

2019 年,微软开源了 Dapr 项目。2021 年,蚂蚁参照 Dapr 思想开源了 Layotto 项目。如今,蚂蚁已落地 Layotto,服务了很多应用。从理想落地到现实的过程中,我们遇到了不少问题,也对项目做了很多改变。回过头再看,如何看待 Dapr、Layotto 这种多运行时架构?我们能从中学到什么?
本文将从以下几个方面,分享蚂蚁在落地多运行时架构之后的思考:
如何看待“可移植性”
多运行时架构能带来哪些价值
与 Service Mesh、Event Mesh 的区别
如何看待不同的部署形态
1. 快速回顾
如果你熟悉 Multi-Runtime、Dapr 和 Layotto 的概念,可以跳过这一章节,直接进入下一章节。
1.1 快速回顾:什么是 Multi-Runtime 架构?
Multi-Runtime 是一种服务端架构思路,如果用一句话来概括,就是把应用里的所有中间件挪到 Sidecar 里,使得“业务运行时”和“技术运行时”分离开。
更详细的解释如下:
首先来看 Service Mesh,和传统 RPC 框架相比,Service Mesh 的创新之处在于引入了 Sidecar 模式。Service Mesh 只解决了服务间通讯的需求,而现实中的分布式应用存在更多需求,比如“协议转换”、“状态管理”等。Multi-Runtime 架构提出将各种各样的分布式能力外移到独立 Runtime,最后和应用 Runtime 共同组成微服务,形成所谓的“Multi-Runtime”(多运行时)架构。
具体细节可以详阅《Multi-Runtime Microservices Architecture》和《Mecha:将 Mesh 进行到底》。
1.2 哪些项目实现了 Multi-Runtime 架构?
Dapr
Dapr 的全称是“Distributed Application Runtime”,即“分布式应用运行时”,是一个由微软发起的开源项目。
Dapr 项目是业界第一个 Multi-Runtime 实践项目,Dapr 的 Sidecar,除了可以和 Service Mesh 一样支持服务间通讯,还可以支持更多的功能,如 state(状态管理)、pub-sub(消息通讯),resource binding(资源绑定,包括输入和输出)。Dapr 将每种功能抽象出标准化的 API(如 state API),每个 API 都有多种实现,比如用户可以面向 state API 编程,但是可以随意切换存储组件,今年用 Redis,明年改成用 MongoDB,业务代码不用改。
如果之前没有接触过 Dapr,更详细的介绍可以阅读《Dapr v1.0 展望:从 Service Mesh 到云原生》这篇文章。
Layotto
Layotto 是由蚂蚁集团 2021 年开源的一个实现 Multi-Runtime 架构的项目,核心思想是在 Service Mesh 的数据面(MOSN)里支持 Dapr API 和 WebAssembly 运行时,实现一个 Sidecar 同时作为 Service Mesh 数据面、多运行时 Runtime、FaaS 运行时。项目地址为:https://github.com/mosn/layotto
以上是本文背景,接下来是本次主题分享。
2. 如何看待“可移植性”:你真的需要这种“可移植性”吗?
社区比较关注 Dapr API 的“可移植性”,但在落地过程中,我们不禁反思:你真的需要这种“可移植性”吗?
2.1 标准化 API 能满足所有需求吗?
数据库领域曾出现过一个有趣的讨论:同一个数据库能否适用于所有场景,满足所有需求?比如,一个数据库能否同时支持 OLAP+OLTP+ACID 等等需求?
今天,我们在建设 Dapr API 的过程中也遇到了有趣的问题:在某个产品领域(比如消息队列),能否定义一套“标准 API”同时适用于所有的消息队列?
当然,这两个问题不能混为一谈:即使是两种不同类型的数据库,比如两个数据库,一个只做 OLAP,另一个只做 OLTP,它们都可以支持 SQL 协议。两个差距那么大的数据库都能用同样的协议,我们有理由相信:在特定领域,设计一个适用于所有产品的“标准 API”是可行的。
可行,但现在还不完全行。
现在的 Dapr API 还比较简单,简单场景足以胜任,但在复杂的业务场景下,做不到“帮助应用 Write once,run on any cloud”。对这个问题,敖小剑老师的文章《死生之地不可不察:论 API 标准化对 Dapr 的重要性》有过详细描述,大意是说:
1. 现在的 Dapr API 比较简单,在生产落地的时候满足不了复杂需求,于是开发者只能添加很多自定义的扩展字段,在 Sidecar 的组件里做特殊处理。比如下面是用 State API 时候的一些自定义扩展字段:

(图片摘自敖小剑老师的文章)
这些自定义的扩展字段会破坏可移植性:如果你换一个组件,新组件肯定不认识这些字段,所以你得改代码。
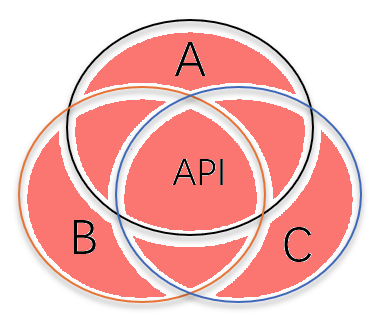
2. 之所以出现这个问题,背后的根本原因是 Dapr API 的设计哲学。社区在设计 Dapr API 时,为了可移植性,设计出的 API 倾向于“功能交集”。比如在设计 Configuration API 时,会考察各种配置中心 A、B、C,如果 A、B、C 都有同一个功能,那么这个功能才会出现在 Dapr API 中:
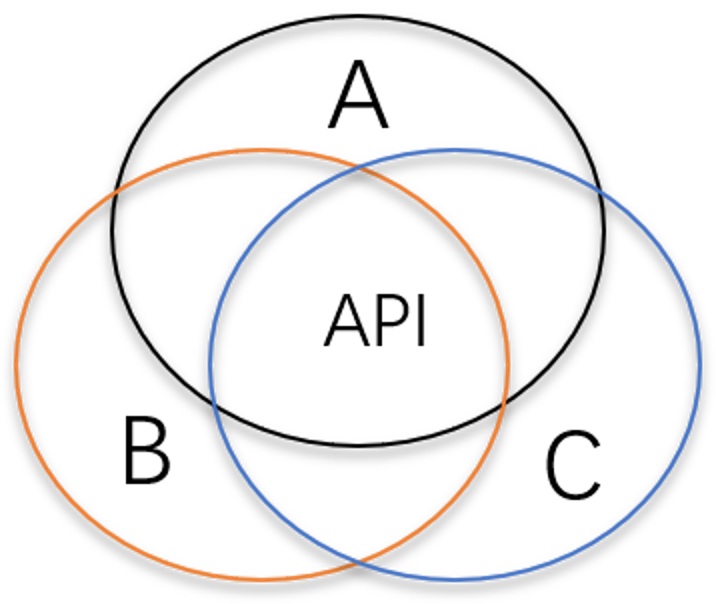
然而,在现实世界中,人们的需求可能是 A 和 B 的交集,B 和 C 的交集(如下图红色部分),而不是 A、B、C 的交集:
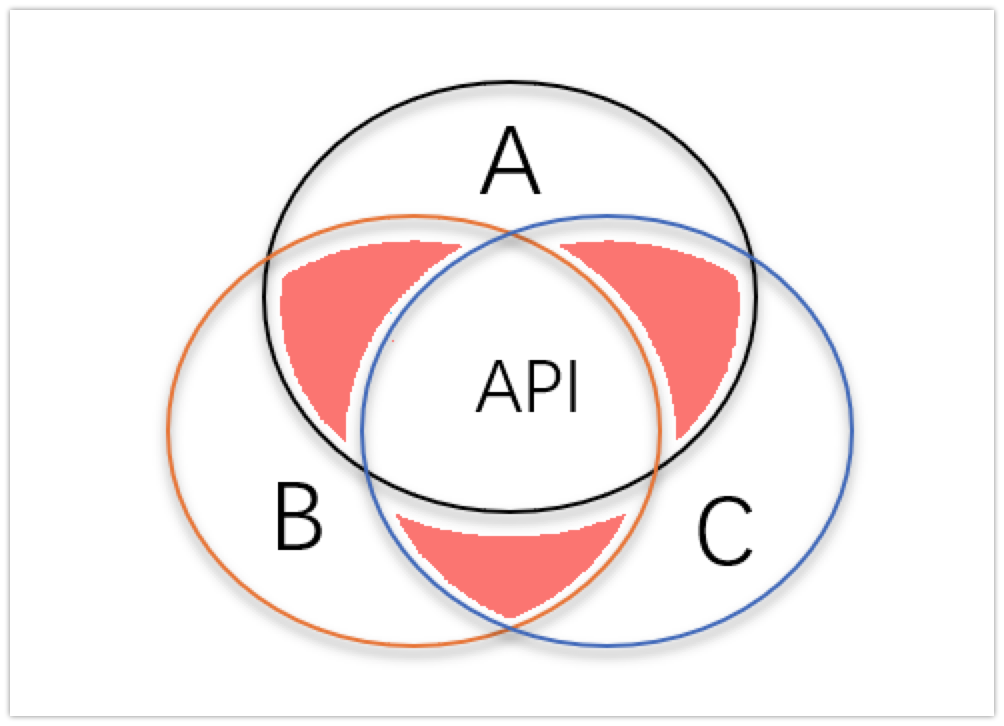
或者更常见的是,用户的需求是“B 的所有功能”,其中必然包括一些 B 独有的功能,Dapr API 无法覆盖:
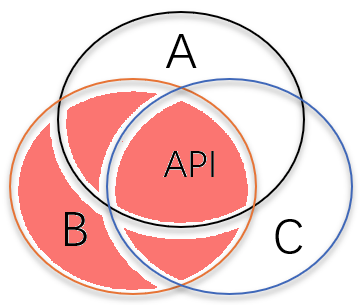
3. Dapr API 有一定的侵入性
Dapr 提供“标准 API”、“语言 SDK”和“Runtime”,需要应用进行适配(这意味着老应用需要进行改造),侵入性比较大。
因此 Dapr 更适合新应用开发(所谓 Green Field),对于现有的老应用(所谓 Brown Field)则需要付出较高的改造代价。但在付出这些代价之后,Dapr 就可以提供跨云跨平台的可移植性,这是 Dapr 的核心价值之一。
这些听起来是解决不了的问题。那怎么办?
2.2 跨云部署时,你真的需要从 Redis 换成 Memcached 吗?
在设计 API 时,常常出现类似的讨论:
A:嘿,这个功能只有 Redis 和 xxx 有,但是 Memcached 和其他存储系统没有。我们该怎么办,要不要把这个功能纳入 API 规范里?
B:如果我们把这个功能纳入 API 里,会有什么问题?
A:那样的话,使用我们 API 的用户就没法从 Redis 迁移到 Memcached 了,这破坏了可移植性!
等一等……你真的需要从 Redis 换成 Memcached 吗?
你真的需要这种“可移植性”吗?
不需要吧!如果你的应用是面向 Redis 编程的,那它天生就能部署到不同的云上,因为每个云环境都有托管 Redis 服务。如果没有这种服务,你可以自己部署一个 Redis,让它有。
而且不止是 Redis,其他开源产品也可以类似操作。
舔狗定理
曾经听过一个很有意思的观点(不是我说的):商业公司们就像舔狗,哪个开源产品有商业机会,商业公司很快就会去跟进,那个产品就会在各种云上出现托管服务。话虽糙,但揭示了一个道理:开源产品的协议天生具有可移植性。
2.3 标准化 API 的价值是限制私有协议
为了让讨论更具体,让我们把应用依赖的基础设施协议划分成两类:可信协议与私有协议。
可信协议
指在某个领域影响力比较大的协议,衡量标准是:有托管服务的云环境 >=k(k 是某个让你有安全感的数字,比如 3,5)
比如 Redis 的协议,基本可以认为是和 SQL 一样的事实标准了,各个云厂商都提供了 Redis 托管服务;再比如 MySQL 协议,各个云厂商都会提供兼容 MySQL 协议的数据库托管服务。

观点 1. 可信协议天生具有可移植性。
没必要担心“万一我以后想换云部署时,没法从 Redis 切换到 Memcached 怎么办”。因为每个云上都有兼容 Redis 的托管服务。
担心要从 Redis 换成别的缓存产品,就像是担心“假如我今天引入了 Sidecar,如果以后 Sidecar 架构不流行了,我要去掉 Sidecar 怎么办”,或者“假如我今天引入了 Spring Cloud,以后其他框架火了,我要换成别的框架怎么办”。那一天当然会出现,但是大部分业务都活不到那一天,如果能,恭喜你,到那时你会有足够的资源做重构。
私有协议
比如闭源产品的协议,或者影响力小的开源产品的协议,衡量标准是:有托管服务的云环境<k。
举个例子,蚂蚁内部的 MQ 是自建 MQ,使用私有协议,业务代码依赖了这种私有协议就不好部署到别的云环境了,所以适合用标准化 API 包一层。
