

伴随着万物互联的趋势,当今各种应用场景的数据体量都在迅速膨胀。不但传统意义上的大数据分析场景在迅速扩展范围,在线业务交易系统所承载的数据规模也在迅速向 BigData scale 迈进。用更合理的成本支撑更大规模的业务数据流量是 TiDB 一直在努力解决的问题,更好的匹配 TiDB 成本和所承载数据的价值是扩大 TiDB 应用场景的关键因素。数据总价值超越 TiDB 成本越高,TiDB 为业务创造的价值越大。
数据价值和 TiDB 成本的匹配在从前就有过许多的讨论,并且 TiDB 已经在分级存储方向做了诸多的探索,充分利用更低成本的介质放置性能要求相对宽松的冷数据。除了从降低单位数据成本角度出发降低成本之外,我们也可以通过提升数据价值密度的方式获得数据价值和存储的优化匹配,将 TiDB 的能力用于存储最有价值的数据上。
在许多应用场景中数据价值同时间有着非常强的相关性,数据的价值随着时间的推移会迅速贬值导致存储收益越来越低。考虑到这种应用场景的普遍性,我们在 TiDB Hackathon 2020 中尝试为 TiDB 引入 TTL 表,让 TiDB 能够利用时间维度对数据进行自动化的生命周期管理。利用数据自动蒸馏的机制让 TiDB 的每一份资源投入都应用在高度萃取的高价值新鲜数据上。
技术背景
Time To Live 是大家非常熟悉的能力,广泛存在于各类缓存和存储类系统中,如 Redis、RocksDB 和 MyRocks 等等。同这些系统类似,TiDB 中的 TTL 表能够在无用户干预的情况下自动管理写入数据的生命周期,在数据写入时间超过设定的过期阈值后自动过期并回收占用的资源。