

图数据库是现在许多现代用例的绝佳解决方案:欺诈检测、知识图、资产管理、推荐引擎、物联网、权限管理……凡你想得起的,都有图数据库的“身影”。
所有这些项目都得益于能够快速分析高度连接的数据点及其关系的数据库技术——而快速图数据库就是为这些任务而设计的。
但是,当涉及到“流行行话警报”可扩展性方面时,图数据库的性质带来了挑战。那么,为什么会出现这种情况?图数据库是否具有扩展的能力?让我们来看看这些问题。
接下来,我们将定义“扩展”的含义,深入研究可能阻碍图数据库扩展的两个挑战,并讨论当前可用的解决方案。
什么是“图数据库的可扩展性”
让我们快速定义一下这里所说的可扩展的含义,因为可扩展并不是“仅仅”将更多的数据放在一台机器上或者将其放在不同的机器上。在处理大型或不断增长的数据集时,你所需要的也是一个可以接受的查询性能。
因此,这里真正的问题是:当数据集在一台机器上增长甚至超过其能力时,图数据库是否还能够提供可接受的性能?
你可能会问,为什么这是一个首先要问的问题呢?如果是这样,请阅读下面关于图数据库的快速回顾。如果你已经知道超节点和网络跃点等问题,请跳过快速回顾。
关于图数据库的快速回顾
简而言之,图数据库存储无模式的对象(顶点或节点),其中可以存储任意数据(属性)和对象之间的关系(边)。边通常有从一个对象指向另一个对象的方向。顶点和边形成一个数据点网络,称为“图”。
在离散数学中,图被定义为顶点和边的集合。在计算机领域中,它被认为是一种抽象的数据类型,擅长于表示连接或关系,不像关系数据库系统的表格数据结构,具有讽刺意味的是,它在表示关系方面非常有限。
如上所述,图由节点(即顶点(V))通过关系(即边(E))连接而成。

