

语言可解释性工具(Language Interpretability Tool,LIT)是 Google PAIR 研发的用于自然语言处理模型的可视化、交互式模型理解工具。通过基于浏览器的用户界面,LIT 支持各种调试工作流。本文是语言可解释性工具(Language Interpretability Tool,LIT)的用户指南。
运行 LIT
有关如何启动自己的 LIT 实例的详细信息,请参阅开发指南。
总体布局
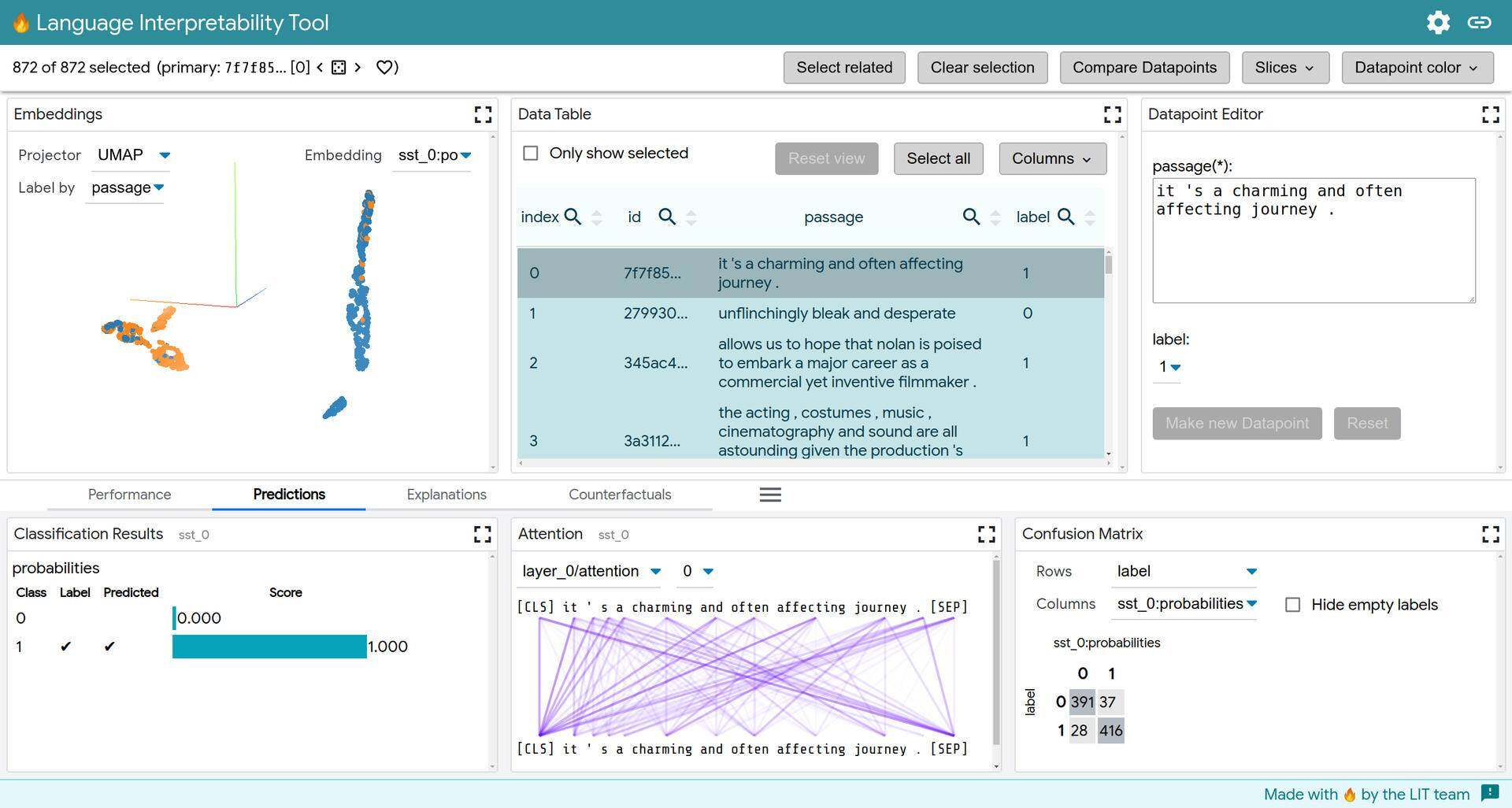
LIT 位于一个单页的 Web 应用程序中,由多个工具栏和一个由单独模块组成的主要部分构成。如果模块适用于当前的模型和数据集,则将自动显示;例如,仅当模型返回MulticlassPreds时,显示分类结果的模块才会显示。有关更多详细信息,请参阅开发指南。
一般来说,模块布局由两个部分组成,即顶部和底部,由可拖动的分隔器来控制每个部分的高度。顶部包含一组模块,始终在工具中显示。这一部分通常用于对工具导航至关重要的主要模块,例如数据表(Data Table)和数据点编辑器(Datapoint Editor)。底部由包含任意数量的单个模块的选项卡组成。这一部分的选项卡通常按特定于任务的模块集进行分组。
数据点选择
LIT 显示加载的数据集及其跨选定模型集的模型结果。用户可以通过从数据集中选择数据点来深入了解详细的结果。
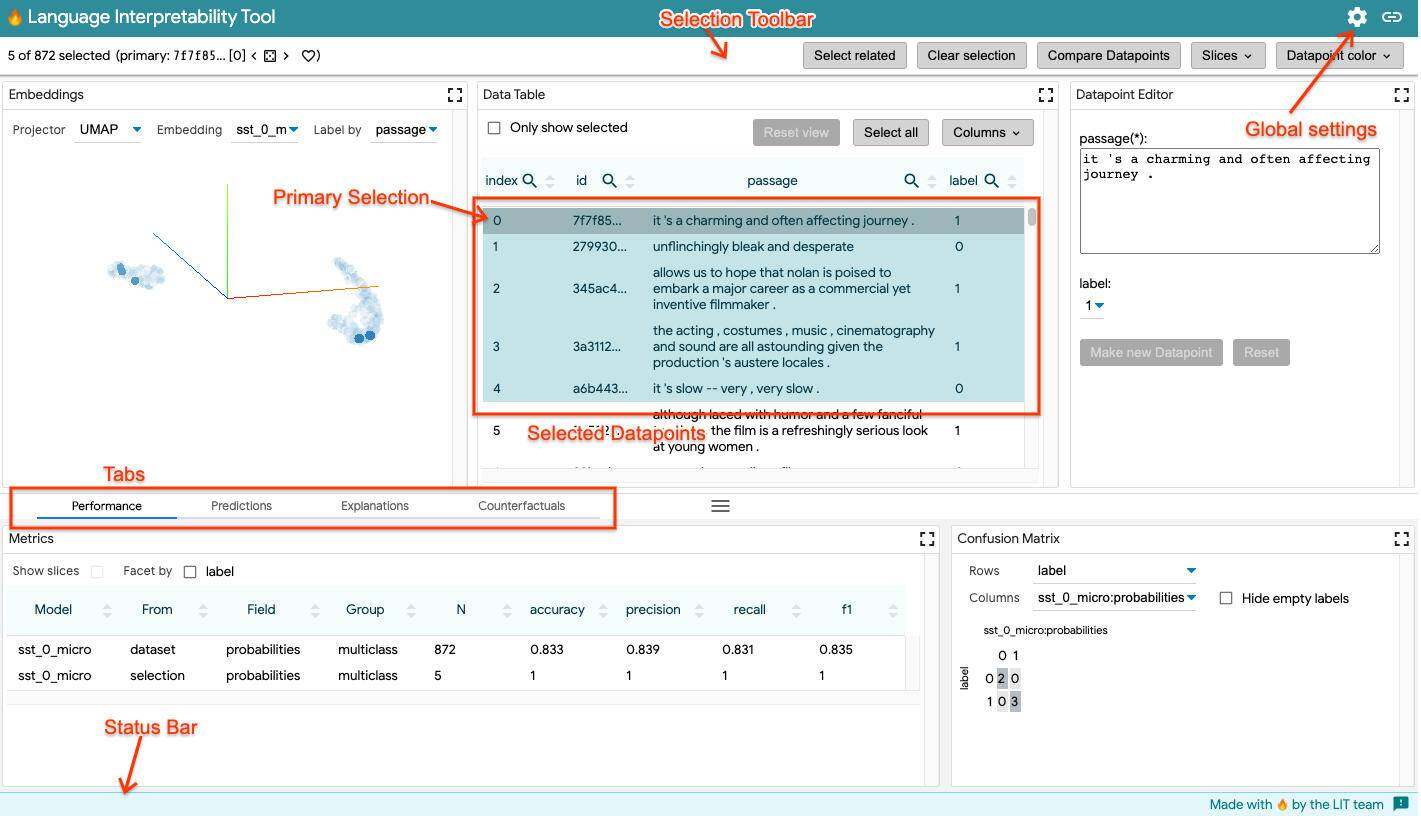
LIT 用户需要注意两个选择概念。第一个概念是当前选择,它由一个或多个数据点组成,这些数据点是通过一个交互模块(如 Data Table、Embedding、Prediction Score 或 Confusion Matrix 模块)选择的。当在模块中选择一组数据点时,这种选择与选择工具栏一起反映在所有其他模块中。例如,Metrics 模块不仅显示了整个数据集的模型度量,还显示了当前选择的数据点的模型度量。
第二个概念是主选择。主选择是当前选择中的单个数据点,在侧重于单一数据点的模块(如 Datapoint Editor 和 Salience Maps 模块)中对其进行更详细的研究。如果当前选择仅包含单个数据点,那么该数据点也是主选择。如果当前选择包含多个数据点,主选择默认为该选择中的第一个数据点,但可以通过选择工具栏中的箭头控件或单击选择中的另一个数据点来更改。在 Data Table 模块中,主选择以深蓝色突出显示,其 ID 显示在选择工具栏中。
可以通过选择工具栏将数据点的选择保存为 “切片”(slice)。将选择另存为一个切片,可以在将来轻松地导航回该选择。它还允许跨数据点的子集比较度量,如Metric 模块部分所述。
工具栏
LIT 中有三个工具栏。顶部工具栏包括工具名称和设置按钮,下面的选择工具栏,以及页面底部的状态栏。
全局设置
