

编者按:本文节选自方巍著《Python 数据挖掘与机器学习实战》一书中的部分章节。
2.7 网络爬虫的发展历史和分类
网络爬虫(Web Crawler)又被称为网页蜘蛛、网络机器人或网页追逐者,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。本节主要介绍网络爬虫的发展历史及爬虫的分类。
2.7.1 网络爬虫的发展历史
在互联网发展初期,网站相对较少,信息查找比较容易。然而伴随互联网“爆炸式”的发展,普通网络用户想要找到所需的资料简直如同大海捞针,这时为满足大众信息检索需求的专业搜索网站便应运而生了。
现代意义上的搜索引擎的“祖先”,是 1990 年由蒙特利尔大学学生 Alan Emtage 发明的 Archie。虽然当时 World Wide Web 还未出现,但网络中文件传输还是相当频繁的,而且由于大量的文件散布在各个分散的 FTP 主机中,查询起来非常不便,因此 Alan Archie 工作原理与现在的搜索引擎已经很接近,它依靠脚本程序自动搜索网站上的文件,然后对有关信息进行索引,供使用者以一定的表达式查询。由于 Archie 深受用户欢迎,受其启发,美国内华达 System Computing Services 大学于 1993 年开发了另一个与之非常相似的搜索工具,但此时的搜索工具除了索引文件外,已能检索网页。
当时,“机器人”一词在编程者中十分流行。电脑“机器人”(Computer Robot)是指能以人类无法达到的速度不间断地执行某项任务的软件程序。由于专门用于检索信息的“机器人”程序像蜘蛛一样在网络间爬来爬去,因此,搜索引擎的“机器人”程序就被称为“蜘蛛”程序。世界上第一个用于监测互联网发展规模的“机器人”程序是 Matthew Gray 开发的 World wide Web Wanderer。刚开始它只用来统计互联网上的服务器数量,后来则发展为能够检索网站域名。与 Wanderer 相对应,Martin Koster 于 1993 年 10 月创建了 ALIWEB,它是 Archie 的 HTTP 版本。ALIWEB 不使用“机器人”程序,而是靠网站主动提交信息来建立自己的链接索引,类似于现在熟知的 Yahoo。
随着互联网的迅速发展,使得检索所有新出现的网页变得越来越困难,因此,在 Matthew Gray 的 Wanderer 基础上,一些编程者将传统的“蜘蛛”程序工作原理做了些改进。其设想是,既然所有网页都可能有连向其他网站的链接,那么从跟踪一个网站的链接开始,就有可能检索整个互联网。到 1993 年底,一些基于此原理的搜索引擎开始纷纷涌现,其中以 JumpStation、The World Wide Web Worm(Goto 的前身,也就是今天 Overture)和 Repository-Based Software Engineering spider 最负盛名。