这种自动化的机制不但能够将用户从乏味的数据生命周期管理中解放出来,还能够充分利用系统内部的工作机制优化数据删除路径,消耗更少的资源,更快的回收更多的数据。
在综合考虑 TiDB 的运作机制和用户使用复杂度后,我们为数据表增加了过期时间和过期颗粒度两个设置。用户可以从「行」和「分区」过期两种颗粒度中进行选择,如果对数据过期时间精确度要求不高可以选择按「分区」方式过期,获得更高的资源回收效率。
TTL 表定义
这两种 TTL 表的定义非常简单,只需参考下面的样例在建表时提供相应的过期时间设置并选择期望的数据过期颗粒度即可。由于两种颗粒度背后实现的机制不同,使用 ALTER TABLE 我们只能将一个现有的 TiDB 表转化为「行」颗粒度的 TTL 表,具体原因在后面的实现机制部分再进行介绍。
「行」颗粒度 TTL 表 DDL
「分区」颗粒度 TTL 表 DDL
实现方式
「行」颗粒度 TTL 表
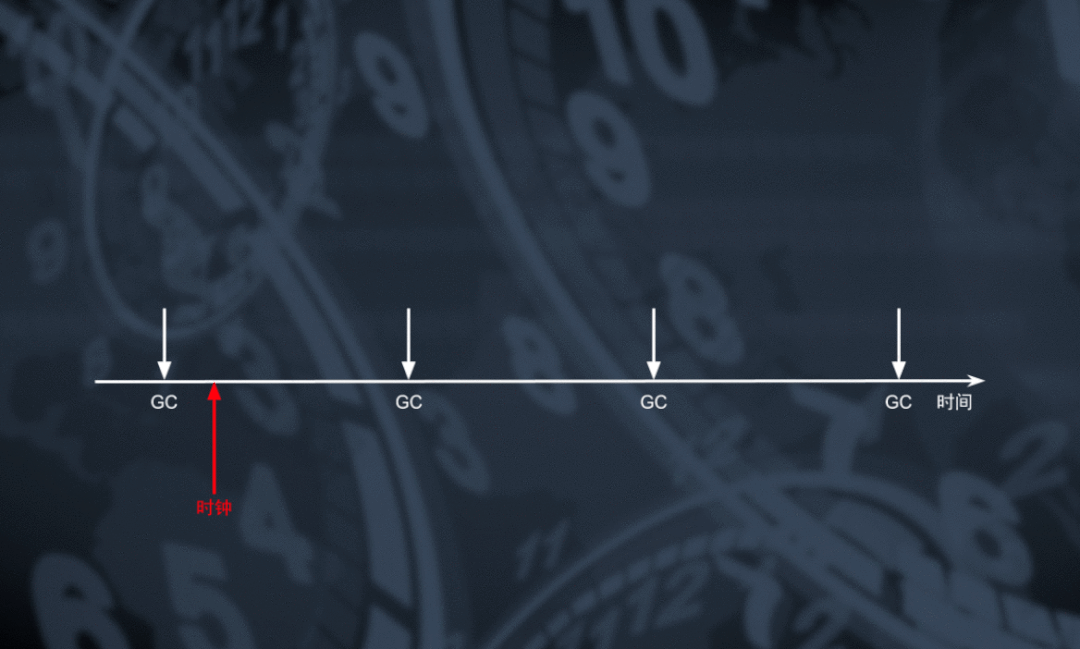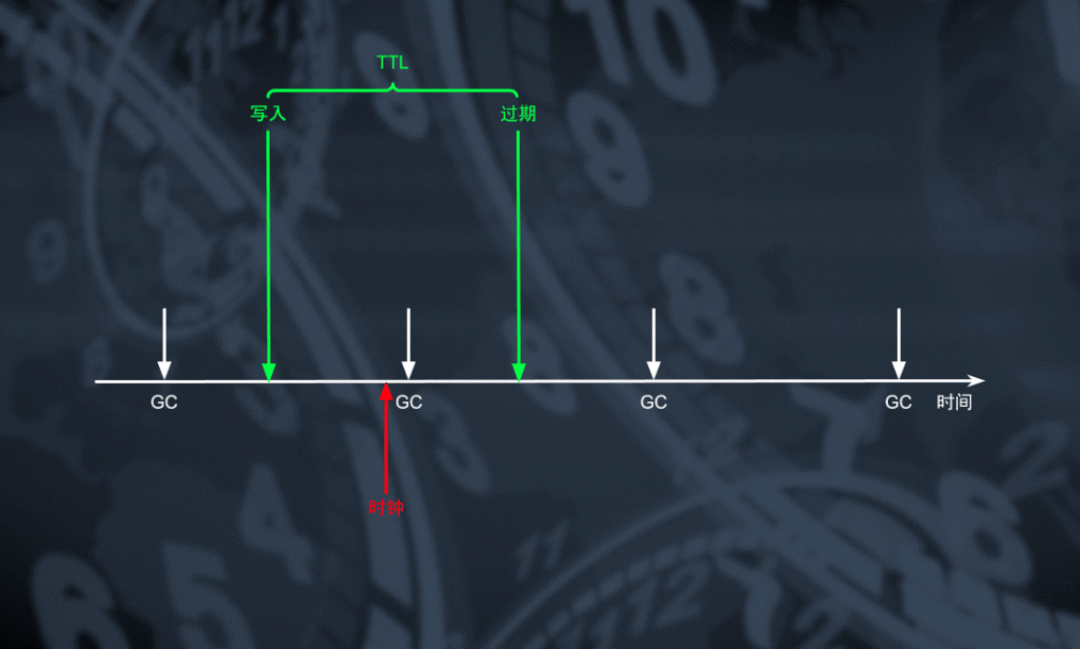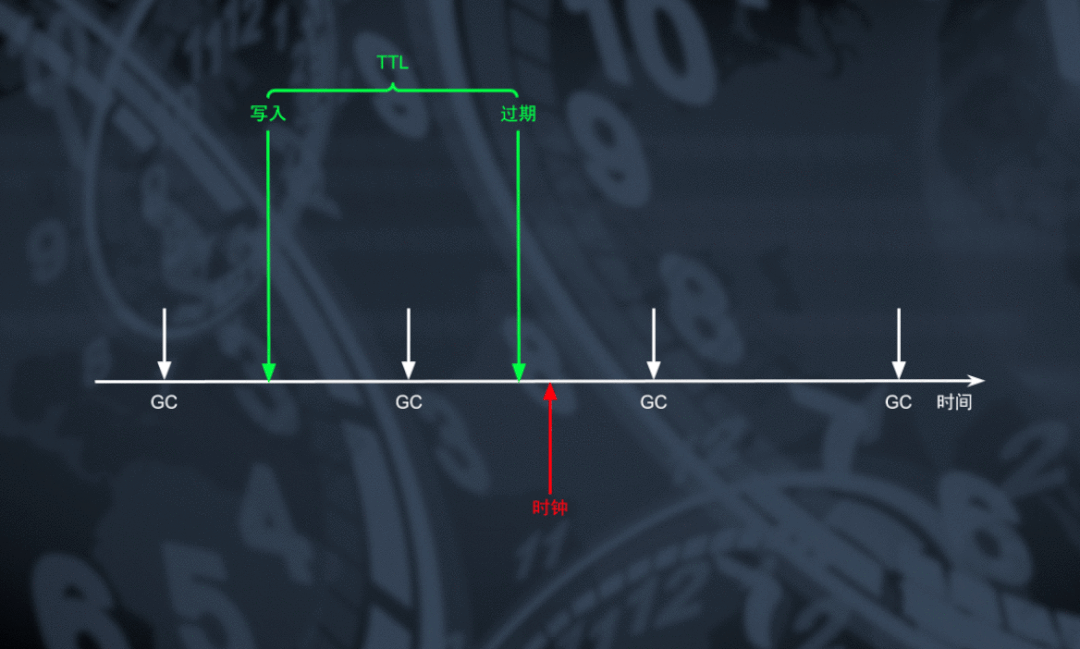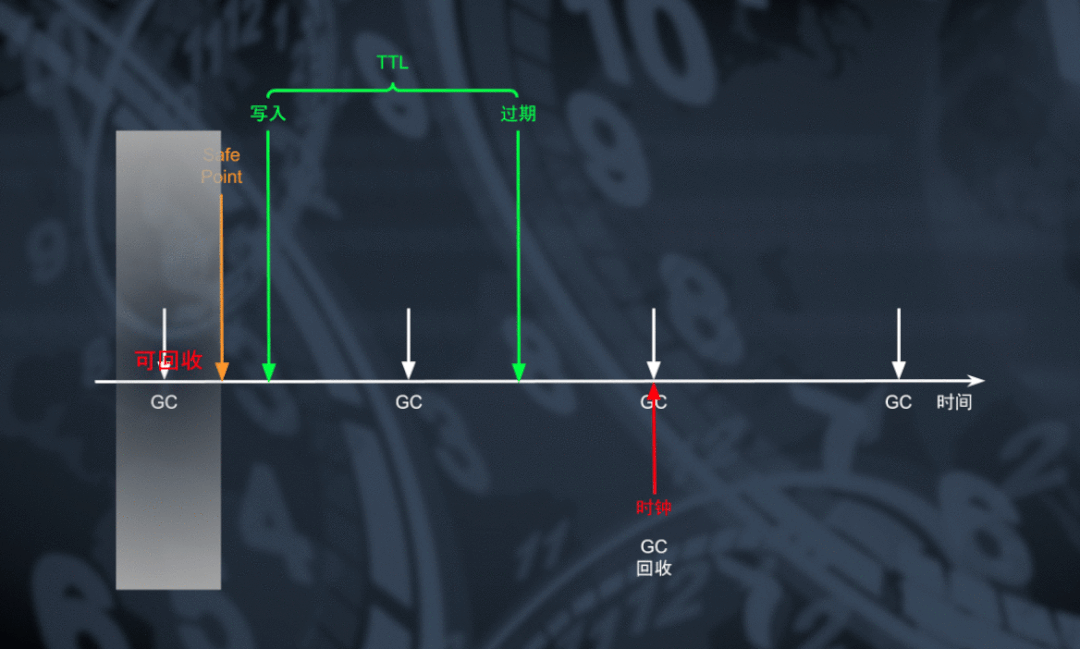
当 TTL 表工作与「行」颗粒度模式时,我们可以利用 TiDB 周期驱动 TiKV 进行 MVCC GC 的时机对过期的数据以「行」为单位进行回收。为了将过期策略下发到 TiKV 上,我们将所有 TTL 表对应的数据范围(key range)连同他们的 TTL 设定一起随 GC 任务下发到 TiKV 中。