可以通过顶部工具栏中的设置图标打开全局设置对话框。
LIT 可以与一组模型和数据集一起启动。设置界面允许用户选择要分析的模型。可以对任意数量的模型进行分析,假设它们在使用的数据格式中兼容(即可以一起分析两个不同的毒性分类器以进行比较)。一旦选择一个或多个模型,就可以从与这些模型兼容的数据集中进行选择。
设置对话框还包含用于隐藏任何模块的控件。当分析不需要 LIT 包含的所有兼容模块时,这可以帮助整理用户界面。
最后,设置对话框包含用于保存和加载附加数据点的控件。如本指南后面所述(1和2),可以使用 LIT 通过手工编辑或者通过一些数据点生成器来创建新的数据点。如果要保存这些新数据点以便在 LIT 之外使用,或者在其他使用期间加载到 LIT,可以提供一个目录来保存数据点,然后单击 “Save new datapoints” 按钮。对话框将显示新数据点的位置,以及其中有多少个数据点。
要将这些保存的数据点加载到 LIT 会话中,只需提供相同的路径并单击 “Load new datapoints” 即可。
选择工具栏
选择工具栏位于顶部工具栏的正下方,它包含许多不同的控件和信息。在工具栏的左侧,它显示加载的数据集中有多少个数据点,以及当前有多少个数据点被选中。显示主选择数据点的 ID,以及一个用于将此数据点标记为收藏的收藏按钮。被收藏的数据点存储在自动创建的 “Favorites”(收藏夹)切片中,可以在切片控件中访问。如果只选择一个数据点,那么工具栏中的左右箭头按钮允许在加载的数据集中循环选中所选的数据点。如果当前选择的是一组数据点,那么左右箭头按钮将空值哪些数据点是主选择的数据点,并在当前选择的数据点之间循环选中所选的。箭头之间的 “Random”(随机)按钮允许选择随机数据点,而不是通过左右箭头进行有序循环选择。
选择工具栏的右侧包含许多控件。
“Select related” 按钮查看当前选择中的所有数据点,并将与它们 “相关” 的任何数据点添加到当前选择中。在 LIT 中,“related”(相关)定义为从某个源数据点(通过手动编辑或数据点生成器)创建的数据点,或者从中创建所选数据点的源数据点。
“Clear selection” 按钮取消选择所有选中的数据点。
“Compare datapoints” 按钮将 LIT 置于数据点比较模式,在这种模式下,可以跨所有适用的模块对两个数据点进行相互比较。稍后将更详细地描述该模式。
“Datapoint color” 下拉菜单允许设置模块中每个数据点的颜色,这些模块将所有数据点(例如 Embeddings 和 Prediction Score 模块)进行可视化,方法是在这些数据点上设置任意数量的数据点特征或模型输出(例如根据某些类别输入特征或者根据回归任务的预测错误进行着色)。下拉菜单还包含当前颜色设置的颜色图例。
“Slices” 下拉菜单打开切片控件,这些控件允许控制 LIT 工具中保存的数据集切片。
切片