然而,JumpStation 和 WWW Worm 只是以搜索工具在数据库中找到匹配信息的先后次序排列搜索结果,因此毫无信息关联度可言。而 RBSE 是第一个在搜索结果排列中引入关键字串匹配程度概念的引擎。而最早的具有现代意义的搜索引擎出现于 1994 年 7 月。当时 Michael Mauldin 将 John Leavitt 的蜘蛛程序接入到其索引程序中,创建了大家现在熟知的 Lycos。同年 4 月,斯坦福(Stanford)大学的两名博士生 David Filo 和美籍华人杨致远(Gerry Yang)共同创办了超级目录索引 Yahoo,并成功地使搜索引擎的概念深入人心。从此搜索引擎进入了高速发展时期。目前,互联网上“有名有姓”的搜索引擎已达数百家,其检索的信息量也与从前不可同日而语。比如 Google,其数据库中存放的网页已达 30 亿之巨。
随着互联网规模的急剧壮大,一家搜索引擎光靠自己单打独斗已无法适应目前的市场状况,因此现在搜索引擎之间也开始出现了分工协作,并有了专业的搜索引擎技术和搜索数据库服务提供商。例如国外的 Inktomi,它本身并不是直接面向用户的搜索引擎,而是向包括 Overture(原 GoTo)、LookSmart、MSN 和 HotBot 等在内的其他搜索引擎提供全文网页搜索服务。国内的百度也属于这一类,搜狐和新浪用的就是它的技术。从这个意义上说,它们是搜索引擎中的搜索引擎。
2.7.2 网络爬虫的分类
网络爬虫种类繁多,按照部署位置进行分类,可以分为服务器侧和客户端侧。
服务器侧:一般是一个多线程程序,同时下载多个目标 HTML,可以用 PHP、Java 和 Python 等语言编写,一般的综合搜索类引擎的爬虫程序都是这样编写的。但是如果对方讨厌爬虫,很可能会封掉服务器的 IP,而服务器 IP 又不容易改,另外耗用的带宽也是较昂贵的。
客户端侧:很适合部署定题爬虫,也就是聚焦爬虫。做一个可以与 Google、百度等竞争的综合搜索引擎成功的几率微乎其微,而做垂直搜索、竞价服务或者推荐引擎,机会要多得多,这类爬虫不是什么页面都爬取,而是只爬取关心的页面,而且只爬取页面上关心的内容,例如提取黄页信息、商品价格信息,以及提取竞争对手的广告信息等。这类爬虫可以低成本地大量部署,而且很有侵略性。由于客户端的 IP 地址是动态的,所以其很难被目标网站封锁。
