

本文为 Robin.ly 授权转载,文章版权归原作者所有,转载请联系原作者。
本期Robin.ly AI 访谈特邀 Recurrent.ai 的联合创始人、CMU 博士杨植麟博士,介绍了他们团队共同发明的 XLNet 算法,以及他和他的团队如何用人工智能技术赋能企业销售,提高与客户的沟通能力。
XLNet 算法在 20 个自然语言处理数据集上超越了之前最好的算法 BERT。杨植麟博士的研究曾在超过 30 个数据集上取得了历史最优结果,包括自然语言推理、问答和半监督学习。他曾实习于谷歌大脑研究院和 Facebook 人工智能研究院。此前他获得了卡耐基·梅隆大学博士学位和清华大学学士学位。
下文为 Robin.ly 主持人 Alex 与杨植麟博士的访谈实录。
大牛导师的影响
Alex: 杨博士在整个博士期间正好经历了 AI 和自然语言处理、深度学习大发展的几年。你自己怎么看这几年发展的一些主要节点?
杨植麟:
NLP 的发展分成几个主要的阶段。第一个是 word-embedding(词嵌入)的提出,大概是在 2003 年,Bengio 的团队发表了第一篇论文。在 2013 年, Mikolov 把这项工作推广成 Word2vec 之后,这个领域逐渐流行起来。最后是注意力和记忆机制,大概是在 2014 年到 2015 年。那个时候我刚好入学,随后就有两拨新的小高潮出现。第一波是在大概 2017 年的时候出现了 Transformer,2017 年左右预训练的思想开始流行。所以这几年的发展非常迅速,我感觉我也是运气特别好,能够在这一波潮流里面做一些工作。
Alex: 你的导师是 Ruslan Salakhutdinov,也是苹果公司人工智能部门的负责人。你在做 XLNet 期间跟 Facebook AI,Google brain 的 Quoc Le,Jason Weston 这样的专家也合作过。你从他们身上都学到了什么?
杨植麟:
我十分感激我的导师 Ruslan 能够给我们提供一些开放的环境,他非常愿意接纳不同的想法,使得我有很多资源和环境去做我想做的事情。Jason 是一个非常问题驱动的人,比如说他现在想解决对话这个问题,那他所有工作都会围绕这个来做。而 Quoc 更注重通用的方法,他更希望用一个通用的方法去解决所有问题,包括他之前做的 AutoML,还有我们最近做的 XLNet 都有这种思想,就是用一种通用的框架去解决所有的问题。其实我觉得我更多受到的是 Quoc 的影响,一个是想办法让一个方法通用化,二是把它用更大的算力去规模化。

杨植麟博士与导师,来源:杨植麟
超越 BERT 的解决方案 - XLNet
Alex: 当时你为什么会选择做 XLNet 这个课题?我记得你在此之前写过两篇论文,关于 Transformer-XL 和 Mixture of Softmaxes。这两个工作跟 XLNet 项目有什么关系?