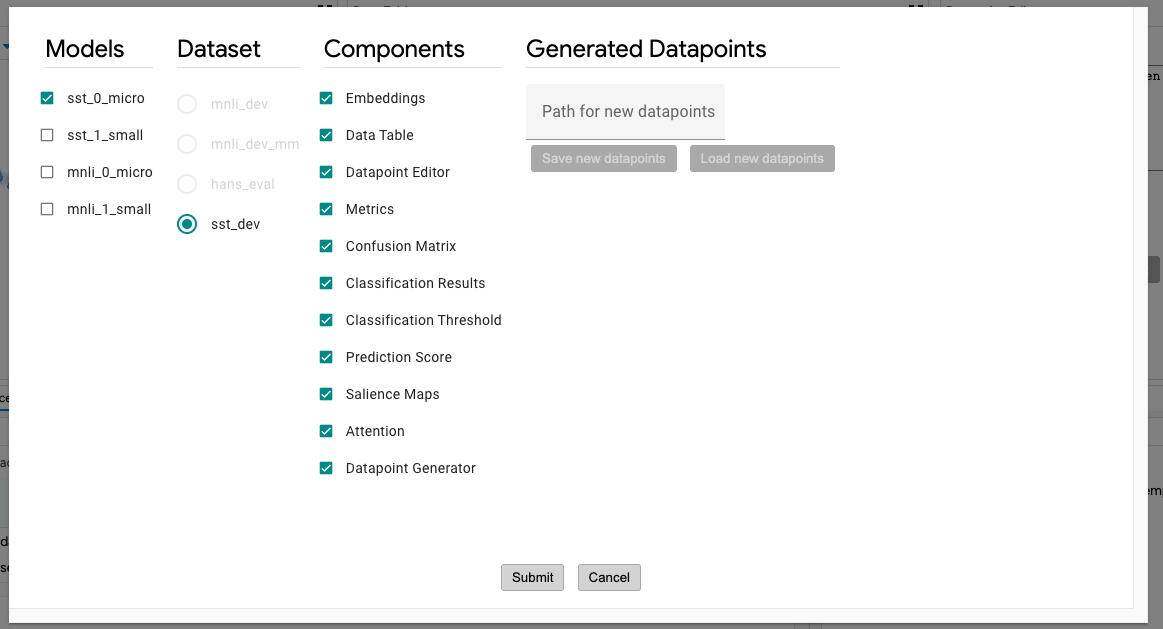
切片控件允许创建、编辑、选择和删除切片。通过给当前选择命名并单击 “Create slice” 按钮,可以将当前选择保存为切片。右侧的下拉菜单允许你选择任何以前保存的切片。这包括上面在选择工具栏部分描述的 “Favorites” 切片。
特征复选框允许用户在创建切片时通过输入特征来对数进行分面(facet)。在下面的截图中,我们创建了一个名为 “interesting” 的新切片,并选中了复选框,通过 “label” 特征进行分面。在这个例子中,“label” 特征是数据集中的一个特征,对于每个数据点来说,它描述了它在某个分类任务中属于哪个真相(对于本二进制分类示例,可以是 “0” 或 “1” )。因此,通过创建一个启用这个复选框的切片,该工具实际上将创建两个切片:一个名为 “interesting label:0” 的切片用于数据点,其标签设置为 0,另一个名为 “interesting label:1” 的切片,其标签设置为 “1”。
状态栏
工具底部的状态栏在左侧包含一个文本区。如果该工具当前正在等待对后端的调用结果(例如运行预测或获取嵌入),该信息将在状态栏中显示,同时显示一个无法确定的进度栏,表明结果正处于等待状态。如果对后端的调用失败,有关失败的信息将以红色显示在这个区域中,以指出错误,并且该信息将保存在状态栏中,直到用户通过错误单击 “×” 按钮来消除错误状态的显示。
比较模型
通过在全局设置空间中加载多个模型,LIT 可以比较多个模型。然后复制显示每个模型信息的模块子集,以便于在两个模型之间进行比较。其他模块,如 Embedding、Metric 模块已更新,可以显示来自所有模型的信息。
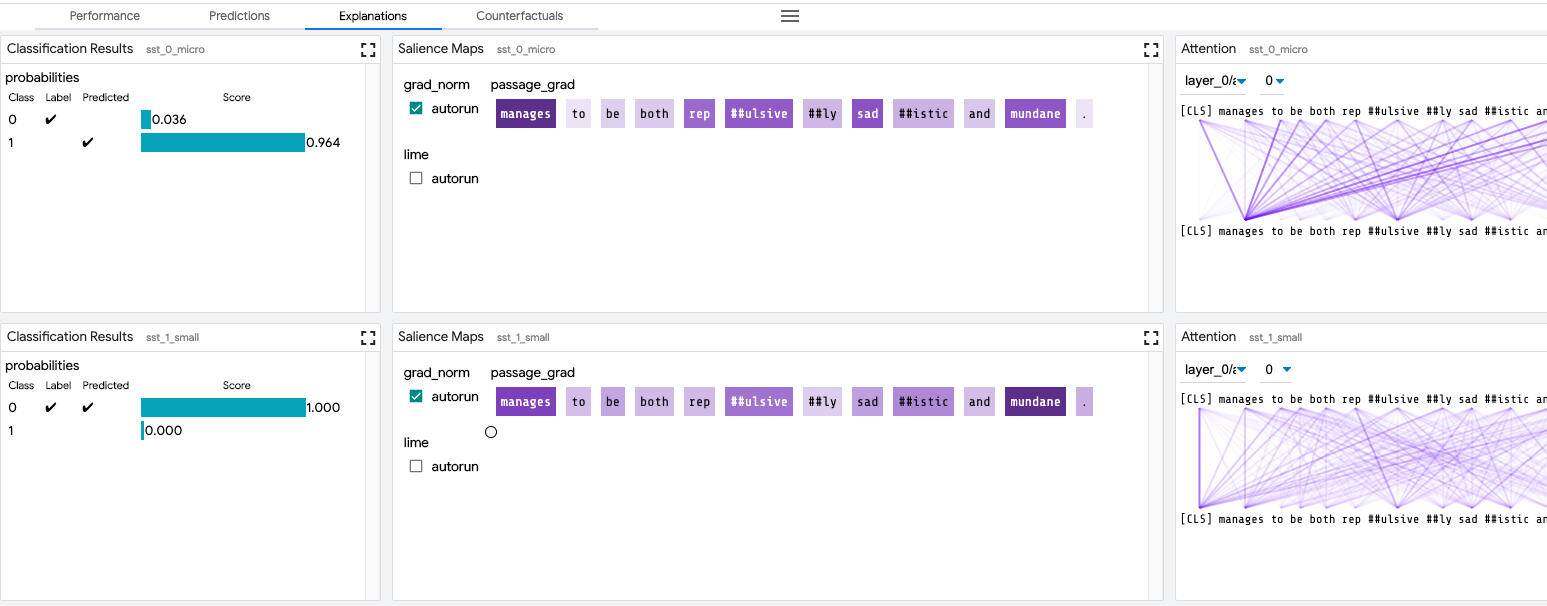
比较数据点
在选择工具栏中切换 “Compare datapoints” 按钮,将 LIT 置于数据点比较模式。在这种模式下,使用主数据点选择作为参考数据点,任何后续的主数据点选择设置都会导致它与参考数据点进行比较。引用数据点在数据表中以蓝色边框突出显示。
就像比较模型一样,某些模块也是重复的,一个模块显示参考数据点,另一个模块显示主选择数据点。
这样就可以很容易地将模型结果与任何生成的反事实数据点或加载数据集的任何其他数据点进行比较。
URL 共享
LIT 应用程序的许多状态,例如模型和数据集的加载、数据点的选择和模块的禁用,都存储在 URL 参数中。通过这种方式,如果用户希望与他人共享具有特定视图的工具,他们可以将复制 URL 作为共享的手段。
嵌入投影仪
当将 LIT 与返回嵌入(或激活)的模型一起使用时,除了预测之外,嵌入投影仪将通过嵌入乡下投影到三维的方式显示所有数据点。这对于探索和理解数据点集群非常有用。
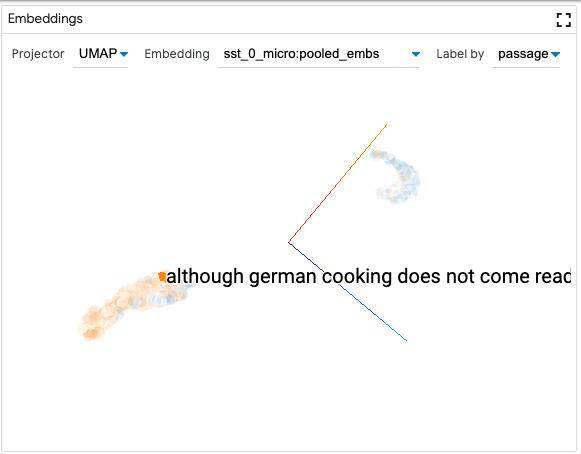