2.8 网络爬虫的原理
网络爬虫是通过网页的链接地址寻找网页,从网站某一个页面开始,读取网页的内容,找到在网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站上所有的网页都抓取完为止。本节主要介绍网络爬虫的基础知识、爬虫的分类,以及其工作原理。
2.8.1 理论概述
网络爬虫是一个自动提取网页的程序,它为搜索引擎从 Web 上下载网页,是搜索引擎的重要组成部分。通用网络爬虫从一个或若干初始网页的 URL 开始,获得初始网页上的 URL 列表;在抓取网页的过程中,不断地从当前页面上抽取新的 URL 放入待爬行队列,直到满足系统的停止条件才终止。
主题网络爬虫就是根据一定的网页分析算法过滤与主题无关的链接,保留与主题相关的链接并将其放入待抓取的 URL 队列中,然后根据一定的搜索策略从队列中选择下一步要抓取的网页 URL,并重复上述过程,直到达到系统的某一条件时停止。所有被网络爬虫抓取的网页将会被系统存储,进行一定的分析、过滤,并建立索引。对于主题网络爬虫来说,这一过程所得到的分析结果还可能对后续的抓取过程进行反馈和指导。
如果网页 p 中包含链接 l,则 p 称为链接 l 的父网页。如果链接 l 指向网页 t,则网页 t 称为子网页,又称为目标网页。
主题网络爬虫的基本思路就是按照事先给出的主题,分超链接和已经下载的网页内容,预测下一个待抓取的 URL 及当前网页的主题相关度,保证尽可能多地爬行、下载与主题相关的网页,尽可能少地下载无关网页。
2.8.2 爬虫的工作流程
网络爬虫的基本工作流程,如图 2-8 所示。
(1)选取一部分精心挑选的种子 URL。
(2)将这些 URL 放入待抓取 URL 队列。
(3)从待抓取 URL 队列中取出待抓取的 URL,解析 DNS 并且得到主机的 IP,将 URL 对应的网页下载下来,存储进已下载的网页库中。此外,将这些 URL 放进已抓取的 URL 队列。
(4)分析已抓取的 URL 队列中的 URL,然后解析其他 URL,并且将 URL 放入待抓取的 URL 队列,从而进入下一个循环。
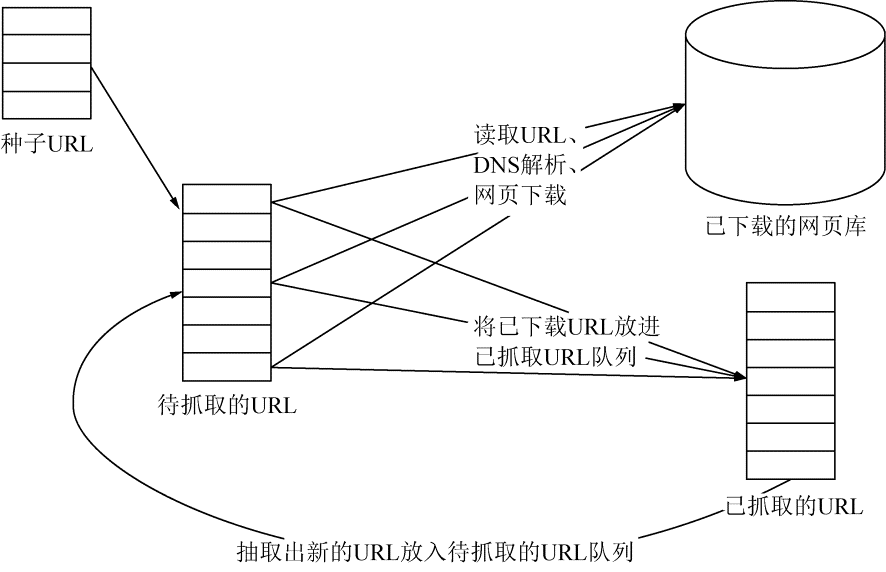
图 2-8 爬虫的工作流程
从爬虫的角度对互联网进行划分,如图 2-9 所示。
已下载的未过期网页。
已下载的已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份。互联网是动态变化的,如果一部分互联网上的内容已经发生了变化,那么抓取到的这部分网页就已经过期了。
待下载的网页:是待抓取的 URL 队列中的那些页面。