顶点可以有任意数量的边,并形成任意深度(即路径长度)的路径。
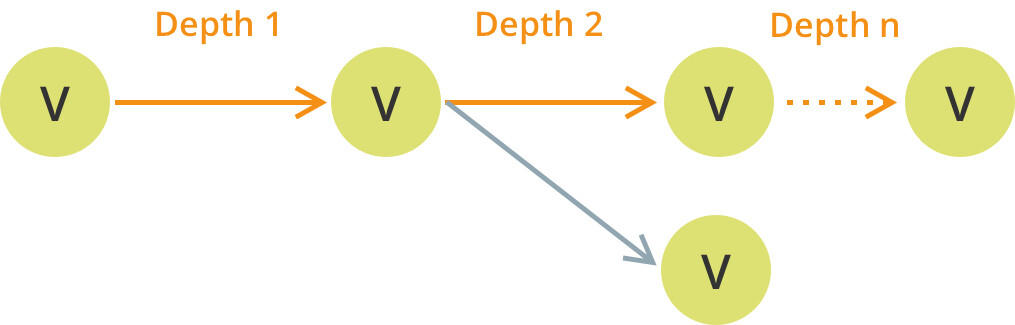
从一个银行账户到另一个银行账户的金融交易用例也可以建模为一个图,看起来类似于下面的模式。在这里,你可以将银行账户定义为节点,将其他关系中的银行交易定义为边。
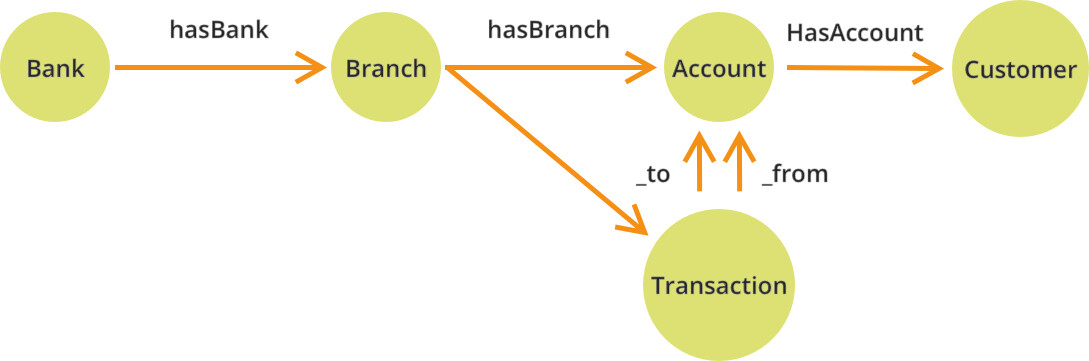
以这种方式存储账户和交易将使我们能够遍历所创建的未知或不同深度的图。要是在关系数据库中编写和运行这样的查询,往往是一项复杂的工作。(旁注:若使用多模型数据库,我们还可以使用连接查询将银行与其分支机构之间的关系建模为一个简单的关系,使用连接进行查询。)
图数据库提供各种算法来查询存储数据、分析关系。算法可以包括遍历、模式匹配、最短路径或分布式图处理(如社区检测、连接组件或中心性)。
大多数算法都有一个共同点,那就是超节点和网络跃点问题的本质。算法通过边从一个节点遍历到另一个节点。
在快速回顾之后,让我们深入讨论这些挑战。首先是名人。
以名人为例
如上所述,顶点或节点可以具有任意数量的边。超节点问题的一个典型例子就是社交网络中的名人。超节点是图数据集中具有异常多的传入或传出边的节点。
例如,Partick Stewart 爵士的 Twitter 账户,目前粉丝就超过 340 万。
如果我们现在将账户和推文建模为一个图,并遍历数据集,我们可能必须遍历 Partrick Stewart 的账户,遍历算法将不得不分析所有指向 Stewart 账户的 340 万条边。这将大大增加查询执行时间,甚至可能超过可接受的限制。类似的问题也可以在欺诈检测(有许多交易的账户)、网络管理(大型 IP 集线器)和其他案例中发现。