用于生成投影的特定嵌入可以在下拉列表中选择,同时使用投影方法(UMAP 或 PCA)。附加的下拉菜单允许更改用于每个数据点标签的数据特性。标签显示在数据点上,可通过鼠标悬停或单击看到。
可视化可以通过单击-拖动交互进行旋转,也可以通过按住 Ctrl 键+单击-拖动进行平移。还可以通过单击来选择一个数据点,或者通过 Shift+单击-拖动交互使用套索来选择一组数据点。
数据点的颜色由选择工具栏中的颜色设置控制。
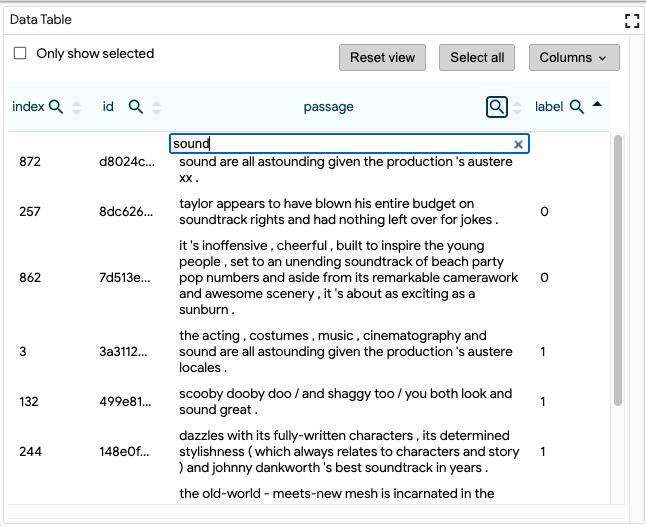
数据表
数据表在一个简单的表中显示所有数据点。可以通过单击选择或取消所选数据点。Shift 键+单击允许选择一组连续的数据点;Ctrl 键+单击允许一次选择一组单独的数据点。当前选定的数据点以浅蓝色背景突出显示。主选择的数据点以较深的蓝色背景突出显示。如果当前选择了一组数据点,单击该数据集中的单个数据点,会将其更改为主选择的数据点,而不会更改整个选定的数据点集。
默认的排序循序按照从数据集加载的顺序显示数据点,但新生成的数据点直接放在它们的 “源” 数据点的下面,而不是放在表的末尾。
通过使用表格标题行中的上下箭头,可以将排序顺序更改为按列排序。此外,可以使用表格标题行中每个列的搜索按钮通过文本搜索来筛选数据表。所有设置了筛选器的列都会显示其搜索按钮。单击某列的搜索框中的 “×” 按钮,将会清除该列的筛选器。
“Only show selected”(仅显示选定项)复选框可将数据表切换为仅显示当前选定的数据点。
“Rest view”(重置视图)按钮可将数据表返回到其标准默认视图。
“Columns”(列)的下拉菜单允许显示/隐藏特定列,以自定义数据表显示的内容。可以通过这个下拉菜单将模型预测添加为列,但为了保持表的整洁性,它们在默认情况下不会显示在数据表中。
下面的数据表显示了按 “Label” 字段排序的数据点,其中 “Passage” 字段被过滤为只包含单词 “Sound” 的数据点。
数据点编辑器
如果选择了主选择数据点,数据点编辑器将显示其详细信息。任何字段都可以进行编辑,并通过 “Make new datapoint” 按钮用这些编辑创建一个新的数据点。对现有数据点的任何编辑都必须保存为一个新的数据点,以使数据点保持不变,从而简化使用。
当没有选择数据点时,编辑器会显示一个空白数据点,可以手动填充以创建一个全新的数据点。
名称旁边带有 “(*)” 的特征作为模型输入是必需的,并且必须填充以创建新的数据点。其他字段为可选字段。
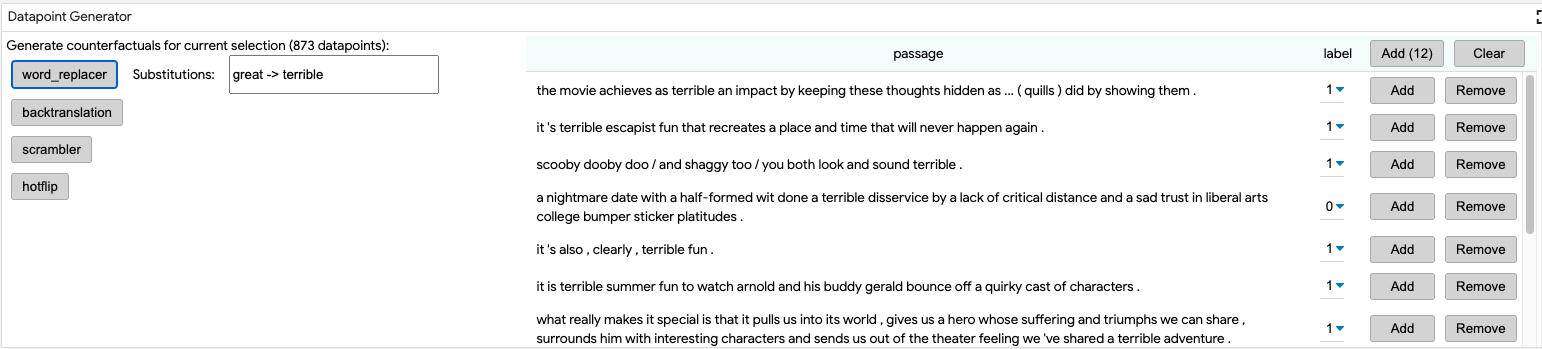
数据点生成器
数据点生成器模块允许通过一组反事实数据点生成器从所有当前选择的数据点(如果没有选择数据点的话,则从整个数据集)创建新的数据点。这些生成器由后端提供,所有可用的生成器都将在模块中显示为按钮。单击其中一个按钮可以创建新的数据点,这些数据点显示在模块内部的表中,并且可以通过添加按钮单独或完全添加到数据集中。
