

Pinot是可扩展分布式列式OLAP数据存储,由 LinkedIn 开发,为面向站点的用例(如 LindedIn 的Who viewed my profile、Talent insights等等)提供实时分析。Pinot 使用Apache Helix管理集群资源,并使用Apache Zookeeper存储元数据。Piont 在 LinkedIn 得到了广泛的采用:从内部控制面板到面向站点的应用程序。
Pinot 通过Hadoop支持批数据摄取(称为“离线”数据),以及通过流(如Kafka)支持实时数据摄取。Pinot 使用离线和实时数据,提供持续时间线上的分析,从最早可用的行(可以在离线数据中)开始一直到流中的最近使用过的行。
从实时流中摄取行对数据查询服务提出了一系列独特的挑战。Pinot 一直在努力解决这些挑战,并随着时间的推移,做得越来越好。
Pinot 在名为“段(segment)”的碎片中存储数据。在执行查询期间,Pinot 并行处理这些段,并跨段合并结果以构造对查询的最终响应。离线数据作为预构段(离线段)被推入 Pinot,并存储于 Segment Store(请参看架构图)。这些段作为 ImmutableSegment 对象(在这些段上不可进行行的添加、删除、或修改)存储。另一方面,实时数据的消费是在持续从底层流分区到被称为 MutableSegment 的段(或“消费”段)的基础上进行的。这些段允许给它们添加行(但是,这些行仍然不可以被删除或更新)。MutableSegment 以非压缩(但仍为列式)的形式把行存储于易失性存储器(在重启时被丢弃)。
有时,MutableSegment 中的行被压缩,作为 ImmutableSegment,通过“提交”该段进入 Segment Store 而持久化。然后,Pinot 继续使用来自流分区到新 MutableSegment 的下一组行。这里的关键问题是:“Pinot 应该在什么时间点(或,多久)决定提交消费段?”
过于频繁地提交段会导致表中有很多小段。由于 Pinot 查询是在段级别处理的,因此,有太多的段会增加处理查询(产生的线程数、元数据处理等等)的开销,从而导致更高的查询延迟。
另一方面,不那么频繁地提交段会导致服务器耗尽内存,这是因为新的行一直在被添加到 MutableSegment,从而扩展了这些段的内存占用。此外,服务器可以在任何时候重启(在 LinkedIn,我们每周推送新代码),这引起 MutableSegment 丢弃所有行并再次重新从 MutableSegment 的首行开始消费。这对它本身来说不是问题(Pinot 可以以非常高的速率摄取后备数据),但是,底层流主题可能已经配置了保留,因此,MutableSegment 的首行已经被保留。在这种情况下,我们丢失了数据,这可不好!
事实证明,答案取决于几个因素,如摄取速率和模式中的列数量等等,这些因素随着不同的应用程序而不同。Pinot 提供了一些配置设置(如,在 MutableSegment 中行数最大值的设置)以解决问题,但是,如何根据每个应用程序来设置这些设置的正确值,在管理员看来仍然存疑。
考虑到 Pinot 在 LinkedIn 的采用率,为每个应用程序用不同的设置(或组合)进行试验不是可扩展的解决方案。在本博文中,我们将解释我们如何实施实时消费的自动调整以完全消除试验过程,并有助于管理员扩展到 Pinot 的采用率。
为了更好地理解这个问题及其解决方案,更详细地介绍一下 Pinot 实时架构是很有用的。
Pinot 实时摄取
Pinot 实时服务器为每个流分区创建 PartitionComsumer 对象,这些流分区是 Pinot 实时服务器定向(通过 Helix)消费的。如果表配置为有 q 个副本,并且有 p 个流分区,那么,表中所有的服务器上会有 PartitionComsumber 对象的(p*q)个实例。如果有 S 个服务器为该表服务,那么每个服务器将有⌈(p * q)/S ⌉个 PartitionComsumer 实例。
下图是 PartitionConsumer 对象如何跨 Pinot 实时服务器分布的示意图。