再比如,你在调研接入某个阿里云提供的 MQ,但是发现这个 MQ 的 API 是阿里云独有的,别的云厂商不提供这种服务,如果你害怕被阿里云绑定,最好用标准化 API 把这个私有 MQ API 包一层。
读到这,你应该明白我想说的了:
观点 2. Dapr 标准化 API 的价值是限制私有协议。
题外话:Sky Computing
2021 年,UC Berkeley 发了篇论文,预言云计算的未来是 Sky Computing,大意是说:回看互联网的历史,互联网连接了各种异构网络,对用户暴露出一个统一的网络,用户面向这个网络编程不需要关心具体每个异构网络的细节;今天不同云厂商的环境有差异,像极了互联网出现之前“各立山头”的状态,为了让用户更方便,我们可以设计一个“互联云”,连接各种异构云环境,屏蔽差异,只对用户暴露统一的抽象。连接不同云,可以叫“空计算”。
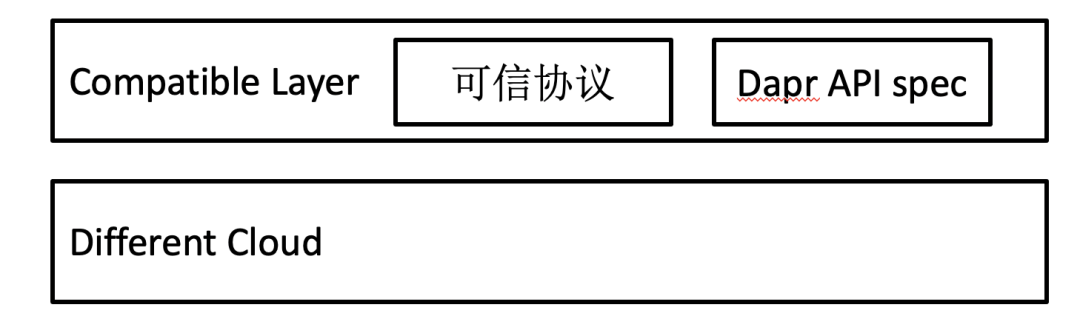
那怎么实现呢?作者提出了 3 层概念模型,最基础的第一层是“兼容层”,负责抽象不同云服务,让应用能够不改代码部署在不同云上。作者认为,开源软件在各个云上都有托管服务,所以可以把不同开源软件整合成一个平台,形成“兼容层”,并且现在已经有项目在这么做了,比如 Cloud Foundry。
在“兼容层”之上,作者认为应该还有“Intercloud 层”和“Peering 层”,感兴趣的可以阅读原文。
2.4 我们需要什么样的“可移植性”
题外话:聪明的计算机科学家
计算机科学中有一种思想:如果一个问题太难了解决不了,那就放宽假设,弱化需求。用大白话讲就是:如果一个问题太难了解决不了,那就先解决一些更简单的问题。这样的例子很多:
比如实现数据库事务的“隔离性”会导致性能很差,只能在实验室环境使用,无法用在现实世界,于是人们提出“弱隔离性”,罗列出“读提交”,“可重复读”之类的“弱隔离级别”,越弱的问题越好解决;
比如在现实世界中,求解 NP-Hard 问题的最优解太慢了,不可行,于是人们提出,放弃追求最优解,只要能保证算法给出的结果在“可以承受的范围内”就行,于是有了“近似算法”;如果这也太难了,那就用玄学算法——“启发式算法”;
比如想实现“对业务透明”的分布式事务比较难,要付出很多代价,于是人们就提出放弃“对业务透明”,于是就有了 TCC 和 Saga;……
既然“可移植性”这个问题太难了,那就让我们弱化一下需求,先解决一些更简单的问题:“弱移植性”。
可移植性分级
“可移植性”这个需求太模糊了,我们先明确下需求。我们可以把可移植性分成多个等级:
level 0:业务系统换云平台部署时,需要改业务代码(比如换一套基础设施 sdk,然后重构业务代码)。
这是常见状态:比如某公司内部有一套自研消息队列系统“XX MQ”,有一个“xx-mq-java-sdk”供业务系统引入。当业务系统想要上云 / 换云部署时,由于云上没有“XX MQ”,需要换一个 MQ(比如换成 RocketMQ),业务系统需要做重构。
level 1:换云平台部署时,业务代码不用改,但是需要换一套 sdk,重新编译。
社区有一些通过 sdk 做跨平台的方案,属于这个级别。比如携程开源的 Capa 项目,比如腾讯开源的 Femas 项目。
level 2:换云平台部署时,业务系统不需要改代码,不需要重新编译,但是 Sidecar 要改代码。
level 3:换云平台部署时,业务系统和 Sidecar 都不需要改代码,不需要重新编译,只需要改配置。
level 4:换依赖的开源产品时(比如原先使用 Redis,现在要换成别的分布式缓存),业务系统和 Sidecar 都不需要改代码。
社区的最终目标是 level 4,但是上文已述,现在还没法完美实现,存在种种问题。对于需要快速落地,解决业务问题的商业公司,现在能实现的目标是:追求 level 2 的可移植性,部分场景可以达到 level 3。这就足够解决业务问题了。
比如分布式缓存场景,蚂蚁在 MOSN 里自建了一套分布式缓存中间件支持 Redis 协议访问,如果你相信 Redis 协议是具有可移植性的,那么应用通过 Redis 协议和 MOSN 通信即可,没必要强行迁移到 Dapr 的“State API”上。在这种情况下,标准化 API 只是作为补充。
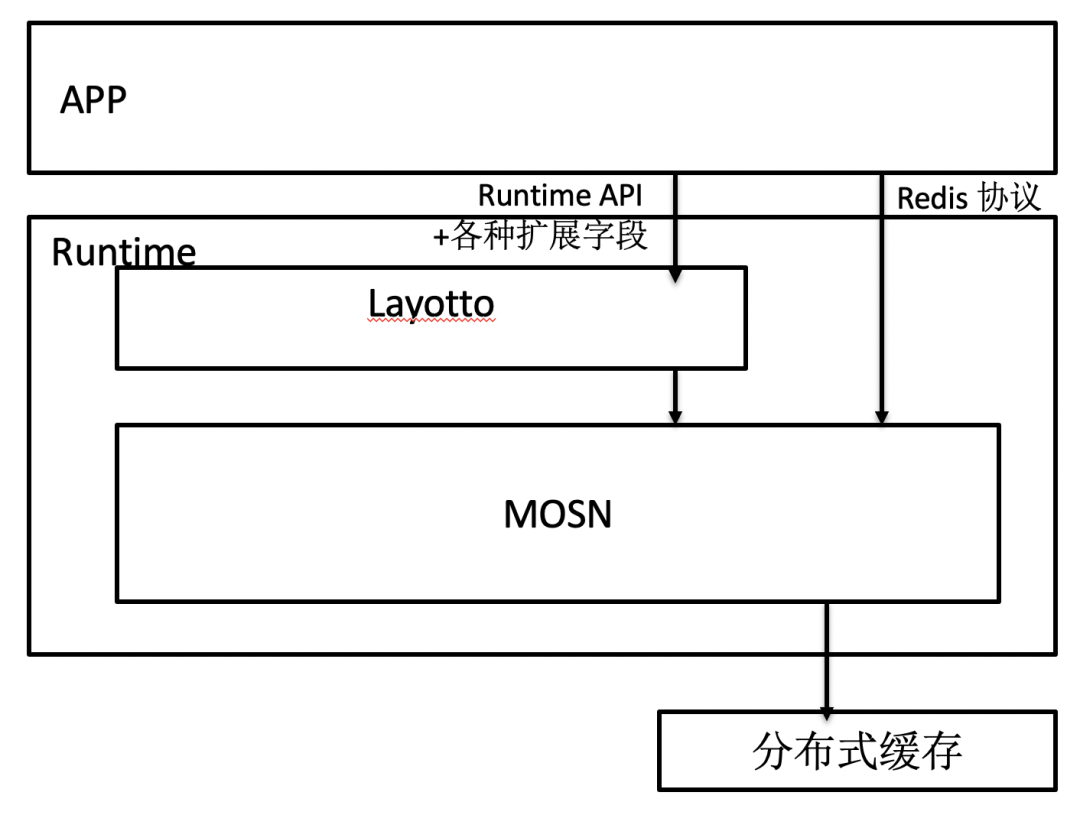
题外话:Sky Computing 的“兼容层”需要哪种可移植性?