超节点是图的固有问题,对所有的图数据库都提出了挑战。但是有两种方法可以将超节点的影响降至最低。
选项 1:拆分超级节点
更准确地说,我们可以复制节点“Patricia Stewart”,并通过某个属性(如粉丝来自的国家或其他形式的分组)来分割大量的边。因此,我们尽量减少超节点对遍历性能的影响,以便在我们想要执行的查询中使用这些分组。
选项 2:以顶点为中心的索引
有关某人何时开始关注的日期/时间信息
粉丝来自哪个国家
粉丝的粉丝计数
等等
所有这些属性都可以提供有效使用以顶点为中心的索引所需的选择性。
然后,查询引擎可以使用索引来减少执行遍历所需的线性查找次数。同样的方法也可以使用,例如欺诈检测。在这里,金融交易作为边,我们可以使用交易日期或金额来实现高选择性。
在某些情况下,使用上述选项是不合适的,在遍历超节点时必须忍受一定程度的性能下降。但是,在大多数情况下,仍有一些选项可以优化性能。但是还有另一个挑战,就是大多数图数据库还没有解决这一问题。
网络跃点问题:如果对其拆分,就得付出代价
首先快速回顾一下。我们有一个高度连接的数据集,需要遍历它。在单个实例上,查询所需的所有数据都驻留在加载到主内存中的同一台机器上。一次主内存查找大约需要 100 纳秒。
现在,让我们假设我们的数据集超出了单个实例的能力,或者我们想要集群的高可用性,或额外的处理能力……或者,像往常一样,所有的一切。
在图的情况下,分片意味着拆分以前连接的内容,而我们的图遍历所需的数据现在可能驻留在不同的机器上。这就给我们的查询带来了网络延迟。我这知道网络可能不是开发人员的问题,但查询性能确实是开发人员的问题。