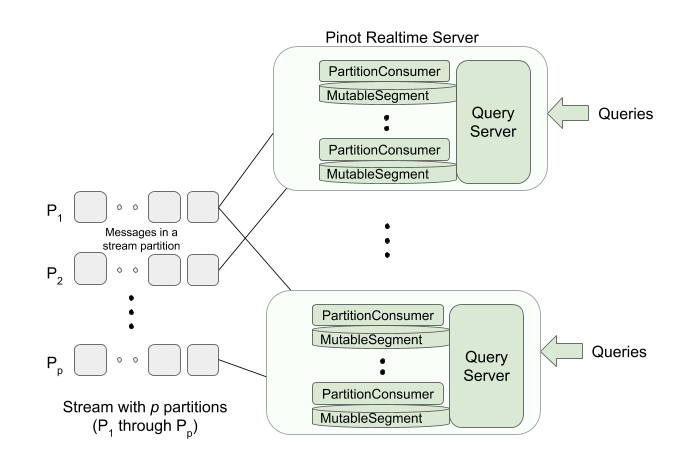
实时服务器从 p 分区的流消费
Helix 确保,在同一个实时服务器中永远不会消费任何流分区的多个副本。 (因此,我们必须设置 S >= q),否则,表的创建将不会成功。
Pinot 假设,底层流分区有消息,这些消息根据它们到达分区的时间进行了排序,并且,每个消息以特定的“偏移量”(本质上是指向该消息的指针)在该分区中被定位。流分区的每个消息被转换成 MutableSegment 中的行。每个 MutableSegment 实例都有来自只有一个流分区的行。
MutbaleSegment(在 Zookeeper 中)的元数据在分区中有偏移量,应该从该分区开始消费该段。这个起始偏移量适用于 MutableSegment 的所有副本。Pinot 控制器在创建段的时候(即,或者是在第一次创建表的时候,或者是在提交该分区中前一个段的时候)于段元数据中设置起始偏移量。
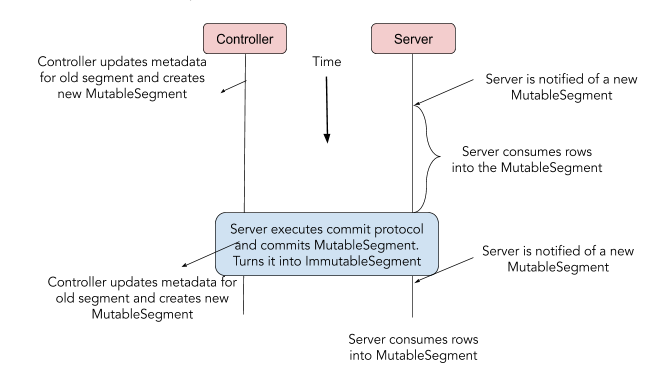
该提交段的算法涉及几个步骤,在此期间,继续从 MutableSegment 提供查询服务。在提交了段之后,MutbaleSegment 被原子性地与(等效)ImmutableSegment 进行交换。MutableSegment 实例占用的内存在耗尽该实例上最后一个查询后就被释放。在整个过程中,该应用程序都不知道哪个段提交在进行。该提交段的算法如下所示:
暂停消费(直到第 5 步)。
执行段完成协议的步骤以确定哪个副本提交该段。
用 MutableSegment 中的行构建一个 ImmutbaleSegment。
提交该段给控制器(在这个步骤,控制器在分区中创建下一个段)
等待给下一个段的信号(来自 Helix)
当收到信号时,恢复消费,将行索引到新的 MutableSegment。
该算法如下图所示。段完成的实际步骤还有很多,但是,我们在本文中略去了细节。
提供的问题
所提供的应用程序的特征之间可以有很大的差异。以下是跨应用程序的部分变体列表:
在内存中保持一行的开销取决于数据模式(列越多,则所需的内存也越多)。
Pinot 使用字典编码来优化内存消耗(行中的值作为整数字典 ID 存储,整数字典 ID 引用字典中的实际值)。因此,任何列的唯一值越多,所消耗的字典中的内存也越多。
事件摄入主题的速率在不同的应用程序之间有很大的差异,甚至在同一个应用程序中,随着时间的不同也有差异。比如,事件进入的速率可能在周一早上比在周五晚上要高得多。
流分区的数量可以随着不同的应用程序有所不同(请参考下图,查看影响)。
比起另一个具有较低查询负载的应用程序,我们可以给一个具有更高查询负载的应用程序提供不同数量的机器。
在 Pinot 的早期版本中,我们提供了两种配置设置:
在一个服务器中,跨所有 MutableSegment 可以保留的最大行数值(N)。
可存在的 MutableSegment 的最大时间值(T)。在这个时间之后,无论当时段中有多少行,都提交该段。管理员可以根据底层流的保留情况来设置 T 的值。
如果一个服务器最终拥有 k ( = ⌈(p * q)/S ⌉)个表分区,那么 Pinot 控制器设置段的元数据最多消费 x (= N/k)行。PartitionConsumer 旨在根据到达时间 T 或在消费 x 行到 MutableSegment 后,停止消费并启动提交过程。然而,跨应用程序的变化要求针对不同的应用程序有不同的 N 值。
管理员在选择 N 之前还要考虑另一件事情:每个服务器的驻留内存大小(用于 MutableSegments 和 ImmutableSegments):
在创建 MutableSegment 时,(尽可能地)获取用于 MutableSegment 的内存。基于该段阈值 x 的设置,取得相应的内存数量(因此,x 的值很高而没有使用分配到的内存就是浪费)。