按照这种分级方式,Sky Computing 提出的“兼容层”需要 level 3 及以上的可移植性。
如何实现 level 3 可移植
如果我们把目标定为 level 3,那么 Runtime 对外暴露的“兼容层”协议应该是多种多样的,包括各种领域的可信协议(比如 Redis 协议、MySQL 协议、AWS S3 协议等),以及 Dapr 风格的标准化 API。
由此,我们可以得出两个观点:
观点 3. 拥抱可信协议:Dapr 标准化 API 的定位应该是作为可信协议的补充,而不是试图让用户放弃可信协议,迁移到 Dapr API 上。
观点 4. 设计 Dapr 标准化 API 时,要专注于那些还没有形成可信协议的领域,为这些领域设计标准化 API,而不是花精力设计“Another SQL”,或者纠结“如何从 Redis 迁移到 Memcached”。
比如,不同云厂商的配置中心提高的 API 不一样,还没形成事实标准,那么设计一套跨平台的 Configuration API 就能填补这个空缺。
演进路线
现在我们回答最开始提出的问题:
现在的 Dapr API 有很多问题,比如自定义扩展字段太多,破坏可移植性,比如面向“交集”做设计,功能太弱难以演进,比如侵入性强等等,该怎么办?
答案是:逐渐演进,先考虑从 level 2 演进到 level 3。
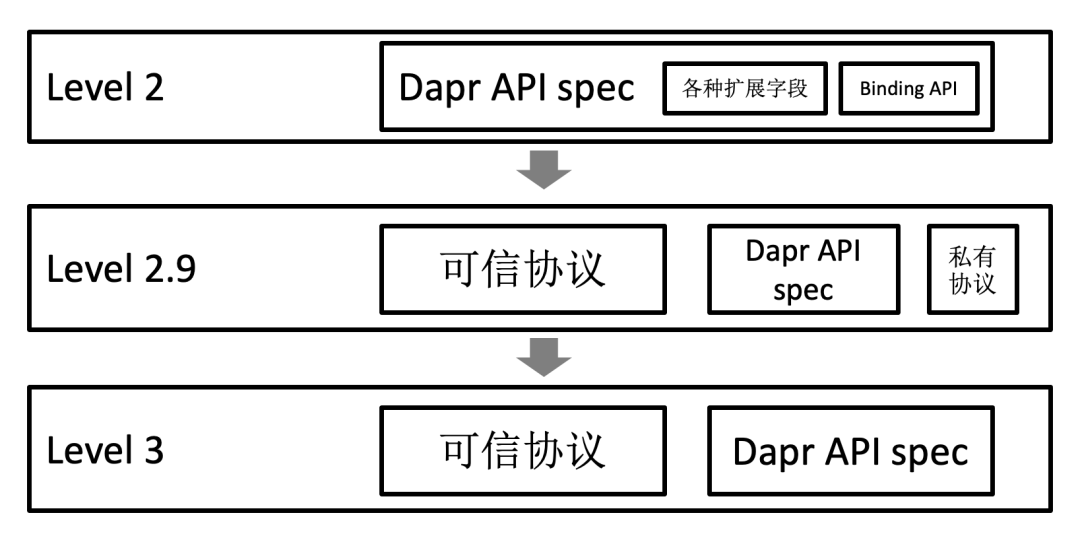
为了实现 level 3,我们需要:
放弃面向“功能交集”的设计,改为面向“功能并集”做设计
在 Sidecar 直接支持各种“可信协议”
而为了实现最终的 level 4,我们需要:
标准化 API 是完备的“功能并集”,保证覆盖到所有的业务场景:
有一套“feature 发现机制”,应用在部署时和基础设施协商“我需要哪些 feature”,基础设施根据应用的需求自动绑定组件
本文不再展开。
3. Runtime 架构带来的价值
除了标准化 API,实践中 Runtime 架构更大的价值在于以下几个方面:
3.1 可能是最重要的价值:让“下沉”合理化
一个有趣的观察是:以前 Mesh 的概念强调“代理”,因此一些基础设施产品想把自己的代码逻辑也“下沉”进 Sidecar 时可能会遭到 Mesh 团队的拒绝,或者能“下沉”进去,但是实现的比较 hack,并不规范;而有了 Runtime 的概念后,各种产品把代码逻辑挪到 Sidecar 行为就合理化了。
这里说的“下沉”,是指“把应用依赖的公共组件从应用里挪到 Sidecar 里”,分离核心业务逻辑和技术部分。好处就太多了,比如:
多语言复用中间件
Service Mesh 宣传的好处之一是让多语言应用复用流量治理类的中间件,现在 Runtime 强调把更多的中间件放进 Sidecar,意味着有更多的中间件能够被多语言应用复用。比如,以前的中间件都是为 Java 开发的,C++ 用不了,现在可以让 Node.js/Python/C++ 语言的应用通过 gRPC 调 Sidecar,复用中间件。
微服务启动加速、FaaS 冷启加速
原先微服务应用的框架比较重,比如有和配置中心建连、初始化、缓存预热之类的逻辑,现在这些启动逻辑都挪到 Runtime 里。当应用或者函数需要扩容时,可以复用原有 Runtime,不需要再做一遍类似的建连预热动作,从而达到启动加速的效果。