LIT 内置的生成器包括:
Scrambler:随机对文本特征中的单词进行打乱。
Backtranslation:将文本特征翻译成其他语言,然后再翻译会源语言,从而对初始文本特征创建释义。
Hotflip:当对分类任务进行分析时,模型提供基于令牌的梯度,该生成器将对预测影响最大的令牌更改为影响最大的令牌。
Word replacer:提供一个文本框来定义要执行的替换集,用逗号分割,如 “great” → “terrible”,“hi” → “hello”。反事实数据点是为任何包含源词的数据点创建的,并将其替换为提供的结果词。
在将生成的数据点添加到数据集之前,可以对其中的非文本字段进行编辑。这一点很重要,因为在反事实数据生成之后,某些数据点特征不在正确。例如,在情感分类器中,如果使用替换词生成器在输入 “this movie is good” 中的 “good” 替换为 “terrible”,那么在将数据点添加到数据集进行分析之前,你可能希望将该数据点的真实情绪从 1 改成 0。
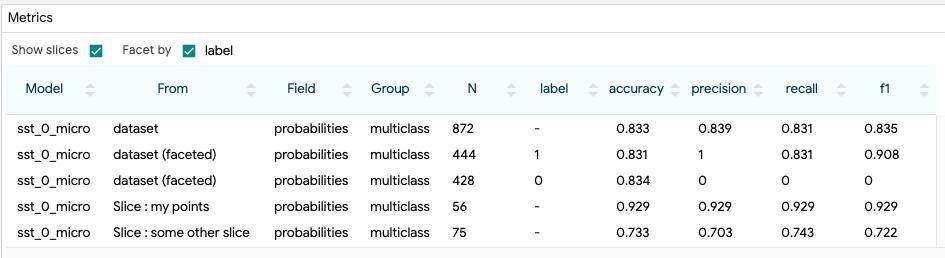
度量表
度量表以表格格式显示了每个模型的度量。确切的度量类型由 Python 度量组件确定,该组件计算给定被评估的模型类型的情况下计算度量。这些度量包括正确性(对于分类器)、误差(对于回归任务)、BLUE 评分(对于翻译任务)等等。默认情况下,度量值是针对整个数据集以及当前选择的数据集进行计算并显示的。此外,通过 “show slices” 复选框,度量表还可以计算并显示每个保存的切片的度量。
还有一个 “Facet by” 数据集特征复选框;数据集中的每个要素都有一个复选框,其结果可以通过这些特征进行分面。当检查其中的一个或多个时,数据集(或当前选择,如果有的话)将被分割为每个计算的存储桶的子组中,并显示感兴趣的数据点的那些子集的度量。例如,假设数据集中有分类的性别特征,这可以用来比较赌性分类器的指标,并按性别进行分类。
下面的屏幕截图显示了包含整个数据集的度量值的度量表、将数据集分割为标签为 0 和标签为 1 的数据点的度量值,以及用户创建的两个命名切片的度量值。
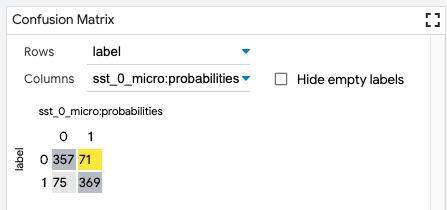
混淆矩阵
混淆矩阵将数据集中的所有数据点(或者当前选择,如果进行有选择的话)存储到一个二维矩阵的存储桶中。这通常用于对模型上的分类预测与数据点的真相类别进行比较。但是,矩阵的轴是可配置的,可以设置为数据集中的任何分类字段,或者从模型返回。因此,当比较两个模型时,可以建立混淆矩阵来显示两个模型中分类之间的一致性/不一致性,而不是一个模型的分类与真相之间的一致性/不一致性。
各个单元格以及行和列标题都可以单击,以切换该单元格或行或列中数据点的选择。这样,混淆矩阵模块可以用于选择感兴趣的点,比如二进制分类任务中的所有误报,或比较两个模型在分类上不一致的所有数据点。