可知网页:还没有抓取下来,也没有在待抓取的 URL 队列中,但是可以通过对已抓取的页面或者待抓取的 URL 对应页面分析获取到的 URL,认为是可知网页。
还有一部分网页爬虫是无法直接抓取并下载的,称为不可知网页。
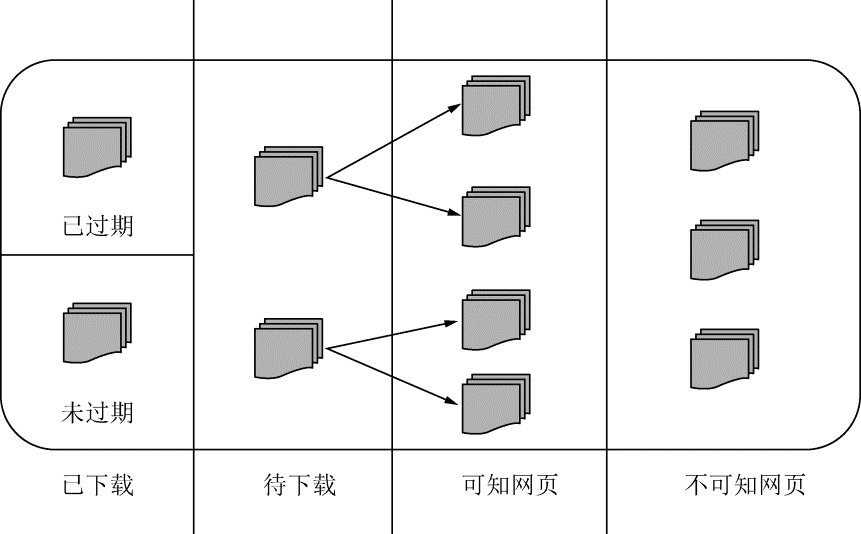
图 2-9 互联网的划分
在爬虫系统中,待抓取的 URL 队列是很重要的一部分。待抓取 URL 队列中的 URL 以什么样的顺序排列也是一个很重要的问题,因为这涉及先抓取哪个页面,后抓取哪个页面。而决定这些 URL 排列顺序的方法叫做抓取策略。下面重点介绍几种常见的抓取策略。
深度优先遍历策略:指网络爬虫会从起始页开始,一个链接一个链接地跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。
宽度优先遍历策略:将新下载网页中发现的链接直接插入待抓取 URL 队列的末尾。
反向链接数策略:指一个网页被其他网页链接指向的数量。
Partial PageRank 策略:借鉴了 PageRank 算法的思想,即对于已经下载的网页,连同待抓取 URL 队列中的 URL 形成网页集合,计算每个页面的 PageRank 值,计算完之后,将待抓取的 URL 队列中的 URL 按照 PageRank 值的大小进行排序,并按照该顺序抓取页面。
OPIC 策略:实际上也是对页面进行重要性打分。对于待抓取的 URL 队列中的所有页面,按照打分情况进行排序。
大站优先策略:对于待抓取的 URL 队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。
互联网是实时变化的,具有很强的动态性。网页更新策略主要是决定何时更新之前已经下载过的页面。常见的更新策略有以下 3 种:
(1)历史参考策略。
顾名思义,根据页面以往的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模来预测。
(2)用户体验策略。
尽管搜索引擎针对某个查询条件能够返回数量巨大的结果,但是用户往往只关注前几页结果。因此,抓取系统可以优先更新在查询结果前几页显示的网页,而后再更新后面的网页。这种更新策略也需要用到历史信息。用户体验策略保留网页的多个历史版本,并且根据过去每次的内容变化对搜索质量的影响得出一个平均值,用这个值作为决定何时重新抓取的依据。
(3)聚类抽样策略。
前面提到的两种更新策略都有一个前提:需要网页的历史信息。这样就存在两个问题:第一,系统要是为每个系统保存多个版本的历史信息,无疑增加了很多的系统负担;第二,要是新的网页完全没有历史信息,就无法确定更新策略。