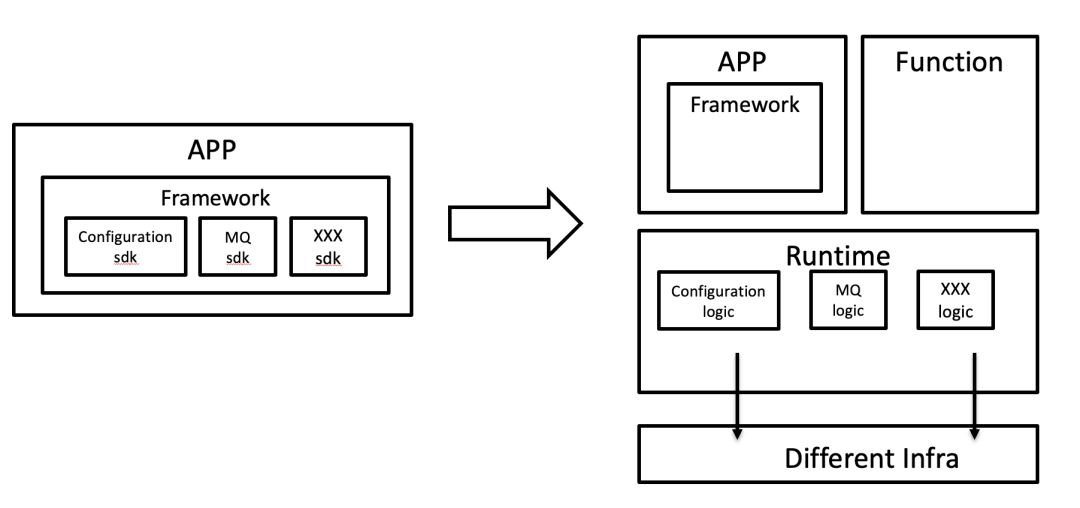
不用推动用户升级 sdk 了
这个就是 Mesh 一直讲的好处:有了 Sidecar 后,不需要天天催促各个业务方升级 sdk,提高了基础设施的迭代效率。
让业务逻辑也能下沉
除了基础设施,一些业务逻辑也有放进 Sidecar 的诉求,例如处理用户信息等逻辑。
让业务逻辑放进 Sidecar 需要保证隔离性,去年尝试了用 WebAssembly 来做,但是不太成熟,不敢在生产中使用,今年会尝试其他方案。
3.2 让“下沉”规范化:约束“私有协议”,保证能实现 level 2 可移植
在“下沉”的过程中,标准化 API 更多的是起到约束“私有协议”的作用,比如:
限制私有协议的通信模型
设计私有协议时(Layotto 支持“API 插件”功能,允许扩展私有的 gRPC API),需要证明“这个私有协议在其他云上部署时,存在一个能切换的组件”
作为设计私有协议的指导:参照着标准化 API 去设计私有协议,有理由相信设计出来的协议在换云部署时,能达到 level 2 可移植性
3.3 RPC 协议转换、微服务互通
Dapr 的 InvokeService(用来做 RPC 调用的 API)设计的比较简单,也有一些不足,在实际 RPC 场景中,Layotto 调整了它的定位,作为 Service Mesh 的辅助:
已有的 Java 微服务的 RPC 流量还是通过 Service Mesh(MOSN)进行转发,而对于其他语言的微服务,或者其他协议栈的微服务,可以通过 gRPC 调用 Sidecar,由 Sidecar 帮忙做协议转换,然后把流量接入已有服务体系。
比如很多语言没有 Hessian 库,可以通过 gRPC 调 Layotto,Layotto 帮忙做 Hessian 序列化,然后将流量接入 MOSN。
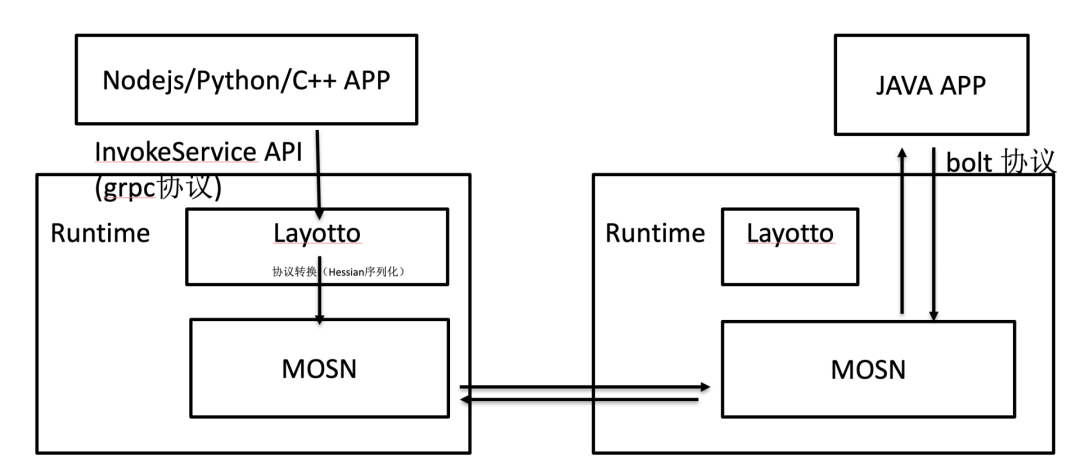
(业界也有一些做多语言微服务打通的项目,比如 dubbogo-pixiu 项目,区别是通过网关的形式部署)
4. 如何划分 Serivce Mesh,Event Mesh 和 Multi-Runtime 的边界?
Serivce Mesh 和 Event Mesh 的区别是什么?网上的说法是 Event Mesh 处理异步调用的流量,Service Mesh 处理同步调用。
Service Mesh 和 Dapr 的区别是什么?网上的说法是 Service Mesh 是代理,Dapr 是运行时,要抽象 API,做协议转换。
但是,随着落地演进,我们渐渐发现这些技术概念的边界变得很模糊。
如下图,Layotto 这个 Sidecar 支持了各种协议,好像已经“非驴非马”了:不只是 Dapr 式的对外暴露标准化 http/gRPC API,抽象分布式能力,也包括 Service Mesh 式的流量拦截、代理转发,能处理同步调用、异步调用,能处理 Redis 等开源协议的请求,好像把 Event Mesh 的事情也做了,已经变成了一种混合模式的 Sidecar:
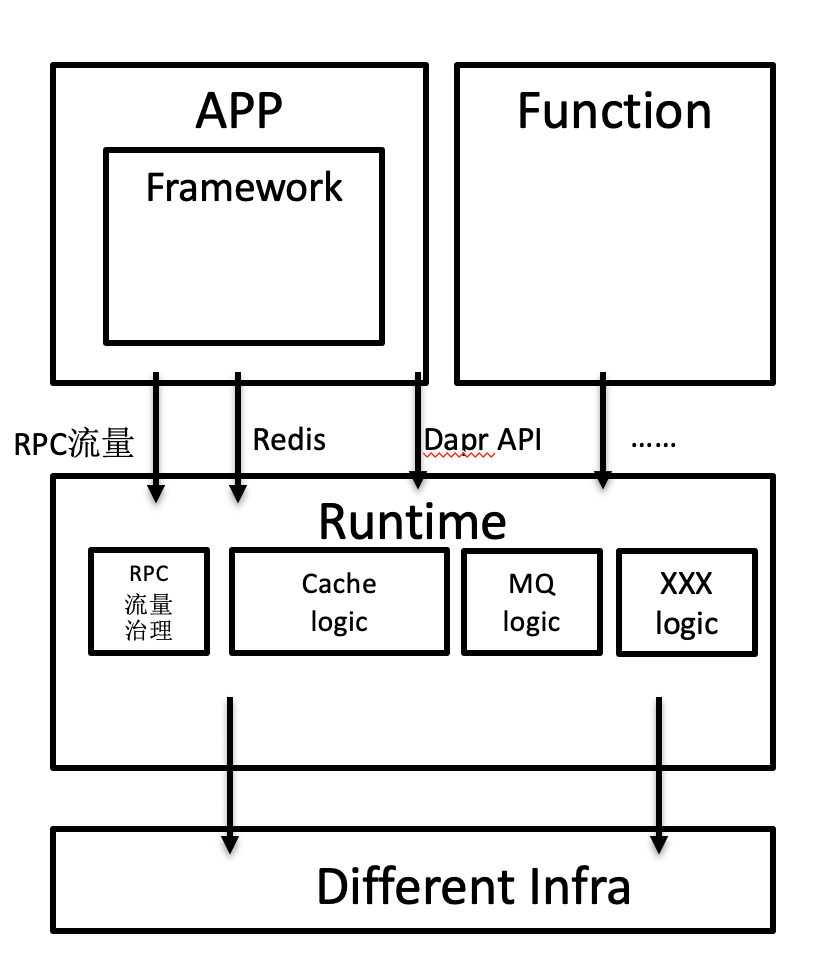
所以,如何划分 Serivce Mesh,Event Mesh 和 Multi-Runtime 的边界?