预测得分
预测得分模块显示一组散点图或抖动图,对应于加载模型的每个标量输出(例如,特定类别的回归得分或分类得分)。它们中的每一个都包含数据集中的所有数据点,这些数据点按得分水平排列。对于分类得分,Y 轴是数据的随机抖动,以便更好地查看所有数据点。对于回归得分,在已知真相的情况下,Y 轴是预测中的误差(低于 X 轴的点被低估)。
数据点可以通过单击来选择。也可以通过点击和多动来选择数据点。
数据点的颜色由选择工具栏中的颜色设置控制。
对于二进制分类任务,该模块还包含一个阈值滑块,用于更改正分类的阈值,在该阈值处将数据点分类为正分类。这个滑块的默认值为 0.5。
对于在模型规范中设置 null 索引的多类分类任务,此模块还包含一个非默认类的边距(margin)滑块,以控制在将数据点归类为该类(而不是默认类)之前,该类中的分类分数必须有多高。边距值默认为 0,这意味着得分最高的类就是推断出的数据点所在的类。
下面的截图显示了用于二进制分类任务的模块,在这个任务中,正分类阈值已更改,并且决策边界附近的数据点被选中用于进一步分析。
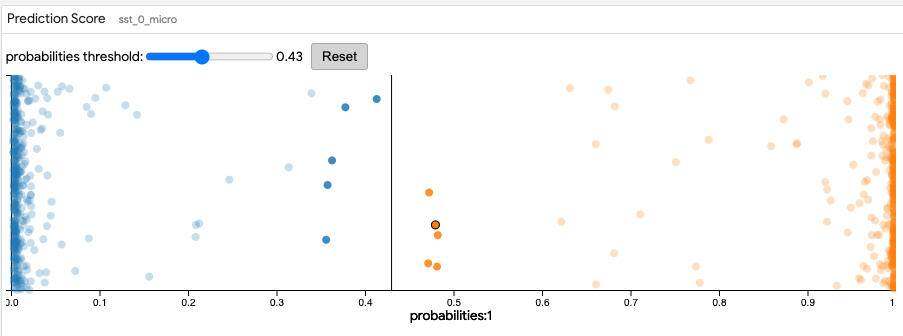
下面的截图显示了这个二进制分类任务的模块,在这个任务中,正分类阈值被改变,靠近决策边界的数据点被选中以进行进一步分析。
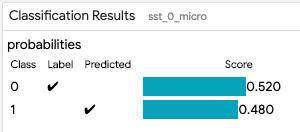
模型输出
模型输出模块显示主选择数据点上的模型结果。这些模块的视觉效果取决于所执行的模型任务。对于简单的分类任务,它将显示来自模型的类别得分,预测的类别,如果数据集中有真相,它还将显示真相分类。
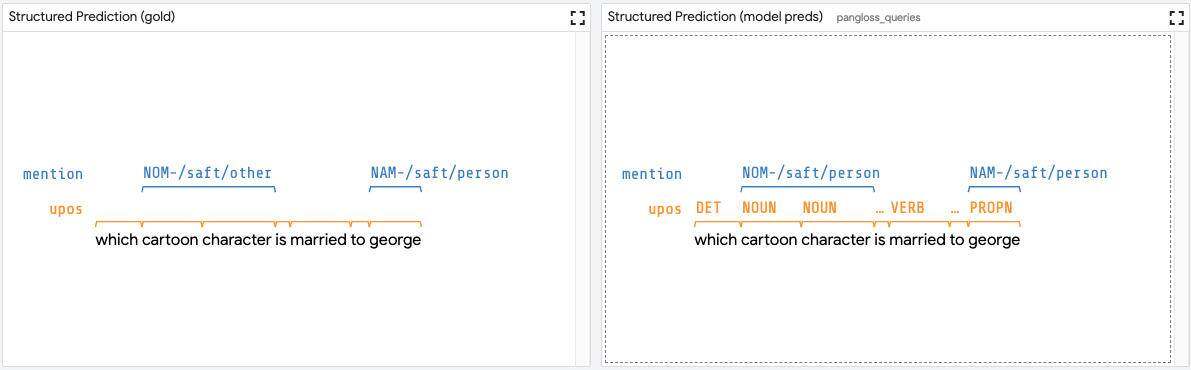
对于像跨度(span)标记这样的结构化预测任务,跨度图模块可以显示由模型返回的有标记跨度,以及真相跨度的可视化(如果数据集中有可用跨度的话)。
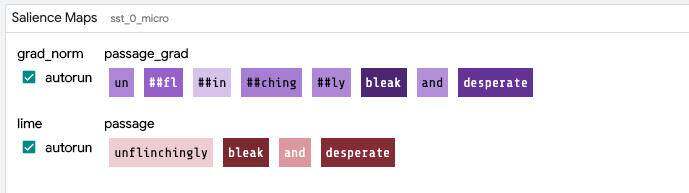
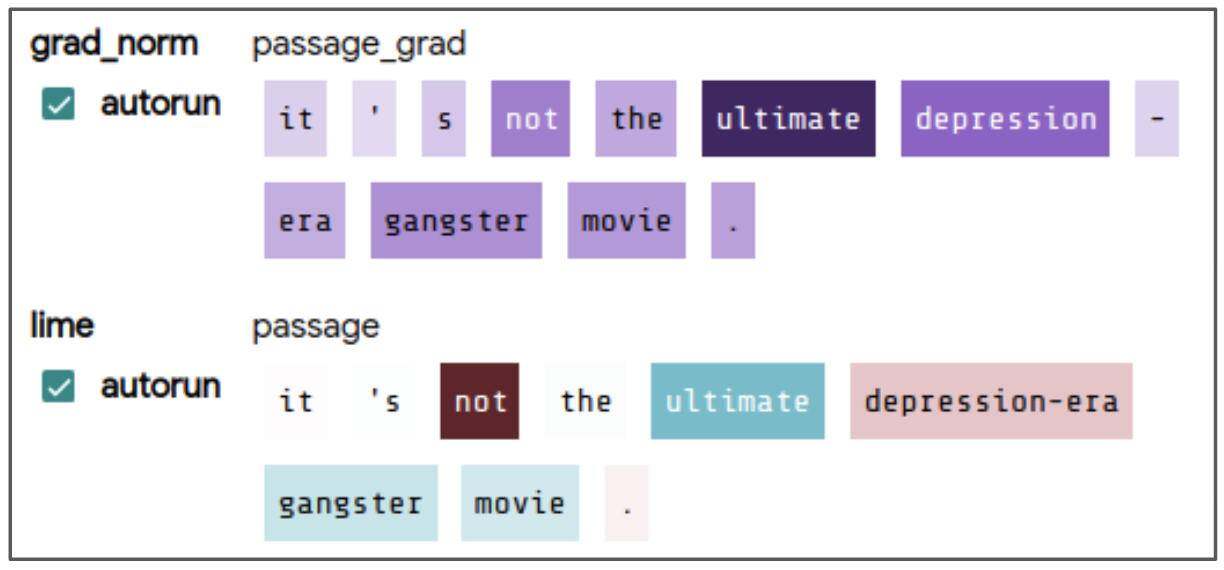
显著图
显著图显示了输入特征的不同部分对模型预测主选择的影响。这个模块可以包含用于计算这种显著性的多种方法,具体取决于正在分析的模型的功能(例如,如果模型提供梯度,则可以计算并显示基于梯度的令牌显著性)。每个文本片段的背景颜色根据该片段在预测上的突出程度进行着色,将鼠标悬停在任何片段上都会显示该片段计算的精确值。
每种方法都有一个 “autorun” 按钮。如果点击了这个按钮,则在选择新的主数据点时进行计算。如果没点这个按钮,则在选中之前不会进行计算。这可能很有价值,因此不会在每个数据点选择执行昂贵的、长时间运行的显著性计算(例如 LIME),而仅在明确要求时才执行。
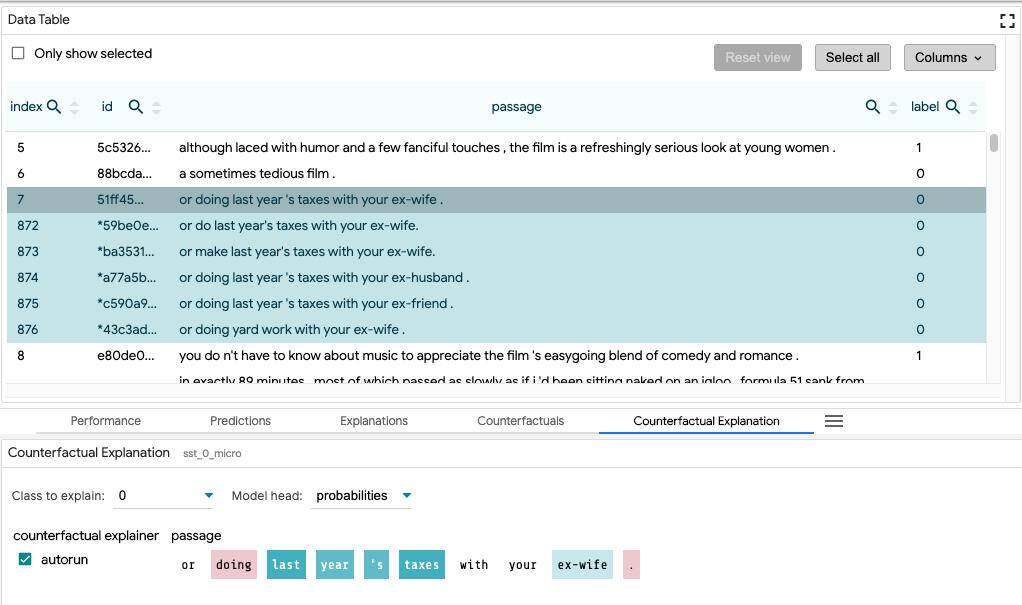
