

本文要点
Apache Spark 的流框架(Structured Streaming)为数据流带来了 SQL 查询功能,让用户可以实时、可扩展地处理数据。
Redis 流(Redis Stream)是 Redis 5.0 新引入的数据结构,能够以亚毫秒级的延迟高速收集、保存和分发数据。
用户集成 Redis 流和流框架后就能简化连续应用程序(continuous application)的扩展工作。
开源的 Spark-Redis 库将 Apache Spark 与 Redis 连接起来。该库为 Redis 数据结构提供 RDD 和数据帧 API,使用户可以将 Redis 流用作流框架的数据源。
流框架是 Apache Spark 2.0 新引入的一项功能,在业界和数据工程社区中引起了很大关注。流框架 API 构建于 Spark SQL 引擎之上,为流数据提供类似 SQL 的界面。
早期的 Apache Spark 以微批处理方式处理流框架查询,延迟大约为 100 毫秒。
去年的 2.3 版本引入了低延迟(1 毫秒)的“连续处理”,进一步推动了流框架的应用。
为了让 Spark 保持高速的连续处理状态,你需要使用像 Redis 这样的高速流数据库来支持它。
Redis 开源内存数据库以其高速度和亚毫秒级延迟闻名于世。最近 Redis 5.0 新推出了一种名为 Redis 流的数据结构,使 Redis 能够在多个生产者和消费者之间消费、保存和分发流数据。
现在的问题是,将 Redis 流作为流数据库,Apache Spark 作为数据处理引擎,两者共同部署,怎样才能做到最佳搭配?
用 Scala 编写的Spark-Redis库就集成了 Apache Spark 和 Redis,使用它可以:
在 Redis 中以 RDD 的形式读写数据
在 Redis 中以数据帧的形式读写数据(例如,它允许将 Spark SQL 表映射到 Redis 数据结构)
使用 Redis 流作为流框架的数据源
在流框架之后将 Redis 实现为接收器
本文中我将介绍一个真实场景,并指导你如何使用 Redis 和 Apache Spark 实时处理流数据。
模拟场景:计算实时点击