杨植麟:
我觉得这里面包含两个方面:一个是语言建模(language modeling),另一个是 pre-training(预训练)。我们之前做的工作主要和语言建模相关,而 XLNet 相当于是做一个预训练。当时我们把 Transformer-XL 的结果投到了 ICLR,效果特别好,在所有语言建模的基准测试上都是得到了最优结果。但是当时这个文章被拒了,因为审稿人认为如果不能直接提升下游任务的性能就没必要做语言建模。
所以我当时就在思考这个问题,而 XLNet 就相当于这个问题的一个解决方案。我们把语言建模和预训练中间架了一个桥梁。之前这两个东西之间是真空的,因为语言建模只有单向的信息,所以用它做预训练的时候效果不一定好。这就是为什么 Google 要提出 BERT 来解决这个问题的原因。但是它其实并没有解决为什么语言建模可以直接用的问题,因为它不是基于自回归的思想,而是基于一种自编码的思想。但是 XLNet 就回答了为什么语言建模可以用来做预训练的问题,相当于把两个框架统一到一起。所以我们这项工作是受到前人工作的启发,也是一个拓展,做了一些框架的融合。
现在除了 Google brain,谷歌的很多其他部门也都对这个模型很感兴趣,而且很多人已经开始探索它的应用,比如直接替代已有的 BERT 而不需要其他额外的成本。
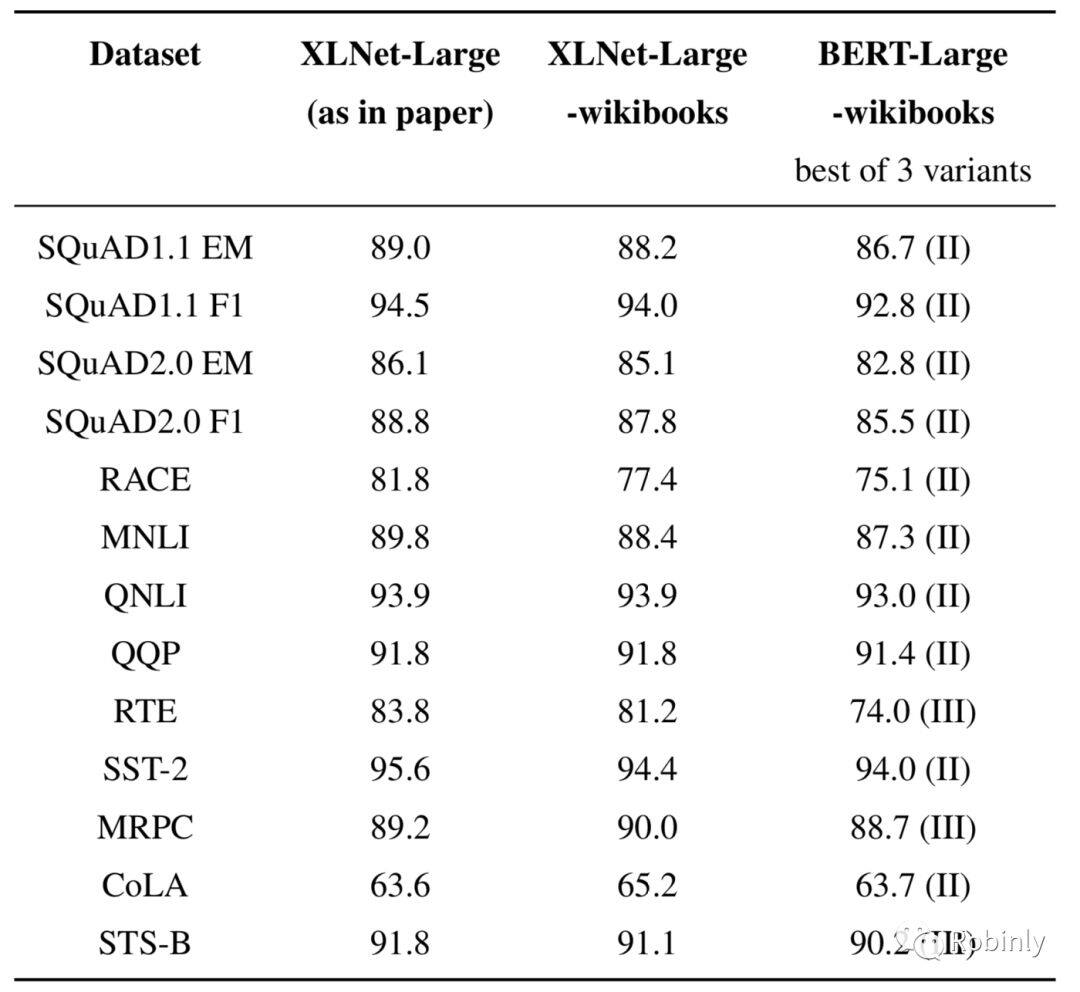
XLNet 与 BERT 比较数据
Alex: 在这个项目里你们跟合作方是如何分工的?我知道你作为论文的第一作者,是比较重要的贡献者,其他人提供了一些什么东西资源给你?