反事实解释
反事实解释模块和显著映射模块一样,显示了输入特征的不同部分对模型预测主选择的影响。主要区别在于,在这个模块中,通过查看这个感兴趣的数据点上的模型结果,与其他所选数据点上的结果进行比较,并考虑到这些其他数据点与主选择数据点的不同之处和方式来计算影响。
通过这种方式,此模块的主要用例是获取单个数据点并从中创建一组大量的反事实数据点(通过手动更改和/或数据点生成器模块)。然后,除了感兴趣的数据点的主选择之外,选择所有这些反事实,并在此模块中运行分析。通过下拉菜单,你可以选择哪个模型任务,对于分类任务,可以选择要解释的类。
最终结果是一个图,显示主选择的数据点中每个文本片段的不同影响值,并以与其他显著图相同的方式显示。
下面的截图显示了一组感兴趣的数据点,以及在数据表中创建的一组反事实的数据点,以及从这个选择中生成的反事实解释结果。
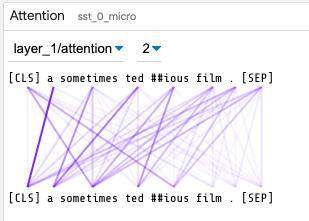
注意力
对于在预测的同时返回注意力信息的模型,注意力模块显示了模型的各层之间关注了哪些标记。下拉菜单允许你选择正在可视化的层和注意力头。线条的不透明度由这些标记之间的注意力大小控制。
用户旅程
在本节中,我们将探索一些示例用户旅程,以及 LIT 如何实现它们。
情感分析
情感分类器处理否定的能力如何?我们加载了斯坦福情感树库(Stanford Sentiment Treebank)的开发集,并使用 LIT 数据表中的搜索功能查找包含单词 “not” 的 56 个数据点。查看度量表,我们惊奇地发现,我们的 BERT 模型实现了 100%的正确性!但我们可能想知道这个结果是否真的可靠。使用 LIT,我们就可以选择单个数据点并寻找解释。例如,以负面评论为例,“It’s not the ultimate depression-era gangster movie.” 如下面的截图所示,显著图表明 “not” 和 “ultimate” 对预测很重要。
我们可以通过使用 LIT Datapoint Editor,创建修改的输入来验证这一点。去掉 “not” 后,这句话变成 “It’s the ultimate depression-era gangster movie.” ,得到的是一个强烈的积极预测,而替换 “ultimate”,得到的是 “It’s not the worst depression-era gangster movie.”。从我们的模型中得到了轻微的积极得分。
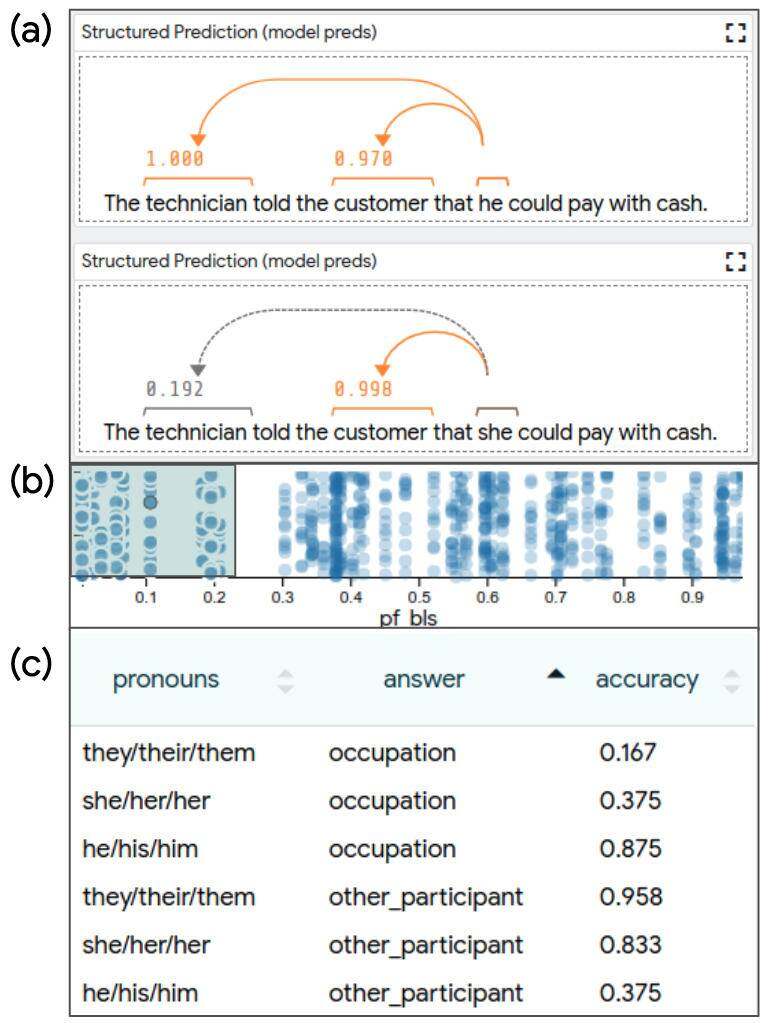
指代消解中的性别偏见