个人观点是,可以把 Dapr 的“标准化 API”看做“Sidecar 增强”。比如“InvokeService API”可以看成“Service Mesh 增强”,“Pubsub API”可以看成是“Event Mesh 增强”,“State API”可以看成“数据中间件增强”,这里说的数据中间件包括缓存流量转发和 DB Mesh。从这种角度看,Layotto 更像是 Sidecar 里的“API 网关”。
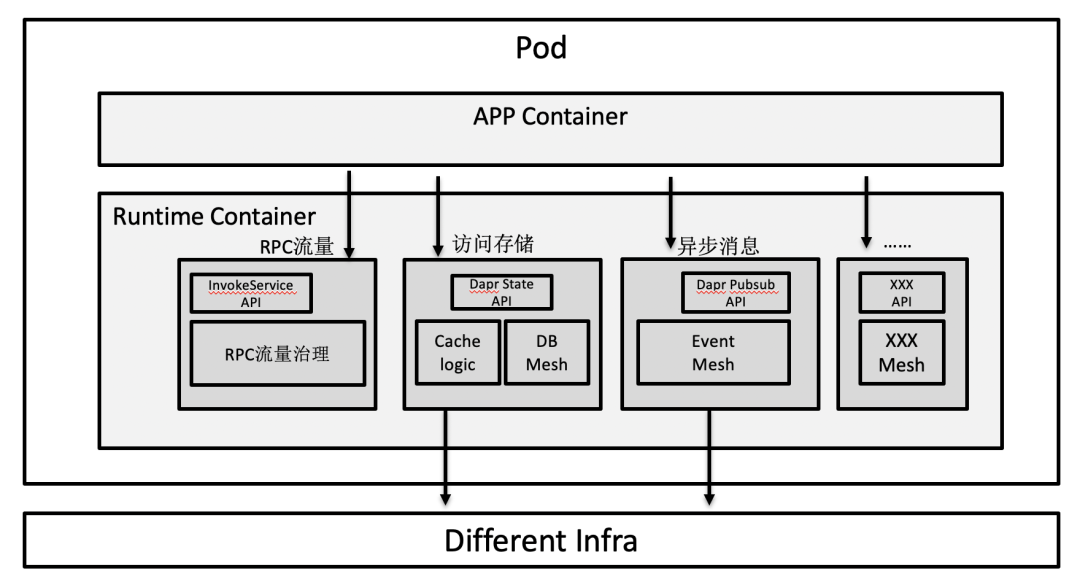
5. 部署形态之争
5.1 目前的架构有什么问题?
目前的架构存在一个问题:Runtime 是个巨石应用。
不管是 Dapr 还是 Layotto,都倾向于承载所有和业务无关的功能。
如果你把 Runtime 类比成操作系统的内核,那么 API 这层就是系统调用,负责抽象基础设施,简化编程,而不同的组件类似于驱动,负责把系统调用翻译成不同基础设施的协议。Runtime 把所有组件都放在一个进程里,类似于“宏内核”的操作系统把所有子模块都塞在一起,变成了巨石应用。
巨石应用有什么问题?模块间互相耦合,隔离性不好,稳定性降低。比如之前就有研究指出 Linux 中大部分的代码是驱动,而且很多驱动是“业余玩家”写的,稳定性不好,驱动写的有问题是 kernel 崩溃的主要原因。同样的,如果 Dapr 或者 Layotto 的一个组件出现 bug,会影响整个 Sidecar。
怎么解决巨石应用的问题呢?拆!一个思路是把 Runtime 按模块拆分,每个模块是一个 Container,整个 Runtime 以 DaemonSet 的形式部署:
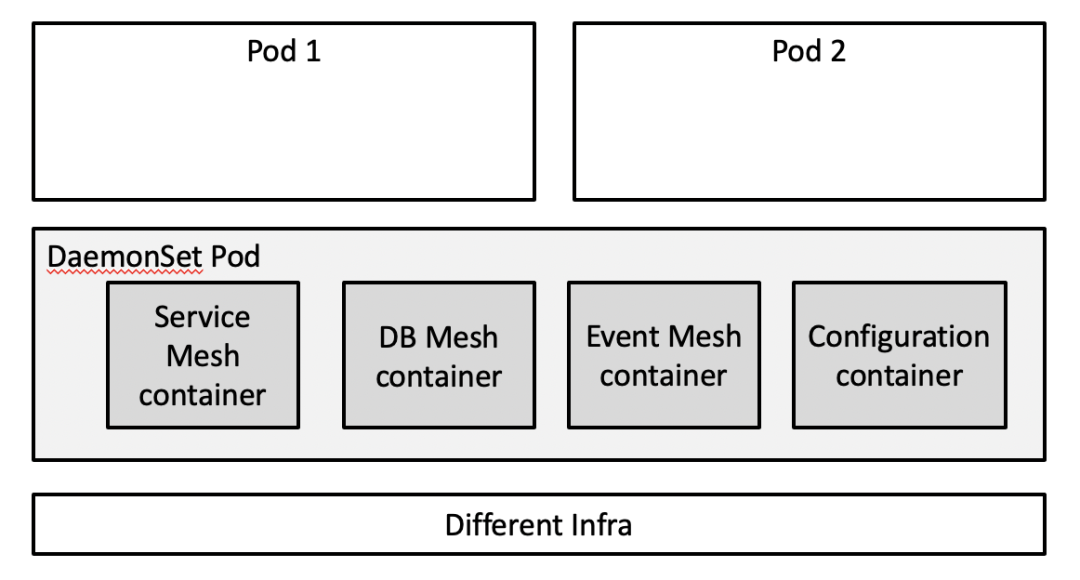
这种方案就像操作系统的“微内核”,不同子模块之间有一定的隔离性,但相互通信的性能损耗会高一些。比如 Event Mesh 容器想要读取配置中心的配置时,就需要通过网络调用 Configuration 容器;如果调用频率过高,就要考虑在 Event Mesh 容器里做一些配置缓存,可能最后每个容器都要做一套缓存。
那么应该选择单容器 Runtime 还是多容器 Runtime 呢?这就像操作系统选择“宏内核”还是“微内核”架构,全看取舍。巨石应用的好处是子模块之间互相通信性能好,缺点是紧耦合,隔离性不好;如果把 Runtime 拆成多个 Sidecar 则刚好相反。
目前,Dapr 和 Layotto 都是单容器 Runtime。
一个可能的拆分方案是:将 Runtime 按能力“垂直拆分”成多个容器,比如一个容器负责状态存储,一个容器负责异步通信等等,容器间通信通过 eBPF 做优化。不过目前还没看到这样做的项目。
5.2 目前的架构还可以做哪些优化?
优化点 1:启动应用时,需要先启动 Sidecar 容器,再启动应用容器。能否让应用启动加速?
直觉上想,如果能让新启动的应用(或函数)复用已有的 Runtime,就能省掉一些初始化动作,加速启动。
优化点 2:能否减少 Runtime 的资源占用?