ImmutableSegment 驻留在虚拟内存中,直到实时表的保留时间结束,并在那个时间点卸载。x 的值更高就意味着更少的(更大的)ImmutableSegment 对象,及更大的 MutableSegment 对象。
服务器上的总驻留内存将取决于以下因素:
服务器托管的流分区数量(k)。
在保留期间所创建的 ImmutableSegment 的数量。
ImmutableSegment 的大小。
MutableSegment 的大小(取决于 x,以及上面概述的其他内容)。
k 的值取决于部署的服务器数量。管理员可以决定在给定的要求延迟下,部署尽可能多的服务器以支持查询吞吐量。
正如我们可以看到的,变量的数量很快失控,我们似乎需要用一个变量来估计另一个,为了达成可用的配置设置,在提供用例前,管理员必须运行基准测试:
建立一张包含若干服务器和 N 值的表。
从流分区中最早的偏移量开始消费,以便我们能够让 ImmutableSegment 到位(这是一个近似值,因为对任何给定的流主题,摄取速率随时间而变化,导致我们触及时间限制而不是行限制)。
运行保留管理器以保留旧段。
如果有太多的分页或者内存不足,那么,更改服务器的数量或 N(取决于段的大小),并回到步骤 1。
运行一个查询基准测试,以应用程序期望的速度触发查询。如果没有达到期望的性能,那么,增加主机的数量并回到步骤 1,根据需要重新调整 N 的值。
为应用程序实现正确的配置设置需要一些日子(有时候是几天),更不用说,当 Pinot 管理员有更多紧急事件要关注的时候需要花费的时间了。
自动调优
为了帮助管理员提供用例,我们决定提供:
已提交段的目标段大小设置。Pinot 将尝试创建这么大的 ImmutableSegment 对象。
命令行工具,用来帮助管理员选择目标段大小。
有了这两样工具, 管理员需要做的就是,用一个示例段(通过 ETL 之前在同一个主题上收集的数据生成)运行命令行工具。根据查询处理所需服务器的数量,该工具输出一些供选择的选项。然后,管理人员可以选择其一并提供该表,确信其按期望的合理性能工作。
命令行工具
给定示例段,该工具估计主机上的驻留内存及段大小的设置。该工具的工作原理是通过这些段大小估计驻留内存。
以下是 RealtimeProvisioningHelper 为一张表提供的示例输出:
该输出显示,针对不同数量的服务器和不同时间,MutableSegment 消费数据的情况:
服务器中所用的总内存(用于 MutableSegment 和 ImmutableSegment)。
优化段大小设置。
MutableSegment 将使用的内存量(内存消耗)。
这其中的每一个值都根据消费的小时数而不同,因此,针对命令行参数中提供的不同数值来显示这些值。管理员指定他们正在考虑的主机的数量(在本例中,是 8、10、12 或 14 台主机)、来自消费数据的示例段(或来自离线数据的示例段)以及表的配置(用于保留时间等)。该实用程序按上面的方式打印出矩阵。
根据这个输出,管理人员可以选择部署 8、10、12 或 14 台主机,并根据每张表适当地选择段的大小限制。在上面的例子中,如果管理员选择使用 12 台服务器(比方说,基于查询吞吐的需求),那么,10 个小时似乎是最优的内存使用时间。该最优的段的大小似乎是 360MB,配置将如下所示(出于简洁的考虑,略去 StreamConfigs 的其他参数):
基于该工具的输出,我们知道,在段的大小约为 360MB 的时候,如果 PartitionConsumer 提交段,我们应该是在 MutableSegment 和 ImmutableSegment 之间最优地利用驻留内存。请注意,360MB 是 ImmutableSegment 的大小。正如前面的解释,MutableSegment 在提交段的时候转换为 ImmutableSegment,因此,在构建 ImmutableSegment 之前,确定其大小是鸡生蛋还是蛋生鸡的问题。
回想一下,当我们触及行限制(x)或时间限制(T)时,我们就停止消费。因此,如果我们能够为一个段设置行限制时采用这么一种方法:我们可以预计产生的段大小接近目标段大小,那么就好了。但是,我们怎样估计产生所需段大小的行数呢?