系统是否对性别关联进行了编码,从而可能导致错误的预测?我们加载一个基于 OntoNotes 上训练过的共指消解模型(Coreference models),并将 WinGenerder 数据集加载到 LIT 中进行评估。每个 Winogender 示例都有一个代词和两个候选指代词,一个是职业术语(如 “technology” ),另一个是 “other participant”(如 “customer” )。我们的模型预测了每个候选者的供职概率。我们可以通过并排比较两个示例来探索模型对代词的敏感性(见截图(a)部分)。我们可以看到,通过分页数据及或选择感兴趣的特定片段,模型通常会出现类似的错误。例如,我们可以使用预测得分模块(截图(b)部分),根据美国劳工统计局(U.S. Bureau of Labor Statistics)的数据,选择职业术语与高比例(Fe)男性工人相关的数据点。
在度量表中,我们可以根据代词类型和真正指代人对这一选择进行切片。在以男性为主的职业集上(按劳工统计局的数据,女性比例<25%),我们看到,当真相与刻板印象相符时,该模型表现良好,例如,当答案是职业术语时,男性代词有 83%的时间被正确解析 而女性代词只有 37.5%的时间被正确解析(见截图(c)部分)。
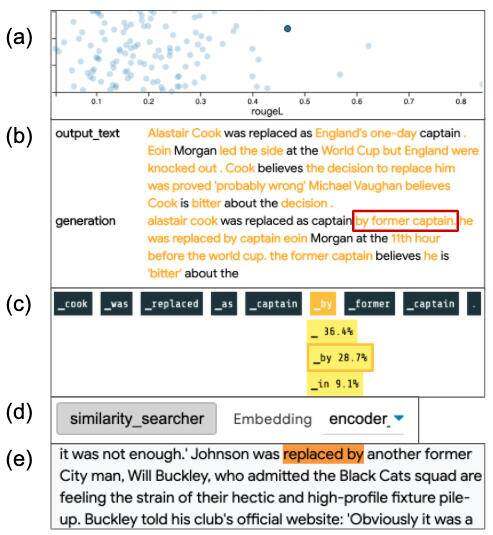
调试文本生成
训练数据是否可判断文本生成中的特定错误?我们分析了 CNN-DM 摘要任务的一个 T5 模型。LIT 的预测得分模块允许我们查看每个实例的 ROUGE 分数,并快速选择一个性能中等的示例(见截图(a)部分)。我们发现生成的文本(见截图(b)部分)包含一个错误成分: “alastair cook was replaces as captain by former captain …”。
我们可以更深入地挖掘,使用 LIT 的语言建模模块(见截图(c)部分),看到令牌 “by” 被预测的概率很高(28.7%)。
为了找出 T5 是如何得出这个预测的,我们通过数据点生成器(见截图(b)部分)利用了相似性搜索器的组件。这使用来自 T5 解码器的嵌入,从训练语料库上从预先构建的索引执行快速近似最近邻查找。只需点击一下,我们就可以检索 25 个最近邻,并将它们添加到 LIT 的用户界面中进行检查。在这些示例中,我们看到 “captain” 和 “former” 这两个词分别出现了 34 次和 16 次,还有 3 次出现了 “replaced by”(见截图(e)部分),这表明我们对错误短语的先验性很强。
作者介绍:
Google PAIR(People+AI Research 的缩写)。以人为本的研究和设计,以使人工智能伙伴关系富有成效、令人愉快和公平为目标。
原文链接:
https://github.com/PAIR-code/lit/blob/main/docs/user_guide.md
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


InfoQ 主编

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 1 条评论