这种策略认为网页具有很多属性,类似属性的网页,可以认为其更新频率也是类似的。要计算某一个类别网页的更新频率,只需要对这一类网页抽样,以它们的更新周期作为整个类别的更新周期,基本思路如图 2-10 所示。
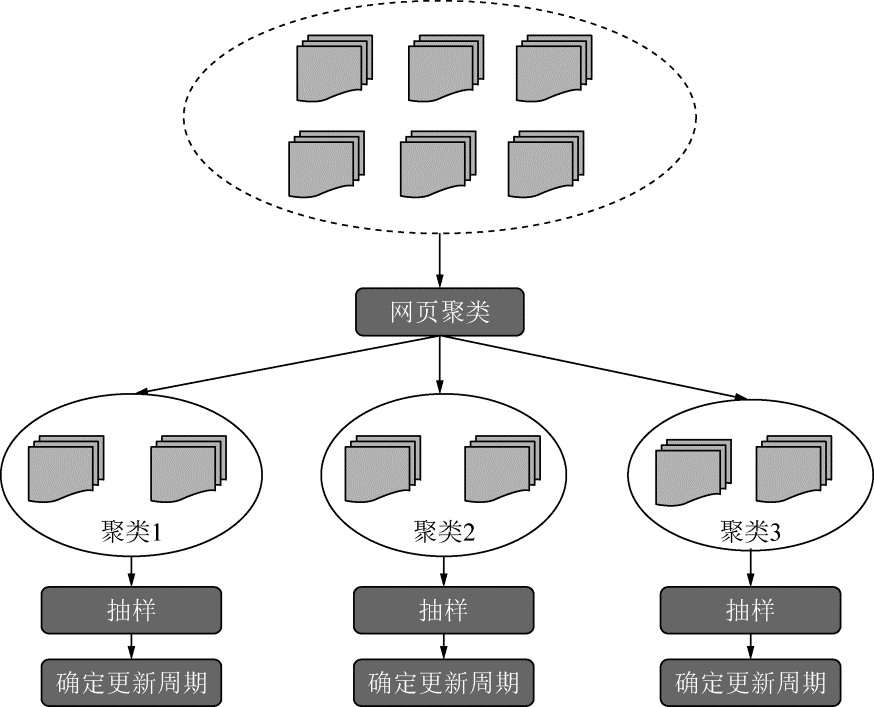
图 2-10 网页聚类抽样策略
一般来说,抓取系统需要面对的是整个互联网上数以亿计的网页。单个抓取程序不可能完成这样的任务,往往需要多个抓取程序一起来处理。一般来说,抓取系统往往是一个分布式的三层结构,如图 2-11 所示。
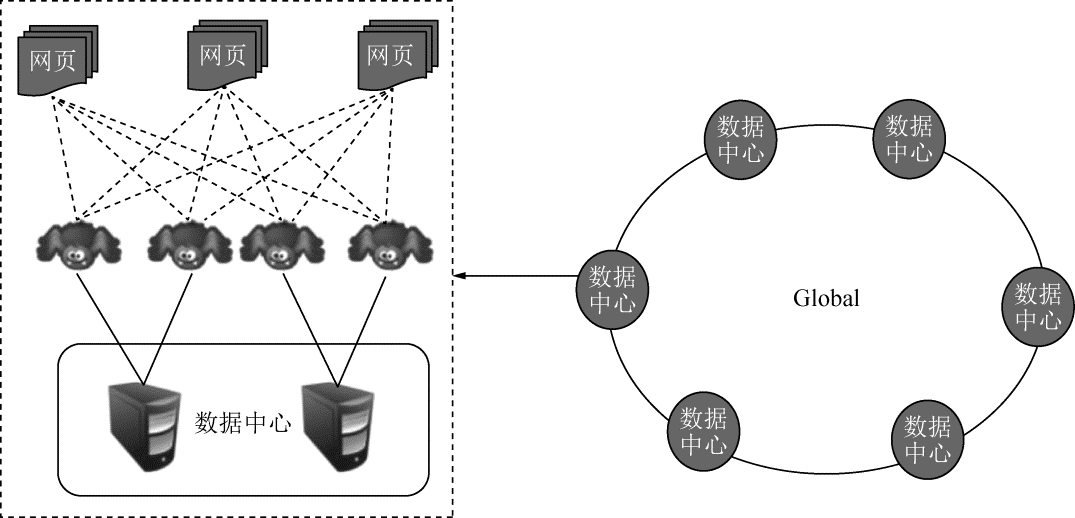
图 2-11 分布式结构
最下面一层是分布在不同地理位置上的数据中心,在每个数据中心里有若干台抓取服务器,而每台抓取服务器上可能部署了若干套爬虫程序,这样就构成了一个基本的分布式抓取系统。
对于一个数据中心内的不同抓取服务器,协同工作的方式有以下两种:
1.主从式(Master-Slave)
主从式的基本结构如图 2-12 所示。
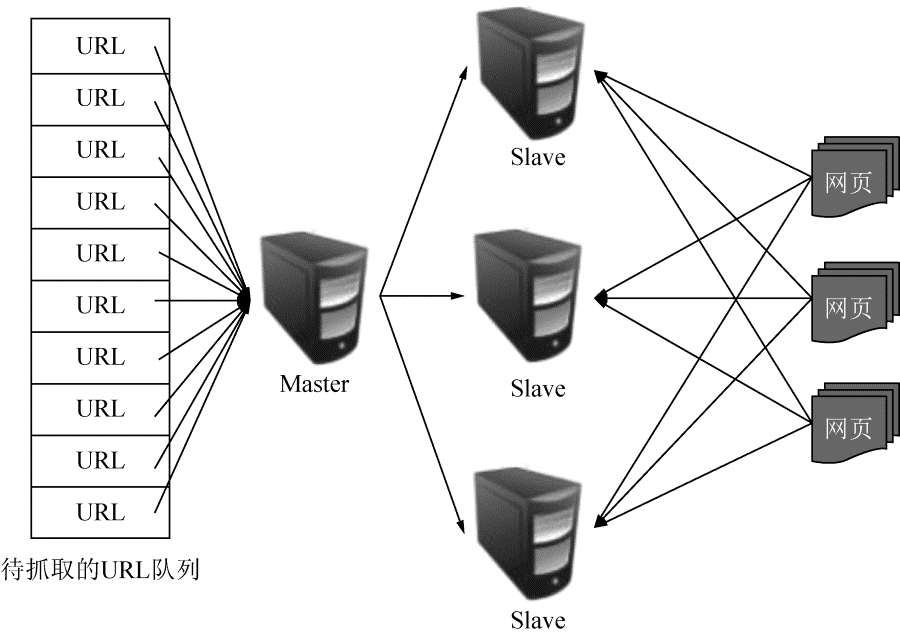
图 2-12 主从式结构
对于主从式而言,有一台专门的 Master 服务器来维护待抓取 URL 队列,它负责每次将 URL 分发到不同的 Slave 服务器上,而 Slave 服务器则负责实际的网页下载工作。Master 服务器除了维护待抓取的 URL 队列及分发 URL 之外,还要负责调解各个 Slave 服务器的负载情况,以免某些 Slave 服务器过于“清闲”或者“劳累”。这种模式下,Master 往往容易成为系统瓶颈。
2.对等式(Peer to Peer)
对等式的基本结构如图 2-13 所示。
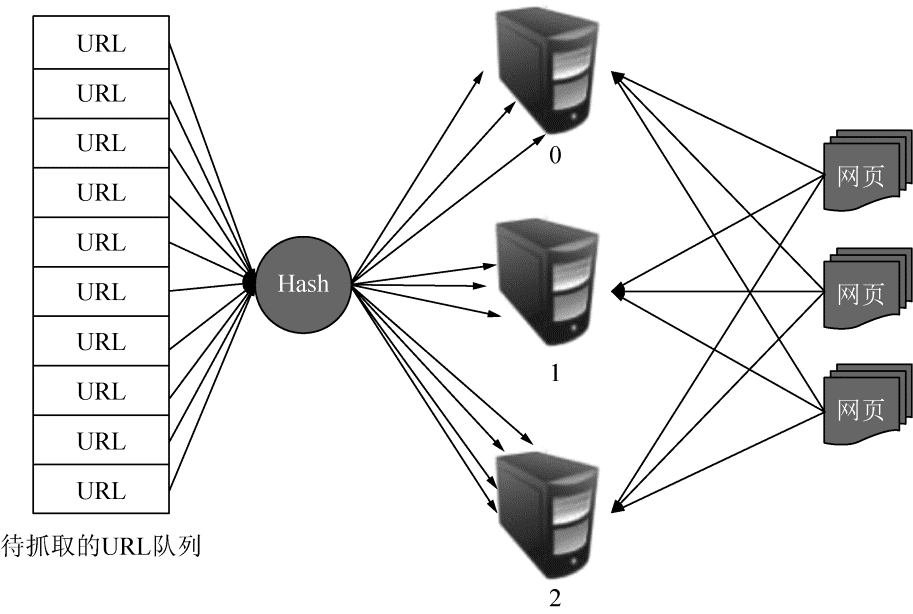
图 2-13 对等式结构
在这种模式下,所有的抓取服务器在分工上没有不同。每一台抓取服务器都可以从待抓取的 URL 队列中获取 URL,接着求出该 URL 的主域名的 Hash 值 H,然后计算 H mod m(其中 m 是服务器的数量,以图 2-13 为例,m 为 3),计算得到的数就是处理该 URL 的主机编号。
举例:假设对于 URL www.baidu.com,计算其 Hash 值 H=8,m=3,则 H mod m=2,因此由编号为 2 的服务器进行该链接的抓取。假设这时候是 0 号服务器拿到这个 URL,那么它会将该 URL 转给服务器 2,由服务器 2 进行抓取。