假设我们是一家广告公司,在热门网站上投放广告。我们根据社交媒体上的热门图片制作包含流行话题梗的动图,并将其作为广告投放出去。为了最大化利润,我们必须识别出能获得病毒式传播或赢得更多点击次数的资产,这样就能加大它们的投放力度了。
我们的大部分资产传播期很短,所以能实时处理点击的话,我们就能快速生成传播趋势图,这对业务至关重要。我们理想中的流数据解决方案必须记录所有广告点击并实时处理,然后计算每项资产的实时点击次数。以下是设计思路:
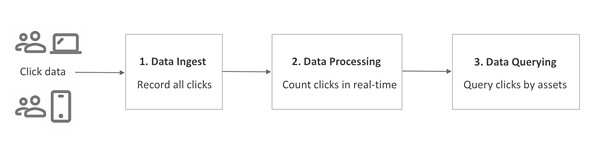
图 1 实时计算点击次数的流程示意
输入
对于每次点击,我们的数据提取方案(图 1 中的方框 1)将资产 ID 和广告费用放在 Redis 流中:
例如:
输出
在图 1 中的方框 2 部分处理数据之后,我们的结果会存储在数据存储区中。数据查询方案(图 1 中的方框 3)为数据提供了一个 SQL 接口,我们可以用它查询最近几分钟的最高点击次数:
构建解决方案
现在我们已经定义好了业务需求,接下来探讨如何使用 Redis 5.0 和 Apache Spark 2.4 构建其解决方案。在本文中我用的是 Scala 编程语言,但你也可以在 Java 或 Python 中使用 Spark-Redis 库。
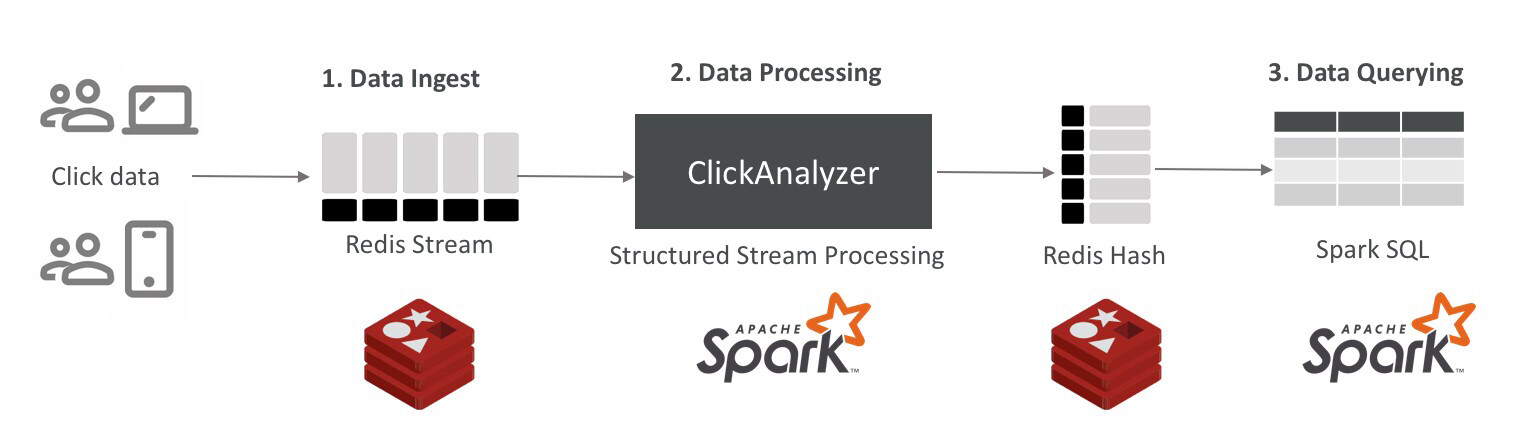
图 2 解决方案架构
这张流程图看起来非常简单:首先系统将数据提取到 Redis 流,然后 Redis 流将数据作为 Spark 进程消费,并将结果聚合传回 Redis,最后使用 Spark-SQL 接口在 Redis 中查询结果。
数据提取:我选择用 Redis 流提取数据,因为它是 Redis 中的内置数据结构,每秒可处理超过一百万次读写操作。此外它还可以根据时间自动对数据排序,并支持简化数据读取方式的消费者组。Spark-Redis 库支持将 Redis 流作为数据源,因此它完全符合我们对流式数据库使用 Apache Spark 引擎的需求。
数据处理:Apache Spark 中的流框架 API 是我们处理数据的绝佳选择,而 Spark-Redis 库使我们能够将到达 Redis 流的数据转换为数据帧。使用流框架时,我们可以用微批处理或 Spark 的连续处理模式运行查询。我们还可以开发一个自定义的“编写器”来将数据写入指定目的地。如图 2 所示,我们将使用哈希数据结构将输出写入 Redis。
