的处理是个很大的工程,在本案例中,没有做过多探索,而直接选择简单的方法进行处理,用某些值来填充缺失的值,而不去删除某些行,常见的填充方法有:中位数、平均值、最常见值等方法。这里用”平均值(Mean)”填充缺失的数据值(Age、Fare),用”最常见值(Most Frequency Value)”填充分类数据(Cabin、Embarked)。

4.4.3 数据可视化
数据可视化在数据处理的过程中非常重要,KNIME 提供了多种可视化的节点,可以帮助我们发现数据的关系、理解要处理的问题。例如统计图表、散点图、相关性矩阵、箱线图、直方图等,篇幅问题,这里只列出了染色和箱线图。
将数据转换后的数据引入各个可视化节点即可。

数据统计信息
进一步,用 Statistics 节点观察数据,数值数据和分类数据在不同的标签下,数值数据提供最小值、最大值、中值、均值、标准差、峰度、偏度以及分布情况。
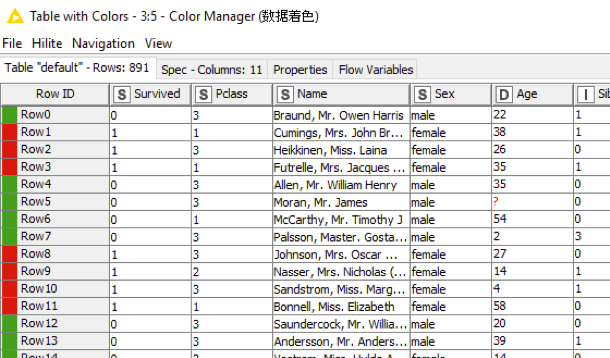
数据染色
将数据用彩色的方式展现,这里对”Survived”进行染色,并进行观察。点击”Configure”之后”Table with color”

箱线图
箱线图可以粗略的查看数据是否具有有对称性,分布的分散程度等信息。从数据转换节点引入数据,点击”View Box Plot”,在左图中发现各个数据范围不一样导致”SibSp(登船的兄弟姐妹及配偶人数)”和”Parch(登船的父母及子女的人数)”看不清楚,这时可以显示归一处理后的数据,如右图,在”Appearance”下选择”Normalize”。


还可以用条件箱线图查看各个数据在不同条件下的状态,例如查看票价和生存的关系,从下图可以看出存活的人持有的票价高。

4.4.4 模型训练和测试
这部分在如下部分实现,具体流程如下图所示:

首先将数据划分为训练集和测试集,然后进行逻辑回归的训练,最后使用训练好的模型和测试数据进行预测。还可以选择”决策树”、”支持向量机”等方法进行预测,KNIME 都提供对应的节点。
选择”Partitioning”节点,从缺失值处理节点引入数据,这里设置训练集占已有数据的 80%,测试数据占 20%,在选择时使用随机选择的方法。

之后将”Logistic Regression Learner”连接到数据划分后的输出,并进行设置。

目标”Target column”设置为”Survived”,”Reference category”设置为 0,为简化分析将 Cabin、Ticket、Name 等排除。
“Logistic Regression Predictor”连接到”Logistic Regression Learner”以及”数据划分”的测试数据输出,需要设置的是将计算出来的概率附加在数据表中,以供计算 ROC 时使用。
4.4.5 模型优化
模型优化可在模型的评价构建完成后进行,以便于对比。
设置优化求解算法
Solver 优化求解算法提供 IRLS(iterative reweighted least squares,迭代加权最小二乘法)和 AG(stochastic average gradient,随机平均梯度法)两种选择,由于 IRLS 不支持正则化,故在这里选择 SAG,更多说明可参考注四),也可自行对两种算法的预测效果进行对比,花费不会超过 10 分钟,这个案例里面 SAG 的预测准确率稍微高一些。

设置结束标准
在 Advanced 菜单栏,设置”Maximal number of epochs”最大运行周期数,分别设置为 10000,100000,观察结果;
“Learning rate Strategy”,默认设置为”Fixed”,如果没有严格梯度下降,则降低学习率。
设置”Regularization”即正则化设置,Uniform 是不设置正则化,还可以设置 Gauss(高斯)和 Laplace(拉普拉斯)正则化。

4.4.6 模型评价
选择”ROC Curve”,首先选择“真实值”,之后选择预测的概率

得到 ROC 值为 0.8941,说明预测效果不错。
另外,通过”Scorer”节点,进行设置,执行后再选择“View : Confusion Matrix”观察混淆矩阵。可以看出正确率为 81.006%。


4.4.7 提交结果到 Kaggle
感兴趣的同学可以继续,否则可以忽略,这不是机器学习的一部分。
需要按照 Kaggle 的要求输出结果,基本上是之前流程的复制,只是需要对输出的结果进行整理,包括在“整理”节点将“Prediction(Survived)“重新命名为“Survived”并转换数据类型。

之后将数据写入 CSV 文件后上传。

可以看到通过 2 小时左右的拖拉拽,1 个小时左右的参数调整,就可以完成这个作业。
4.4.8 工作流整理及输出
整个项目的工作流如下,可以将工作流导出分享给别人,KNIME Server 也提供机制和权限控制来实现工作流在企业内的安全分享。

五、总结
本篇文章向大家展示了一个平民化数据科学和机器学习平台-KNIME 的基本使用,可以看出 KNIME 是一个可以让机器学习能力快速在企业落地并将企业数据转化为价值的工具。“够用即可”,KNIME 的最大价值并不是他简单、易用的平台,而是他目前已经具备的覆盖各个行业应用常见的工作流,这些工作流可以指导用户一步一步的将数据处理进行下去,最后得到想要的结果。并且有很多 KNIME 的合作伙伴还在不断的开发、共享更多的工作流。如果需要更强大、功能更丰富的平台,可以选择 Amazon SageMaker ,SageMaker 是一项完全托管的服务,覆盖了整个机器学习工作流程,对于这些用户 KNIME 平台可以作为一个开发快速原型的工具,快速的验证机器学习的想法是否可行。
AWS 也在和 KNIME 一起努力为 KNIME 的平台提供稳定、运算力强大的基础设施支持、实现更多的节点扩展支持,后续也会逐步向大家介绍 KNIME 与 AWS 各种数据服务的结合以及企业级平台的部署。
六、参考文档:
注一:https://blogs.gartner.com/carlie-idoine/2018/05/13/citizen-data-scientists-and-why-they-matter/
注二:https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_data_mining
注三:https://www.knime.com/solutions/innovation-notes/inventory-optimization-offline
作者简介:
本文转载自 AWS 技术博客。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论