估计所需段大小的行限制
为了对一个 MutableSegment 提出行限制,我们决定利用这个事实:即控制器负责提交段和创建新段(这是它在一个步骤中所做的工作,如上图所示)。
其思想是让控制器来决定下一个段的 x 值,从而达到所期望的段大小。在段完成时,控制器根据当前段大小和在当前段内消费的行数来估计在下一个段中需要消费的行数。
ImmutableSegment 具有压缩表示中的索引、字典等形式。因此,段大小可能不会随行数线性地变化(如,无论段内有多少行,字典的大小是基于列的唯一值的数量和列的平均宽度来决定的)。还有,段大小可能有很大不同,这取决于单个段中的实际值。
因此,我们在估计下个段大小时,要考虑段大小的过去值。我们保持段大小与行数的比率,在每次段完成时提高这个比率而不是随着时间保持段大小,以便我们为下个段合理地估计行数。
用于设置行限制的算法
我们假设每个表的段大小与行数的之比都是常数(比如说,R)。由于即使创建只有一行的段也有固定开销,因此,R 不是一个真正的常数,但是,它是比较好的近似。每次段完成时,我们计算 R 的值,并对学习得到的 R 值进行调整,使其更准确,如下所示:
Rn+1 = Rn * α + Rcurrent * (1 - α), where 0 < α < 1
在这里,Rcurrent 是当前段(即正在完成过程中的段)行数与段大小之比。我们选择α是个比 0.5 高的值,以便我们给所得到的值比新值更高的权值。
下一个段的行数阈值计算如下:
xn+1 = desiredSegmentSize / Rn+1
还有,即使我们可以为段设置 x 为某个 x1,PartitionConsumer 也有可能在 x2 行后就触及时间限制 T,其中 x2 < x1。
在这种情况下,对于接下来的段,我们更希望设置行数限制为 x2,因此,我们总是尝试通过触及行限制而不是时间限制来结束段(这又回到了不浪费内存分配的问题,如前所述)。
把这些因素都考虑在内,最终的算法如下所示:
请注意,R 的值存于本地内存,而不是持久性存储中。可能发生引导控制器(lead controller)需要重启的情况(如,用于部署、故障等)。在这种情况下,另一个控制器接管领导权,并根据算法,从 R 的空值开始。但是,该算法从完成的段获取 R 的第一个值,从而有效地把该值连同所有旧段的历史传递给新的控制器。
最后,我们只在一个主题的一个分区上运行该算法。流的多个分区往往在相似的时候有相似的特征。比如,如果在早上 8 点到 9 点之间出现了 100 篇新文章,那么,在那个时间段,点击这些文章的事件可能在点击流的所有分区中遵循类似的分布。因此,在任何分区的段完成的时候,改变 R 的值都不是好主意(适用表的所有分区),这是因为,我们将会把 R 值偏向最近的段,而这不是我们希望的段。
在实践中,我们看到一个主题的所有流分区或多或少导致相同的段大小,并且同时或多或少地完成。
结果
呈现的算法实质上是基于当前完成段的一些历史和特征,计算下个段的行限制。下图显示了为达到前 20 个段的目标段大小对段大小的调整。这些是针对一张表的流主题的单个分区的度量。平均事件摄取速率为每秒 630 行,最大值在每秒 1000 行左右。
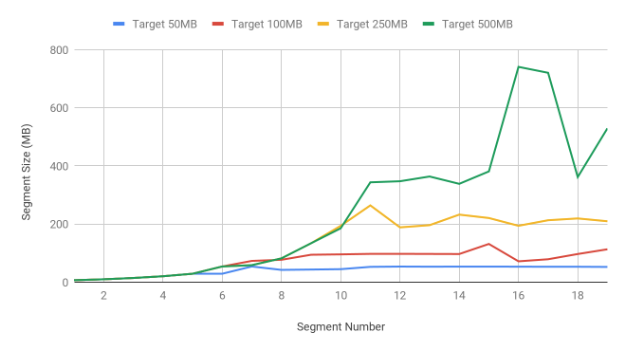