数据查询:Spark-Redis 库允许你将本机 Redis 数据结构映射为数据帧。我们可以声明一个将列映射到哈希数据结构特定键的“临时表”,并且由于 Redis 的速度非常快,延迟在亚毫秒级别,我们可以使用 Spark-SQL 获得实时查询能力。
之后我将逐个介绍如何开发并运行解决方案的各个组件。在那之前,我们先用适当的工具来初始化开发环境。
寻找合适的开发工具
在我们的示例中,我们将使用 Homebrew 包管理器在 macOS 上下载和安装软件,你也可以根据你操作系统的情况选择其他包管理器。
Redis 5.0或更高版本:首先,我们需要在环境中下载并安装 Redis 5.x。旧版本的 Redis 不支持 Redis 流。
在 Homebrew 上,我们用下面的命令安装并启动 Redis 5.0:
如果你用的还是旧版 Redis,可以用下面的命令升级它:
Apacke Spark 2.3或更高版本:接下来我们从官方网站下载并安装 Apache Spark,或者使用 Homebrew 安装:
Scala 2.12.8或更高版本:Scala 也是一样的操作:
Apache Maven:我们需要用 Maven 来构建 Spark-Redis 库。
JDK 1.8或更高版本:我们可以使用下面的命令从甲骨文网站或 Homebrew 下载并安装这个 JDK。对于最新版本的 JDK,我们需要用 java 替换 java8。
Spark-Redis库:这是我们解决方案的核心部分,这里从 GitHub 下载库并构建软件包,如下所示:
这会在./target/目录下加入 spark-redis-<version>-jar-with-dependencies.jar。在我的设置中这个文件是 spark-redis-2.3.1-SNAPSHOT-jar-with-dependencies.jar
SBT 1.2.8或更高版本:SBT 是一个 Scala 构建工具,可简化管理和构建 Scala 文件的工作。
开发环境:最后该设置文件夹结构并构建文件了。本示例中我们将把程序代码放在“scala”目录下。
使用以下内容创建一个新文件 build.sbt:
初始化目录。用以下命令初始化包目录:
将spark-redis-<version>-jar-with-dependencies.jar复制到 lib 目录。
构建我们的点击计数解决方案
如架构部分所述,我们的解决方案包含三个部分:数据提取组件、Spark 引擎内的数据处理器和数据查询接口。在本节中我将详细说明这三个部分并组合出一个有效的解决方案。
提取 Redis 流
Redis 流是一种仅附加数据结构。假设 Apache Spark 的连续处理单元将消费这些数据,我们可以将消息数限制为一百万。稍微修改一下前面提到的命令:
大多数流行的 Redis 客户端都支持 Redis 流,因此根据你的编程语言,你可以选择适用 Python 的 redis-py、适用 Java 的 Jedis 或 Lettuce、适用 Node.js 的 node-redis 等等。
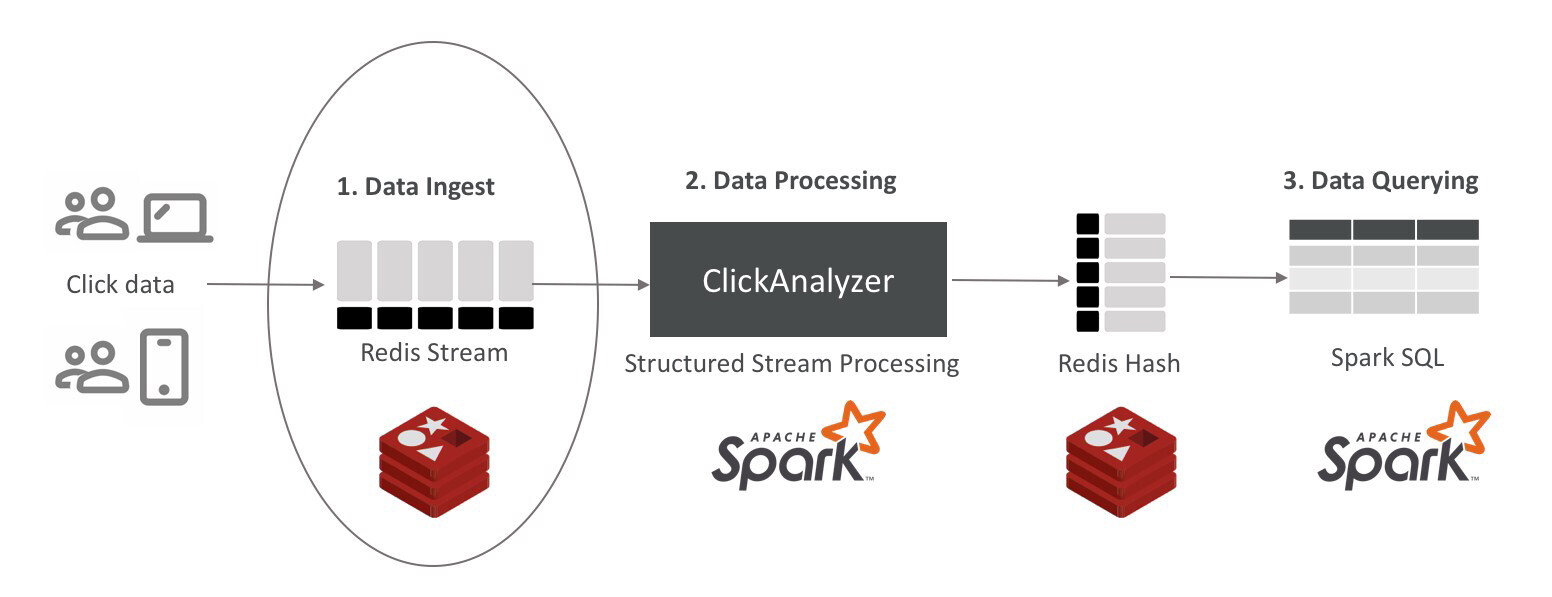
图 3 数据提取
数据处理
这一部分分为三个小节:
从 Redis 流读取和处理数据
将结果存储在 Redis 中
运行程序
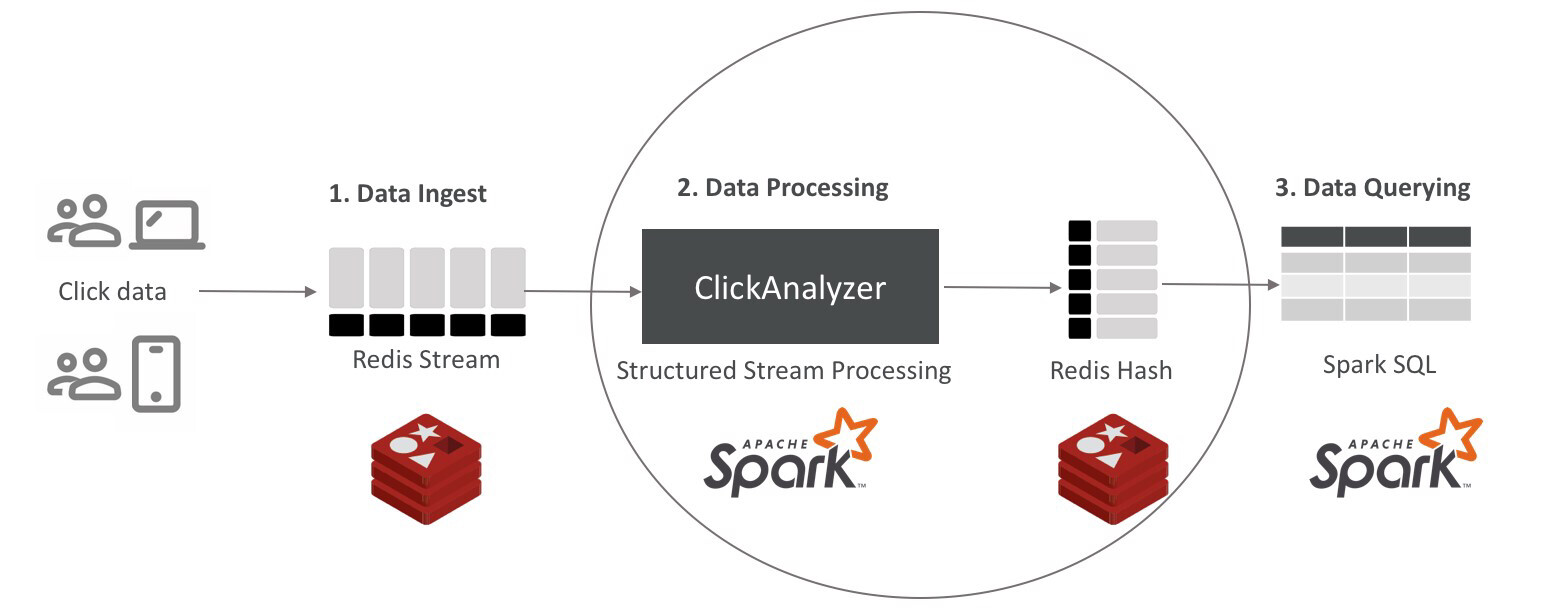
图4.数据处理
从 Redis 流读取数据
要在 Spark 中从 Redis 流读取数据,我们需要明白怎样连接到 Redis,以及 Redis 流中数据的 Schema 结构。
为了连接到 Redis,我们必须为 Redis 创建一个带有连接参数的新 Spark 会话(SparkSession):
设置 Schema 结构时,我们用“clicks”命名流,并为“stream.keys”设置一个“clicks”的选项。由于每个流元素都包含一项资产以及与之相关的成本,因此我们将创建一个包含两个 StructField 的数组的 StructType——一个用于“asset”,另一个用于“cost”,如下所示:
在第一个程序中我们对每个资产的点击次数感兴趣。为此创建一个数据帧,其中包含按资产计数分组的数据:
最后一步是启动流框架查询:
注意这里我们使用自己的ForeachWriter将结果写回 Redis。如果要将输出转到控制台,可以将查询写成:
对于连续处理而言,我们希望在查询中添加’trigger’命令:.trigger(Trigger.Continuous(“1 second”))。trigger 命令不适用于聚合查询,因此我们无法把它插入这个示例。