每个 Pod 都有一个 Sidecar 容器,假如一个节点有 20 个 Pod,就得有 20 个 Sidecar,在大规模集群里光是 Sidecar 就要占用很多内存。
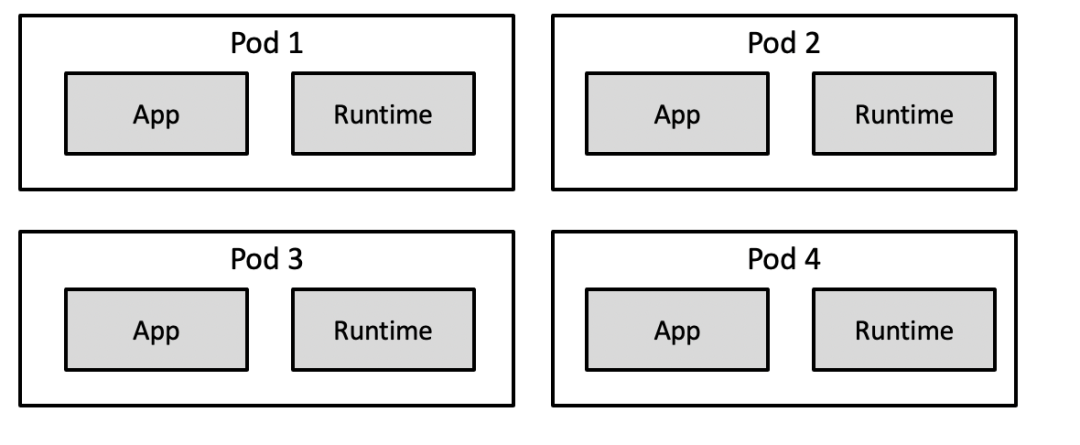
能否减少 Runtime 的资源占用?
直觉上想,如果能让多个容器共享同一个代理(而不是每个容器独享一个代理),就能减少资源占用。
上述两点看起来都可以通过“让多个容器共享同一个代理”来做优化。但事情真有那么简单吗?
Service Mesh 社区关于“共享代理”的讨论
其实 Service Mesh 社区有过很多关于数据面部署形态的争论,大致有以下几种方案:
Sidecar 模式,每个应用独享一个代理
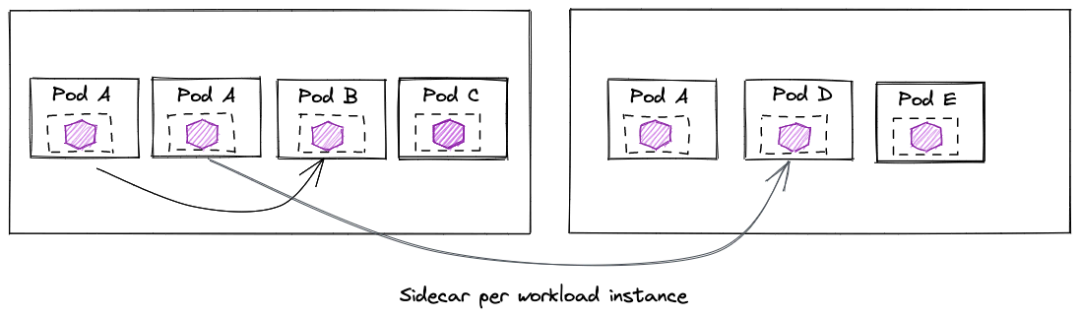
(图片来自<eBPF for Service Mesh? Yes, but Envoy Proxy is here to stay>)
节点上所有 Pod 共享同一个代理
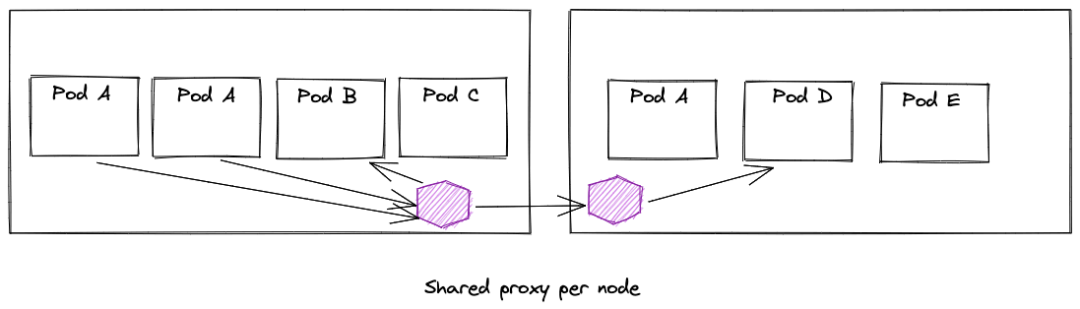
(图片来自<eBPF for Service Mesh? Yes, but Envoy Proxy is here to stay>)
不需要代理进程,用 eBPF 处理流量
很优雅,但功能有限,满足不了所有需求。
节点上每个 Service Account 共享一个代理
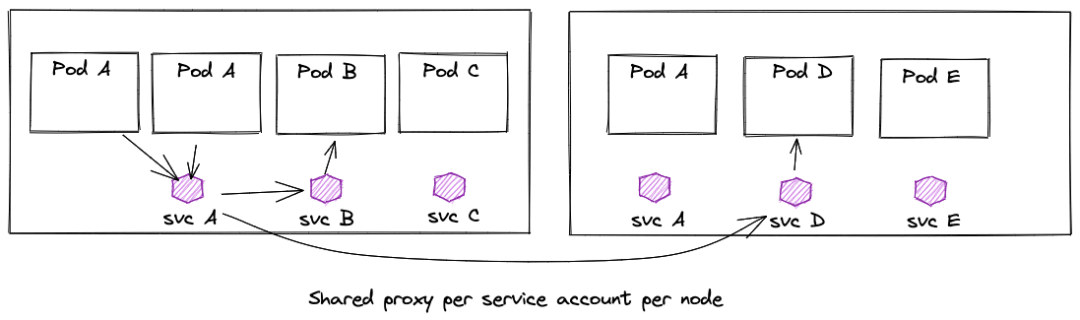
(图片来自<eBPF for Service Mesh? Yes, but Envoy Proxy is here to stay>)
混合模式:轻量 Sidecar+ 远端代理
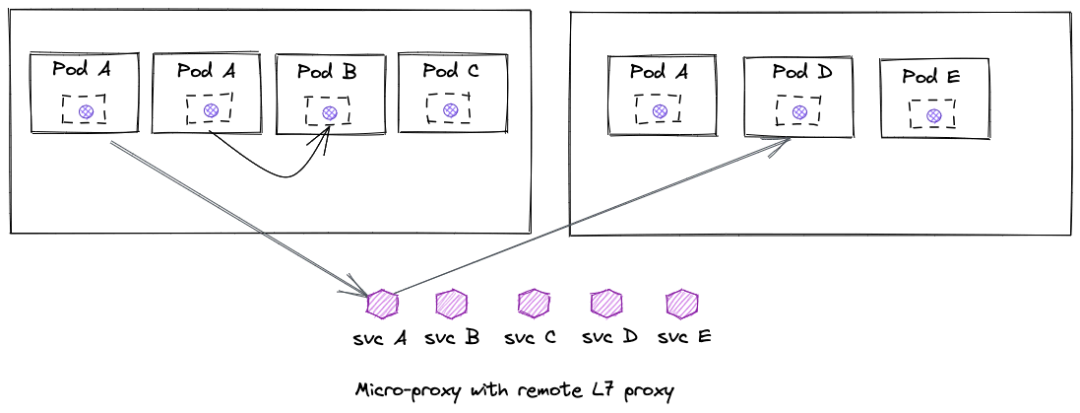
(图片来自<eBPF for Service Mesh? Yes, but Envoy Proxy is here to stay>)
Runtime 社区还需要共享代理吗?