这种模式有一个问题,当有一台服务器死机或者添加新的服务器时,所有 URL 的哈希求余的结果都要变化。也就是说,这种方式的扩展性不佳。针对这种情况,又有一种改进方案被提出来,这种改进的方案是用一致性哈希法来确定服务器分工,其基本结构如图 2-14 所示。
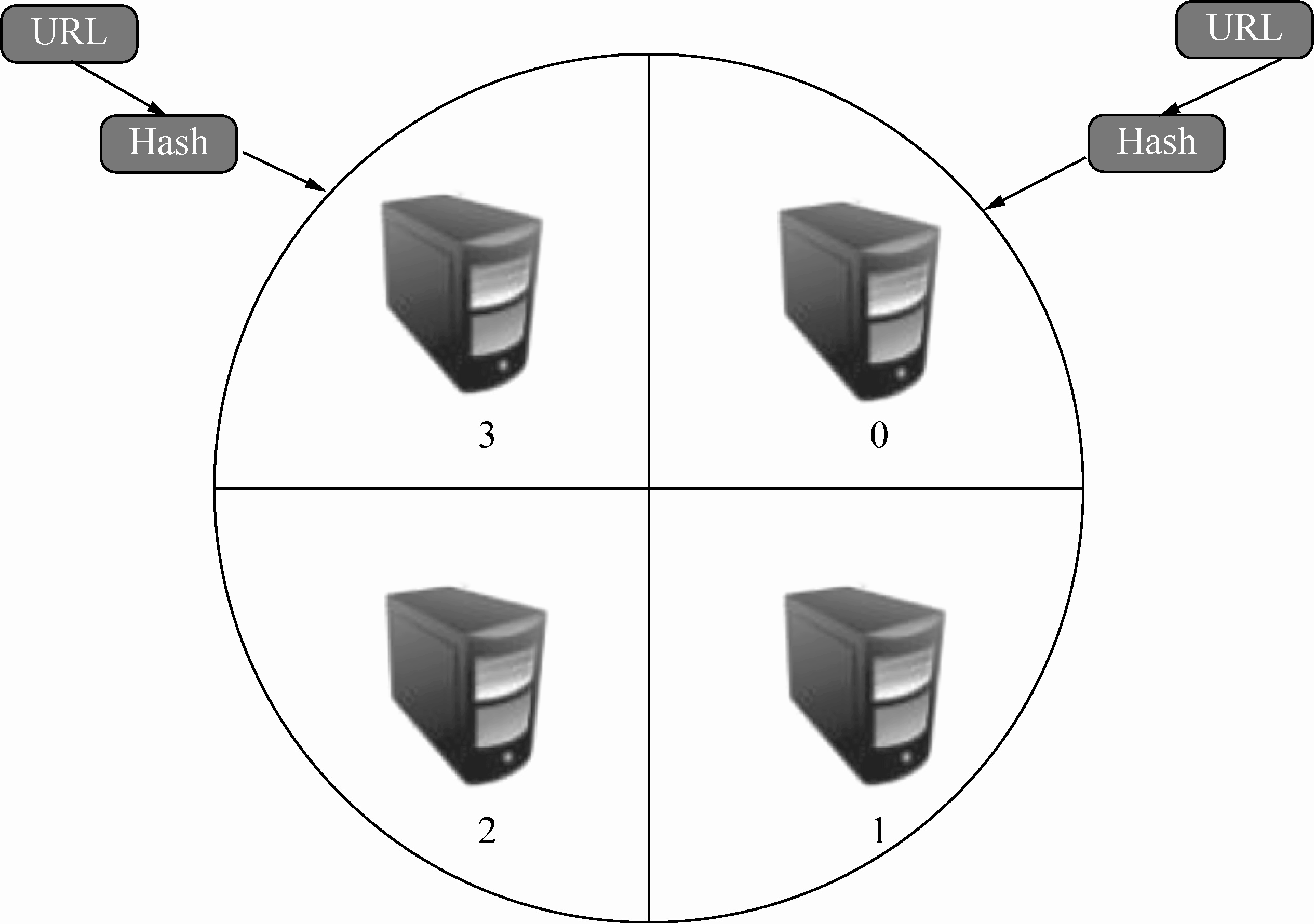
图 2-14 一致性哈希法
一致性哈希法将 URL 的主域名进行哈希运算,映射为一个范围在 0~232 之间的某个数,然后将这个范围平均地分配给 m 台服务器,根据 URL 主域名哈希运算的值所处的范围来判断由哪台服务器进行抓取。
如果某一台服务器出现问题,那么本该由该服务器负责的网页则按照顺时针顺延,由下一台服务器进行抓取。这样,即使某台服务器出现问题,也不会影响其他的工作。
2.9 爬虫框架介绍
目前常见的 Python 爬虫框架有很多,如 Scrapy、XPath、Crawley、PySpide 和 Portia 等。本节主要介绍 Scrapy 和 XPath 两种主流爬虫框架。
2.9.1 Scrapy 介绍
Scrapy 是一套基于 Twisted 的异步处理框架,是纯 Python 实现的爬虫框架,用户只需要定制、开发几个模块就可以轻松实现一个爬虫程序,用来抓取网页内容或者图片。如图 2-15 所示为 Scrapy 的基本架构。
这个架构中包含了 Scheduler、Item Pipeline、Downloader、Spiders 及 Engine 这几个组件模块,而图中的箭头线则说明了整套系统的数据处理流程。下面对这些组件进行简单的说明。
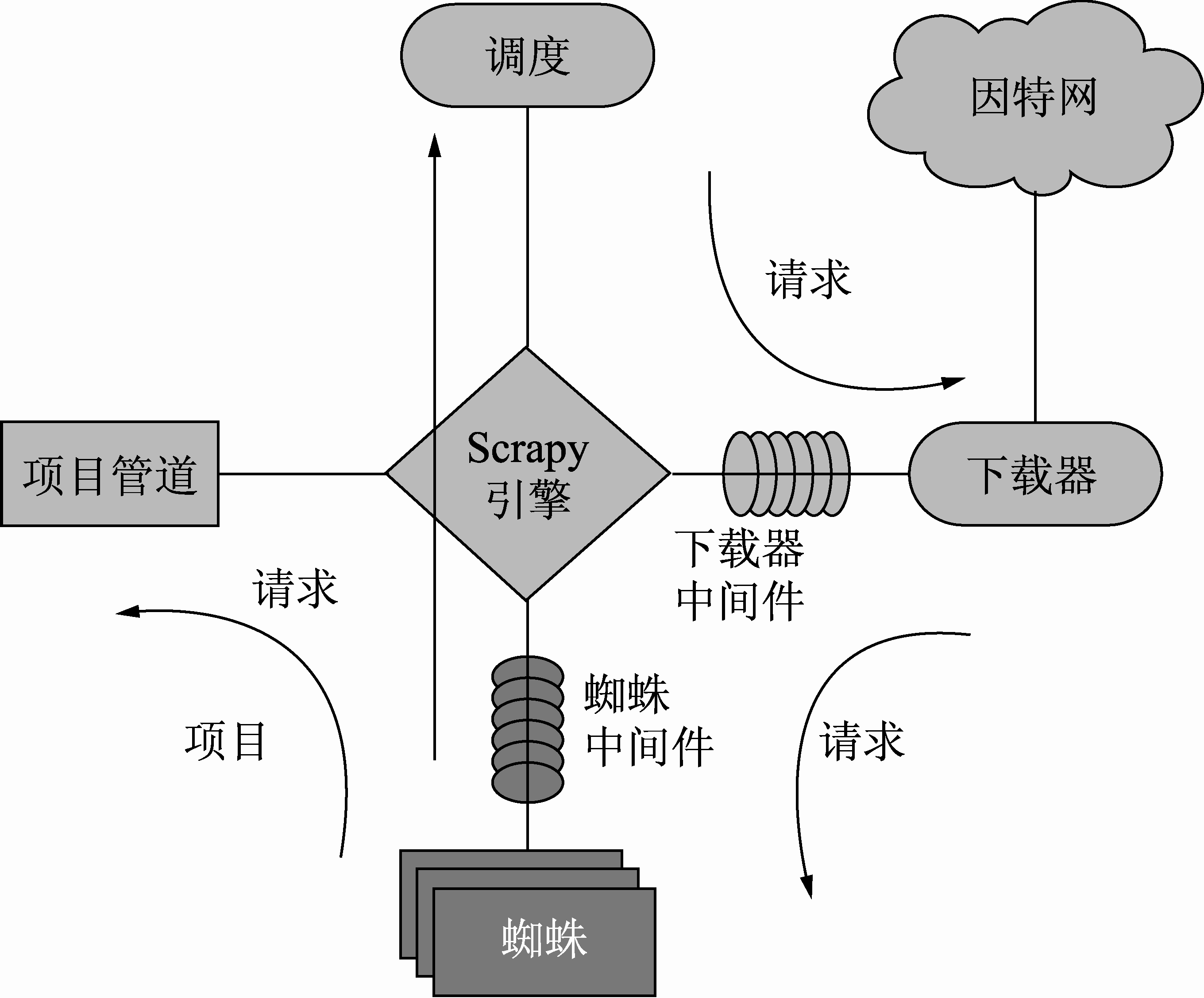
图 2-15 Scrapy 架构
1.Scrapy Engine(Scrapy 引擎)
Scrapy 引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发。
2.Scheduler(调度)
调度程序从 Scrapy 引擎接受请求并排序列入队列,并在 Scrapy 引擎发出请求后返还给它们。
3.Downloader(下载器)
下载器的主要职责是抓取网页并将网页内容返还给蜘蛛(Spiders)。
4.Spiders(蜘蛛)
蜘蛛是由 Scrapy 用户自己定义用来解析网页并抓取指定 URL 返回的内容的类,每个蜘蛛都能处理一个域名或一组域名。换句话说,Spiders 就是用来定义特定网站的抓取和解析规则。
蜘蛛的整个抓取流程(周期)是这样的:
(1)获取第一个 URL 的初始请求,当请求返回后调取一个回调函数。第一个请求是通过调用 start_requests()方法来实现。该方法默认从 start_urls 中的 URL 中生成请求,并执行解析来调用回调函数。
(2)在回调函数中,可以解析网页响应并返回项目对象和请求对象或两者的迭代。这些请求也包含一个回调,然后被 Scrapy 下载,再由指定的回调处理。
(3)在回调函数中,解析网站的内容,同程使用的是 XPath 选择器(也可以使用 BeautifuSoup、lxml 或其他程序),并生成解析的数据项。
(4)从蜘蛛返回的项目通常会进驻到项目管道。
5.Item Pipeline(项目管道)
项目管道主要负责处理蜘蛛从网页中抽取的项目,它的主要任务是清洗、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。每个项目管道的组件都是由一个简单的方法组成的 Python 类。它们获取了项目管道并执行管道中的方法,同时还需要确定是在项目管道中继续执行还是直接丢掉不处理。
项目管道通常执行的过程是:
(1)清洗 HTML 数据。
(2)验证解析到的数据(检查项目是否包含必要的字段)。
(3)检查是否是重复数据(如果重复就删除)。
(4)将解析到的数据存储到数据库中。
6.Downloader Middlewares(下载器中间件)
下载器中间件是位于 Scrapy 引擎和下载器之间的钩子框架,主要处理 Scrapy 引擎与下载器之间的请求及响应。它提供了一个自定义代码的方式来拓展 Scrapy 的功能。它是轻量级的,对 Scrapy 尽享全局控制的底层的系统。
7.Spider Middlewares(蜘蛛中间件)
蜘蛛中间件是介于 Scrapy 引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。它提供一个自定义代码的方式来拓展 Scrapy 的功能。蜘蛛中间件是一个挂接到 Scrapy 的蜘蛛处理机制的框架,可以插入自定义的代码来处理发送给蜘蛛的请求,以及返回蜘蛛获取的响应内容和项目。
8.Scheduler Middlewares(调度中间件)
为了进一步提高蜘蛛性能,有的蜘蛛在 Scrapy 引擎和调度中间件之间还可以加上调度中间件,主要工作是处理从 Scrapy 引擎发送到调度的请求和响应。它提供了一个自定义的代码来拓展 Scrapy 的功能。
总之,Scrapy 就是基于上述这些组件工作的,而 Scrapy 的整个数据处理流程由 Scrapy 引擎进行控制,其主要的运行过程为:
(1)引擎打开一个域名,此时蜘蛛处理这个域名,并让蜘蛛获取第一个爬取的 URL。