下面是完整的程序代码。它会从 Redis 流读取新的点击数据并使用 Spark 的流框架 API 处理。如果你想在自己的环境中尝试,请将程序保存在 src/main/scala 下,命名为 ClickAnalysis.scala。(如果你的 Redis 服务器不是在端口 6379 上本地运行的,请根据具体情况设置连接参数。)
将结果存储在 Redis 中
为了将结果写回 Redis,我们可以开发一个名为 ClickForeachWriter 的自定义 ForeachWriter。它会扩展 ForeachWriter,并使用 Redis 的 Java 客户端 Jedis 连接到 Redis 上。下面是完整的程序代码,保存为 ClickForeachWriter.scala:
在这部分程序中有一点需要注意:它将结果存储在哈希数据结构中,其键遵循语法“click:”。我将在本文的最后一节中将此结构转换成数据帧来使用。另一点需要指出的是键的过期时间是完全可选的。上面展示了如何在每次点击被记录时让键的寿命延长五分钟(300 秒)。
运行程序
在我们运行之前首先需要编译程序。转到主目录(我们存储 build.sbt 的目录)运行命令:
我们的程序应该能顺利编译通过,没有错误。如果出现了错误,请修复它们并重新运行 sbt 包。编译完成后,在同一目录中运行以下命令来启动程序:
如果你不喜欢调试消息,可以停止程序(按 ctrl 加 c)并编辑/usr/local/Cellar/apache-spark/2.4.0/libexec/conf/(或 log4j.properties 文件存储的目录)下的 log4j.properties,并将 log4j.rootCategory 更改为 WARN,如下所示:
该程序将自动从 Redis 流中提取消息。如果 Redis 流中没有消息,它将异步侦听新消息。我们可以在新的控制台中启动 redis-cli 并向 Redis 流添加一条消息,以测试它是否在正常消费消息:
一切顺利的话,我们应该能在哈希数据结构中读取结果:
查询数据:将 Redis 数据读取为数据帧