上面几种方案看起来都行,只是取舍问题,但是到了 Runtime 这里,情况就变了!
情况 1:集群里有各种各样的中间件,各种各样的基础设施
如果集群里有各种各样的中间件,各种各样的基础设施,那还是别用“节点上所有 Pod 共享同一个代理”的模型了。
举个例子,某集群里有各种各样的 MQ,如果节点上所有 Pod 共享同一个 Runtime,Runtime 事先不知道 Pod 会用什么 MQ,所以它必须在编译时带上所有 MQ 组件。每次新建一个 Pod 时,这个 Pod 要动态把配置传给 Runtime,告诉 Runtime 它要用哪个 MQ,然后 Runtime 再根据配置去和相应的 MQ 建立连接。
比如下图,某个节点上,Pod 1、Pod 2、Pod 3 分别使用 RocketMQ、Kafka、ActiveMQ,这时新启动了一个 Pod 4,Pod 4 告诉 Runtime 它很有个性,它要用 Pulsar!于是 Runtime 就得去和 Pulsar 建连,做一些初始化动作。所以,Pod 4 启动并没有“加速”,因为它没能复用之前已有的连接。
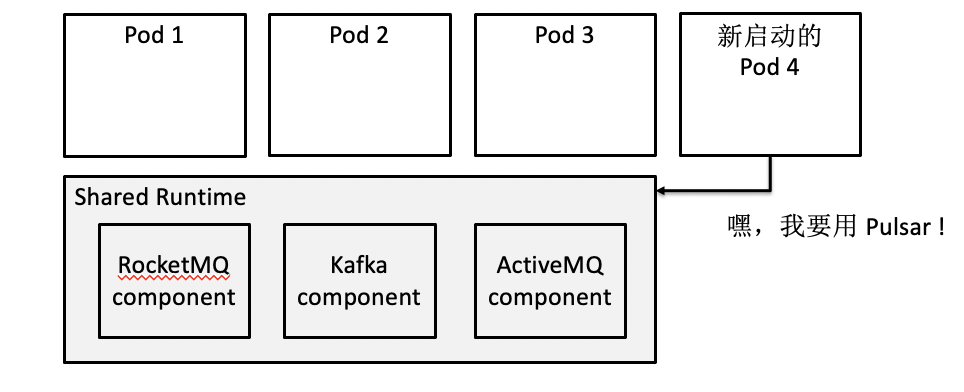
这种情况下,共享 Runtime 并不能帮助应用启动加速,无法复用和后端服务器的连接数,虽然能省一些内存,但带来了一些缺点:增加了复杂度,降低了隔离性等等。
如果强行把 Sidecar 模型的 Runtime 改成共享代理,有用,但投入产出比不高。
情况 2:集群里基础设施的技术栈比较统一
在这种情况下,共享代理模型可能有一定价值。
比如,某集群只用一种 MQ,RocketMQ。假如使用共享代理模型,某个节点上 Pod 1、Pod 2、Pod 3 已启动,这时新启动一个 Pod 4 也要用 RocketMQ,此时就可以复用已有的一些元数据,甚至有可能复用和 MQ 服务器的连接。
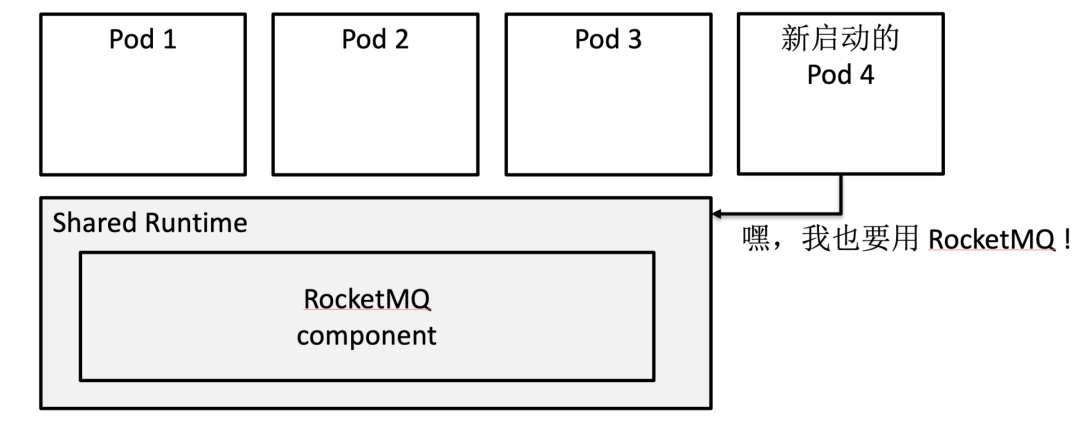
这种情况下,共享代理模型的好处有:
应用启动加速,复用和后端服务器的连接
不过,所谓“启动加速”也是要看情况的,比如通过优化让 Runtime 启动快了 2 秒,但是应用启动却要 2 分钟,那么优化 2 秒其实并没有多大用处。尤其是有很多 Java 应用的集群,大部分 Java 应用启动不快,这点优化价值有限。所以,启动加速在 FaaS 场景会比较有用。如果函数本身启动、加载速度较快,优化几秒还是很有价值的。
提高资源利用率,不用部署那么多 Sidecar 了
6. 总结
本文讨论了 Layotto 落地之后,关于 Multi-Runtime 架构“可移植性”、落地价值以及部署形态等方面的思考。且本文的讨论不限定于某个具体项目。
作者简介:
周群力,目前在蚂蚁中间件团队负责 Layotto 项目的开发,以及 Layotto 和 SOFAStack 开源社区的建设。Dapr 贡献者,Dapr sig-api 的 Co-chair。个人 GitHub:https://github.com/seeflood
参考链接:
Multi-Runtime Microservices Architecture:https://www.infoq.com/articles/multi-runtime-microservice-architecture/
Mecha:将 Mesh 进行到底:https://mp.weixin.qq.com/s/sLnfZoVimiieCbhtYMMi1A
从 Service Mesh 到云原生:https://mp.weixin.qq.com/s/KSln4MPWQHICIDeHiY-nWg
Dapr 项目地址:https://github.com/dapr/dapr
Layotto 项目地址:https://github.com/mosn/layotto
Capa 项目地址:https://github.com/capa-cloud/cloud-runtimes-jvm
Femas 项目地址:https://github.com/polarismesh/femas
活动推荐:
更多云原生话题,欢迎关注 QCon 全球软件开发大会(北京站),会议设置了云原生微服务架构新趋势、云原生时代的可观测最佳实践、云原生架构变革等专题。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论