一列中唯一值(在一个段内)的数量、字典大小等等在不同段之间可以有明显的不同,尤其是我们从周末过渡到平日,或从较长的假期过渡到工作日的时候。根据主题(在生产环境中,Pinot 给 50 多个主题提供服务)、重大的世界事件、出版物、新产品发布等等,都可以显著地改变数据的特征,因而,只通过使用行数来预测段大小就变得很困难。因此,段的估计行数会导致更大(在上图的情况下,段大小目标是 500MB)或更小的段大小。
然而,在最初的学习阶段,通常会发生很夸张的变化。通常,首先提供表,随着时间查询会迅速飙升。
下图显示在 10 几天内,段大小的变化情况,目标段大小是 500M。
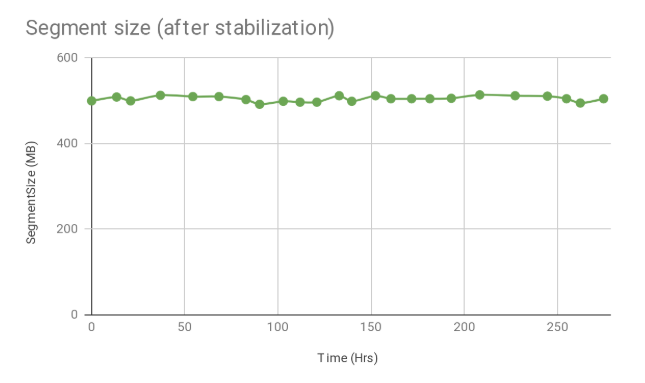
请点击这里查看该算法的代码。
结论
现在,我们基于 RealtimeProvisioningHelper 的输出提供所有单个租户实时表。这把我们评估容量的时间从以天计算减少到以分钟计算,因为管理员无需在提供集群前尝试不同的组合,并且管理员可以对此相当自信:一旦提供,则集群将按指定的方式来承担消费负载。
未来的工作
如前所述,在开始消耗内存时,我们尝试为 MutableSegment 获取所需的最大内存。在进入行时,自动分配内存是一个选项,但是,这将导致两个问题:
在处理查询时,我们将需要读锁适当的数据结构,并且在我们扩展它们的时候,我们需要写锁该结构。在处理实时消费段上的查询时,我们尽可能将锁减到最少,并尽量避免锁竞争,因此,添加更多的读锁对实现低延迟没有什么帮助。
为了避免浪费内存,我们可能一小块一小块地分配内存,这进一步加剧了锁竞争。
这块领域需要更多的工作。随着时间的推移,算法会稳定下来,但是,在学习阶段,有时它会过度调整段大小。避免这这种情况的发生是件好事。比如,为消费段用到的最大内存添加另一个配置很有用。如果我们达到了驻留内存的一定限制,那么我们可以停止消费。通常,由于基数或列宽度(字典大小的变化)的波动会引起过度的调整。如果这些是暂时的,我们真的不希望把它们作为未来段的经验。在这些情况下,尽早停止消费是很有用的。
将来,我们要研究的另一个领域是多租户系统,其中单个主机可以处理多张表的流分区。在这种情况下,单个工具将不足以设置段大小。考虑到主机内所有的 MutableSegment,无论它们属于哪张表,我们都需要其他机制以不断评估内存的使用情况。
致谢
我们感谢 Pinot 团队的所有成员,感谢他们为了让 Pinot 变得更好而付出的努力,他们是Dino Occhialini、Jean-Francois Im、Jennifer Dai、 Jialiang Li、John Gutmann、Kishore Gopalakrishna、Mayank Shrivastava、 Neha Pawar, Seunghyun Lee、 Sunitha Beeram、 Walter Huf、 Xiaotian (Jackie) Jiang、和我们的工程经理 Shraddha Sahay 及 SRE 经理 Prasanna Ravi。我们还要感谢Ravi Aringunram、Eric Baldeschwieler、Kapil Surlaker和Igor Perisic,谢谢他们的领导和不断的支持。
原文链接:
Auto-Tuning Pinot Real-Time Consumption

暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。






评论