即使在位于同一机架上的现代 Gbit 网络和服务器上,通过网络进行查找也比通过内存查找要贵上 5000 倍左右。在连接集群服务器的网络上增加一点负载,甚至可能会获得不可预测的性能。
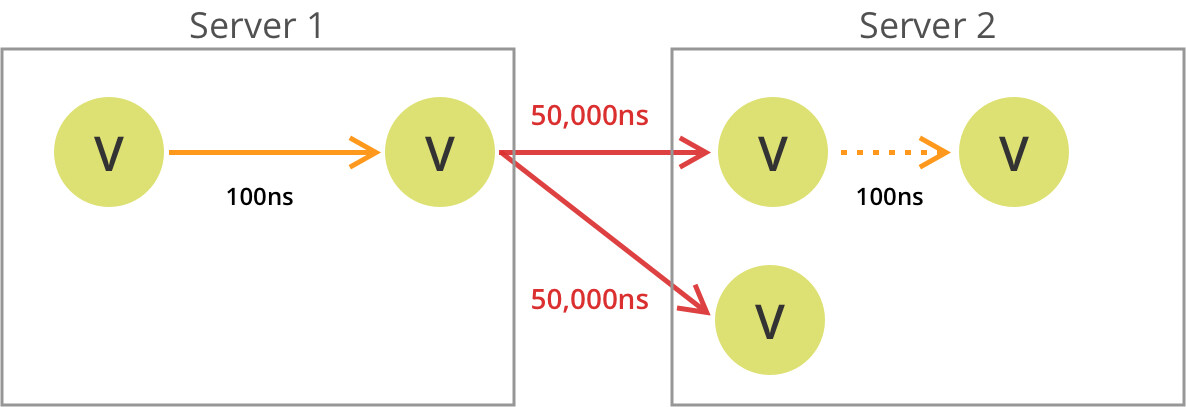
在这种情况下,遍历可能数据库服务器 1 开始,然后到达这样的一个节点,这个节点的边指向存储在数据库服务器 2 上的顶点,从而导致通过网络进行查找——网络跃点。
如果我们知道要考虑更多现实世界的用例,那么在单个遍历查询期间可能会有多个跃点。
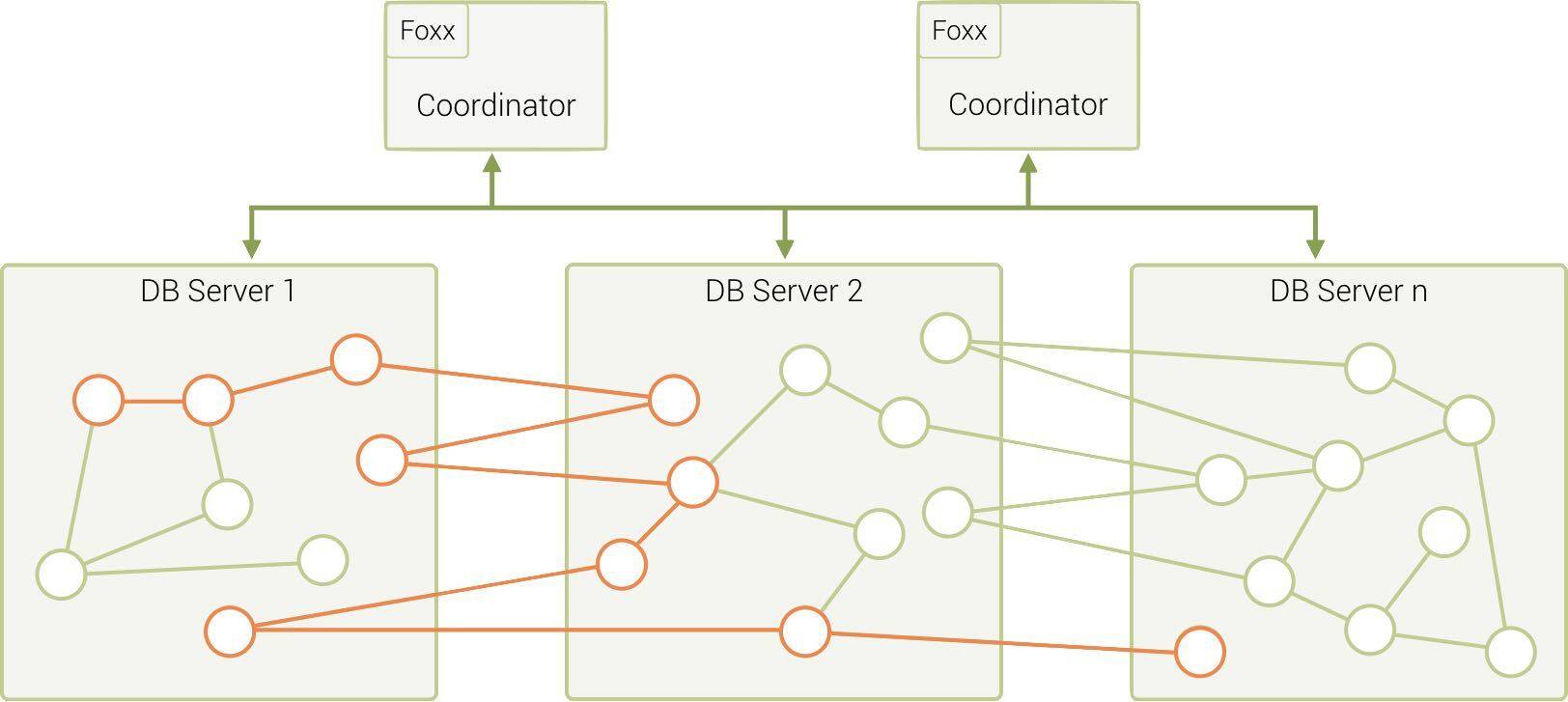
在欺诈检测、IT 网络管理,甚至现代企业身份和访问管理用例中,可能需要分发图数据,同时仍然必须以亚秒级的性能执行查询。查询执行期间的多个网络跃点可能会危及这一需求,从而为扩展付出高昂的代价。
更明智的解决问题方法
在大多数情况下,你已经掌握了一些关于数据的知识,我们可以用这些知识以一种聪慧的方式(客户 ID、区域等)对图进行分片。在其他情况下,我们可以使用分布式图分析,通过使用社区检测算法,例如 ArangoDB 的 Pregel Suite,为你计算这个领域的知识。
现在,我们可以进行一次快速的思维实验。假设我们有一个欺诈检测用例,需要分析金融交易来识别欺诈模式。我们从过去了解到,诈骗分子大部分时间都会利用某些国家或地区的银行来洗钱(你可以在 OASIS 上试一下真正的欺诈检测查询,只需在注册后按照入门指南进行即可)。
我们可以使用这些领域知识作为我们图数据集的分片键,在数据库服务器 1 上分配这个区域执行的所有金融交易,并在其他服务器上分配其他交易。