(2)引擎从蜘蛛那里获取第一个需要爬取的 URL,然后作为请求在调度中进行调度。
(3)引擎从调度那获取接下来进行爬取的页面。
(4)调度将下一个爬取的 URL 返回给引擎,引擎将它们通过下载中间件发送到下载器中。
(5)当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎上。
(6)引擎收到下载器的响应并将它通过蜘蛛中间件发送给蜘蛛进行处理。
(7)蜘蛛处理响应并返回爬取到的项目,然后给引擎发送新的请求。
(8)引擎将抓取到的项目发送给项目管道,并向调度发送请求。
(9)系统重复第(2)步后面的操作,直到调度中没有请求,然后断开引擎与域之间的联系。
2.9.2 XPath 介绍
Xpath 是一种用来确定 XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。XPath 提出的初衷是将其作为一个通用的、介于 XPointer 与 XSLT 间的语法模型,但是由于 XPath 用起来非常便捷,于是后来被开发者当作小型的查询语言来使用。
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和常规的计算机文件系统中看到的表达式非常相似。路径表达式是从一个 XML 节点(当前的上下文节点)到另一个节点或一组节点的书面步骤顺序。这些步骤以“/”字符分开,每一步有 3 个构成部分:
轴描述(用最直接的方式接近目标节点);
节点测试(用于筛选节点位置和名称);
节点描述(用于筛选节点的属性和子节点特征)。
一般情况下,使用简写后的语法。虽然完整的轴描述是一种更加贴近人类语言利用自然语言的单词和语法来书写的描述方式,但是相比之下也更加冗余。
利用 Xpath 爬取网页数据,一般有以下 4 步骤。
(1)导入模块:
(2)获取源代码:
(3)利用 Xpath 提取感兴趣的内容
(4)显示数据。
图书简介:https://item.jd.com/12623592.html?dist=jd

相关阅读
Python数据挖掘与机器学习实战(一):Python语言优势及开发工具
Python数据挖掘与机器学习实战(二):Python语言简介
Python数据挖掘与机器学习实战(三):网络爬虫原理与设计实现
Python数据挖掘与机器学习实战(四):用 Python 实现多元线性回归
Python数据挖掘与机器学习实战(五):基于线性回归的股票预测
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 1 条评论