我们解决方案的最后一个组件实际上为 Redis 数据提供了一个 SQL 接口。通过 SQL 命令读取数据又是一个两步过程:首先,我们为 Redis 数据定义 SQL schema;其次,我们运行 SQL 命令。
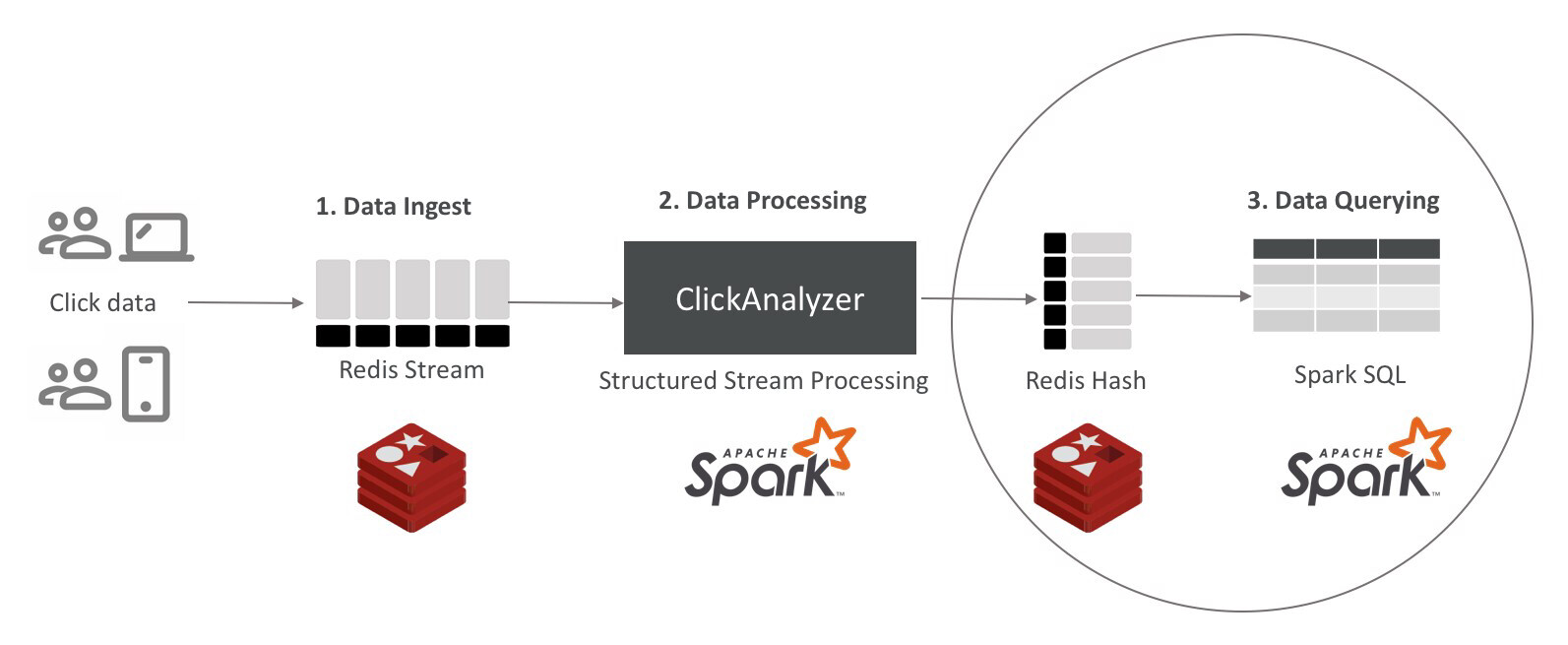
图 5 数据查询
但在此之前,我们需要从主目录上在控制台运行 spark-sql,如下所示:
然后会转到 spark-sql 提示符下:
现在我们要为 Redis 哈希数据结构中存储的数据定义 SQL schema。如前所述,我们将每个资产的数据存储在由键:click:表示的哈希数据结构中。哈希结构中还有一个键:count。创建 schema 并将其映射到 Redis 哈希数据结构的命令是:
此命令创建一个名为“clicks”的新表视图。它使用 Spark-Redis 库中指定的指令将“asset”和“count”列映射到哈希结构中的对应字段。现在我们可以运行查询:
如果要以编程方式运行 SQL 查询,请参阅 Apache Spark 提供的有关如何使用 ODBC/JDBC 驱动程序连接到 Spark 引擎的文档。
我们的成果是什么?
在本文中,我演示了如何使用 Redis 流作为 Apache Spark 引擎的数据源,介绍了 Redis 流是怎样为流框架用例提供支持的。我还展示了如何使用 Apache Spark 中的数据帧 API 读取 Redis 数据,并融合流框架和数据帧的理念说明了 Spark-Redis 库可以实现的功能。
Redis 流简化了高速收集和分发数据的任务。将其与 Apache Spark 中的流框架相结合,可以支持需要实时计算的各种解决方案,包括物联网、欺诈检测、人工智能和机器学习、实时分析等。
作者介绍
Roshan Kumar 是 Redis Labs 的高级产品经理。他在软件开发和技术领域的产品管理方面拥有丰富的经验。他曾在惠普公司和一些成功的硅谷创业公司工作。他拥有计算机科学学士学位和美国加利福尼亚州圣克拉拉大学的 MBA 学位。
查看英文原文:Real-Time Data Processing Using Redis Streams and Apache Spark Structured Streaming
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论