在 GC 过程中对于存在于 TTL key range 中的数据,能够根据 MVCC 信息计算得到数据的存活时长,对于那些 MVCC GC 有效但存活时间超过 TTL 阈值的数据可以在 GC 过程中进行删除回收空间。
需要注意的是目前绝大多数 TiDB 表的存储布局都是非聚簇的(non-clustered),如果主键索引或其它的二级索引同主数据之间删除进度不一致,则会导致在主数据删除的情况下索引数据仍然可见导致的回表失败。为了解决这个问题我们将 TTL 表拆分成数据和索引两个范围(key range),将数据的 TTL 设定为索引 TTL 加最近两轮 GC 的时间间隔。通过这种机制我们能够确保所有的数据比索引多存活至少一个 GC 周期,从而避免数据不一致导致的回表问题。除了利用 GC 时机对过期数据进行删除之外,Compaction 阶段也很适合对已过期的数据进行回收。
由于 Hackathon 时间紧张我们仅实现了 GC 回收机制,未来在 TiDB 上处于产品级状态的 TTL 表一定会采用更加优化的实现。
「分区」颗粒度 TTL 表
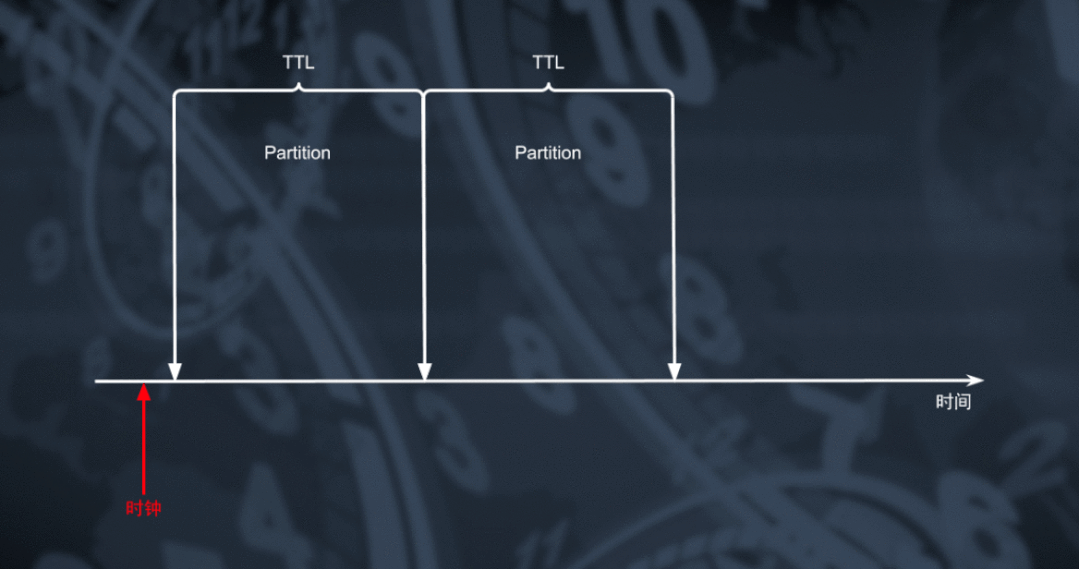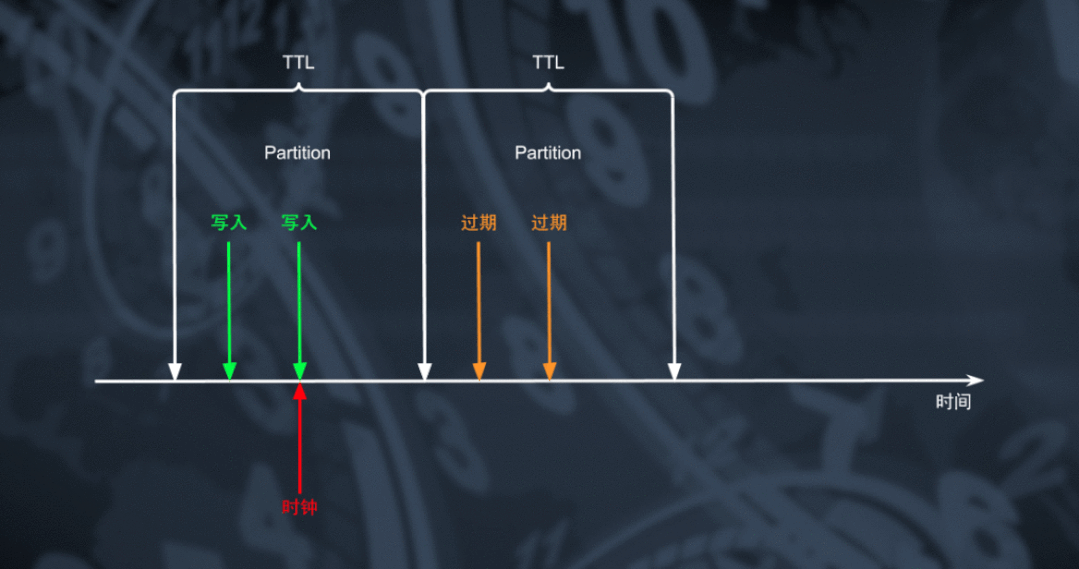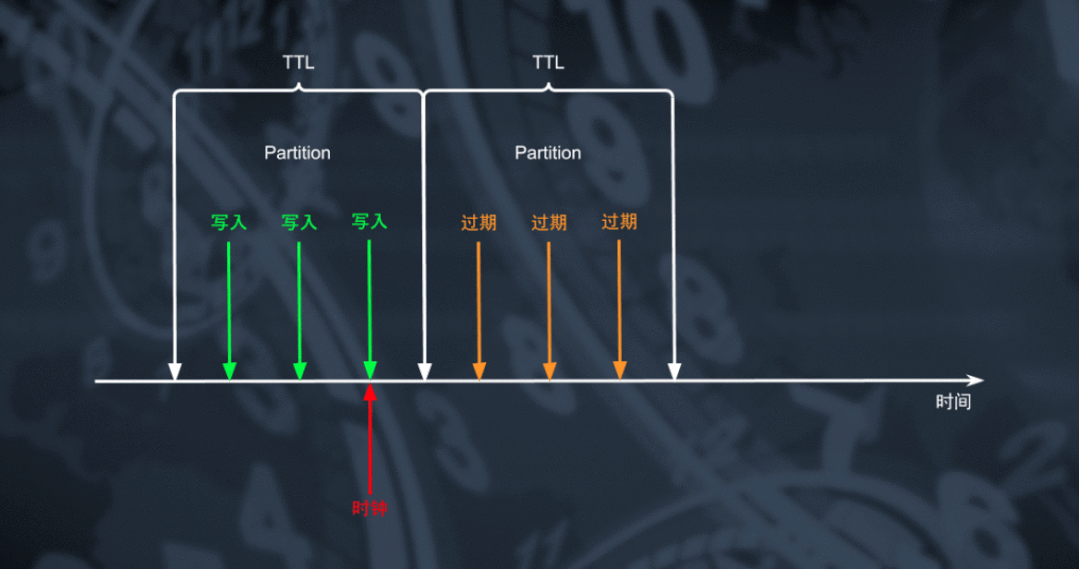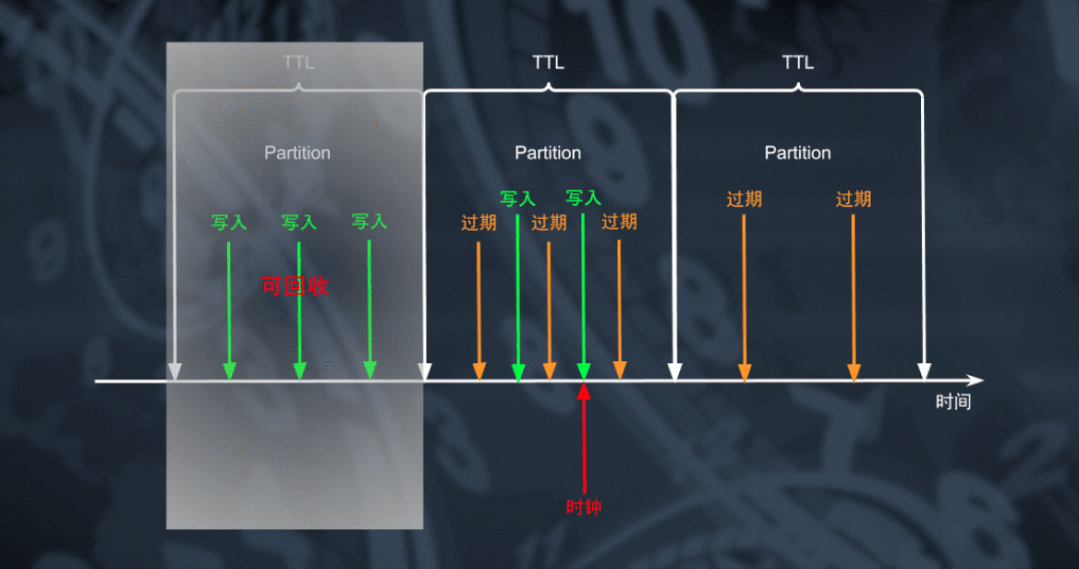
对于数据库来说删除大量数据是一个从资源消耗角度看非常昂贵的操作,采用周期 GC 或 Compaction 的机制对数据删除能够极大的降低资源上的消耗。但大家可能想到为什么不能够利用 TRUNCATE 的机制实现更高效率的数据过期呢?