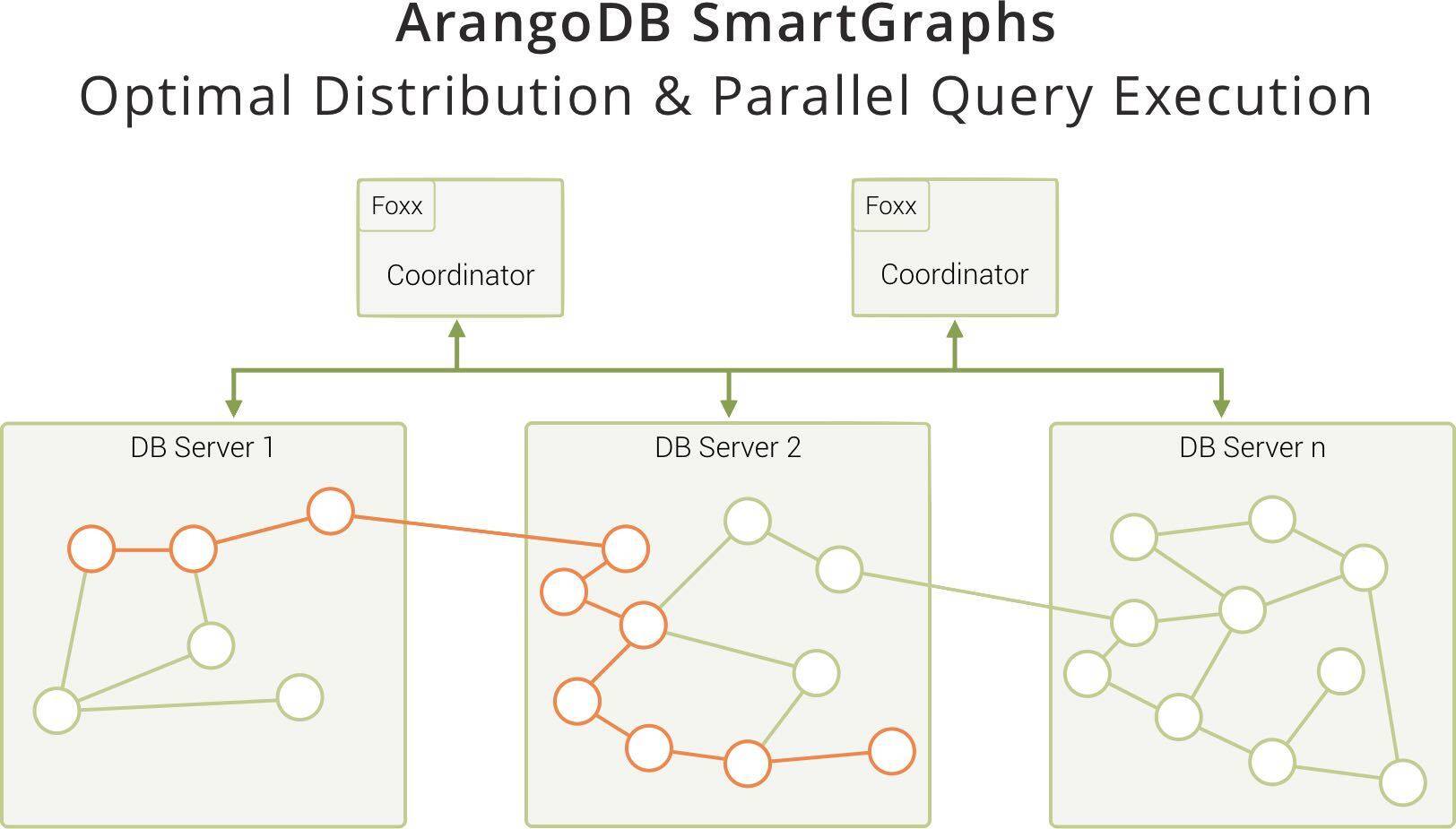
现在,你可以利用 ArangoDB 的 SmartGraph 特性在本地执行反洗钱或其他图查询,从而避免或者至少极大地减少查询执行期间所需的网络跃点。“不错啊,但是要怎么做呢?”你可能会问。
ArangoDB 中的查询引擎知道图遍历过程中所需的数据存储在哪里,将查询发送到每个数据服务器的查询引擎,并在本地并行处理请求。然后,每个数据库服务器上结果的不同部分将在协调器上合并并发送到客户端。通过这种方法,SmartGraph 可以实现接近单个实例的性能特征。
如果你有一个相当层次化的图,那么还可以利用 Disjoint SmartGraph 来更好地优化查询。
我也想提出网络跃点问题的其他解决方案,但据我所知,目前并没有其他解决方案。
结论
在不断增长的数据中寻找答案的需求日益增长,这就需要一个可扩展的解决方案。图技术越来越多地被用来回答这些复杂的问题或其中的部分问题。
我认为我们现在可以有把握地说,图数据库有垂直扩展的选择,但对于 ArangoDB 来说,也有水平扩展的选择。可以肯定的是,在边的某些情况下,以顶点为中心的索引或 SmartGraph 无法解决问题,但这种情况往往非常罕见。
原文链接:
https://dzone.com/articles/do-graph-databases-scale
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


加V:busulishang4668

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论