通过将 TTL 表实现为一个用户不可感知的特殊分区表,利用通过滑动窗口切换分区的方式我们能够将数据以较粗的颗粒度按时间顺序放置在多个物理分区中。通过周期轮转的方式创建新分区并对最老的一个分区进行 TRUNCATE 和删除操作,处于最老分区的所有过期数据能够以非常低的代价迅速删除。对于这种特殊的删除操作,RocksDB 能够直接将对应范围的数据逻辑删除转化为物理文件删除操作,达成低成本快速回收空间的目标。
在理解了「分区」颗粒度 TTL 表的工作原理之后,大家应该不难理解由于目前 TiDB 并不允许「普通表」同「分区表」以及不同类型的「分区表」之间进行自由的转换,所以任何现有的 TiDB 表都不能被转化为「分区」颗粒度的 TTL 表。
应用场景
为了让大家更好的理解 TTL 表的适用范围,我们结合曾经遇到的一些实际问题对一些开源项目进行了改造让它们支持以 TiDB 作为存储介质,并利用 TTL 表作为存储让存储在这些系统中的数据在系统无感知的情况下自动维持数据的生命周期。
Apache Kylin
维度报表在大数据场景中被广泛的应用于各种决策的支撑,具有数据价值高、时效性强的特点。Kylin 以 MOLAP 的方式对原始数据进行预处理,提供快速的数据切片(slicing)、切块(dicing)、上卷(rollup)和下钻(drill down)等分析能力。在这样的应用场景下,维度报表的数据规模同维度数量和基数正相关,在许多场景下数据规模远超单机数据库所能支撑的数据上限。随着时间的推移对历史报表数据进行灵活决策分析的需求会迅速减少,因此相应数据也会随着分析需求的减少而迅速贬值。维度报表的数据往往一周甚至更短的时间就不再具备即席(Adhoc)分析价值,需要对大量无价值历史数据进行简易高效的清理。利用 TTL 表存储数据不但能够自动维护维度报表数据的生命周期,还能够充分利用 TiDB 索引查询能力简化 Kylin 的实现并且能够通过统一管理报表数据和元数据进一步简化 Kylin 的管理成本。
Jaeger Tracing
Jaeger Tracing 实现了 OpenTracing 开放标准并且提供了它的下一代标准 OpenTelemetry 的实验性支持。目前 Jaeger 官方支持的存储系统包括 Cassandra 和 ElasticSearch,除此之外还提供了 gRPC 插件方便用户接入自己的存储系统。我们利用插件机制为 Jaeger 带来了 TiDB 存储后端的支持,在 TTL 表的帮助下不但能够充分利用底层存储 TiKV 提供的高吞吐和扩展性,还能够自动化的管理历史追踪数据的生命周期降低系统管理成本。
Kubernetes Events 长期存储
K8s 的 event 对象记录了集群中所发生的各种事件,这些事件在分析排查异常现象或者操作审计方面都非常有价值。在 K8s 集群规模较大且变更频繁时我们通常会选择将集群事件存储在独立的 etcd 集群,但受限于 etcd 存储空间仍然无法在频繁部署更新的场景下记录较长时间内的 K8s 集群事件。选择将事件存储在 TiDB 中不但可以带来更大的存储空间存储更长时间的记录,还能够利用 TiDB 的二级索引能力为存储的集群事件带来灵活且高性能的查询能力。在 TTL 表的帮助下,存储在 TiDB 集群中的历史事件能够自动过期回收空间。
MQTT QoS 1 & 2 消息持久化
MQTT 被广泛应用于移动互联网和 IoT 场景中各种实时消息的上行和下发场景。考虑到移动设备和 IoT 设备网络接入质量的波动性,需要将确保投递的 QoS 1 & 2 的消息持久化存储来应对客户端长时间不在线的情况。当持久化存储系统内置数据过期支持时,能够很好的适配同时具有可靠投递和投递时效性要求的应用场景,例如新闻热点、AMBER Alert、天气预报等等。在 Hackathon 中我们尝试将一个流行的 MQTT Broker 进行改造,为其引入了 MySQL 存储后端支持。在 TTL 表的帮助下业务无需对数据的生命周期进行任何管理,数据能够按照用户设置的 Retention 周期自动过期删除。
在高手云集创意无限的 TiDB Hackathon 中,许多项目的创新性和实用性都远超 TTL 表。虽然 TTL 表没能获得奖项,但我们相信它背后试图解决的问题具有现实的意义和普适性。希望后续继续投入精力完善 TTL 表的设计和实现,同时也欢迎大家来一起参与 TTL 表的需求和设计 RFC(https://github.com/pingcap/tidb/pull/22763) 讨论,推动社区对 TTL 功能的认可并最终将它带到 TiDB 中更好的服务大家。
头图:Unsplash
作者:孙晓光
原文:https://mp.weixin.qq.com/s/59gcKir0qLeAu_m4033LHA
原文:「过期不候」,有生命周期的 TiDB 数据表
来源:PingCAP - 微信公众号 [ID:pingcap2015]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论