杨植麟:
我跟 Zi Hang 是共同一作,包括整个实验,主要的想法和代码,还有论文都是我们两个人做的。其他人帮我们完善了想法,提供了计算资源上的帮助以及一些方向上的指导。
用人工智能赋能企业销售
Alex: 在你读博士期间还共同创建了一家初创公司,叫 Recurrent.ai。公司现在有多少人?目前进行了几轮融资?创立这家公司是要解决什么问题呢?
杨植麟:
我们大概有 40 多人。现在融资进行到了 A 轮。
我们现在做的是 AI for sales(针对销售的人工智能),就是用人工智能技术去赋能企业的销售,和客户之间的沟通。具体就是把公司的电话销售先转成文字,或者直接把销售文字利用起来,在上面做一些分析,提升它的销售转化率。其中主要的场景可能有三个,首先第一个场景是做销售线索的推荐。我们可以帮他匹配最好的线索。第二个是做客户画像的分析和挖掘。我们可以更好的将客户和他们的解决方案匹配起来。了解用户的画像之后就可以给他提供分析和建议,推荐相应的产品或者服务。第三个是做全量、全渠道的销售质检。我们现在大的客户可能有几千个坐席,我们每天都会有全量的电话销售质检监测执行。
Alex: 听起来是一个 To B 的企业服务的公司。线索推荐实际上就是销售线索获取(lead generation),你是从公开信息去挖取吗?还是利用已有的市场活动?
杨植麟:
我们是基于电话还有他们的历史沟通信息的基础上进行类似的推荐,就是说他的 leads (销售线索)已经存在于电话或者文字当中。
这个过程目前可以做到全自动化。我们可以直接根据他们的录音和文字内容去推荐,不需要任何人工的干预,这就跟以前传统的做法不一样。传统的方法是,比如现下有一些人专门用 Excel 表格去整理那些东西,但那个方法就很难规模化,而且还不是特别准确。我们现在可以让这一流程实现全自动化。关于实时性,我们会每天更新一次,因为每天客户的特征线索都会发生变化,在这个尺度上我们现在能观察到比较好的效果。我们现在在互联网、教育和金融这三个领域都有最标杆的客户。

Recurrent.ai 团队,来源:杨植麟
Alex: 是不是互联网、教育、金融领域的这些客户场景通常都有大量的数据,适合电话销售?
杨植麟:
对,他们拥有大量的沟通数据,我们能够把这种数据转换成一个真正能产生价值的策略。因为我觉得这是一个标注数据和非标注数据的区别,主要是他们原始存在的一些数据是非标注的。我们现在在垂直领域有几万个小时的电话录音标注,在上面我们还做了文本语义的标注。正是通过这些大量的标注数据使我们能实现价值的转换,而且这个标注数据可以在不同的行业之间,或者同一行业不同公司之间进行转换,是比较容易规模化的。
Alex: 你们是要解决销售的效率问题对吧?提高效率、降本增效。这里的技术难点在什么地方?
杨植麟:
我觉得最难的点就是你要找到一个场景,使得我们这些前沿技术能用上。这个场景要符合几个条件:第一个条件是它要对客户产生很大的价值。第二个条件是你的技术在这个场景里面必须是一个很关键的部分。不然你用前沿技术提升了 10 个点,但是客户没有感知,这个东西就没有用。第三点是它应该是一个监督学习的问题。我们遇到了很多客户需求,这些是非监督学习的问题,那这个时候我们就想办法把它从一个非监督的问题转换成一个监督学习的问题。所以我觉得我们现在这几个场景都比较符合这个条件。我们这些 Transformer-XL 的研究成果都已经用到了线上的生产流程里,确实在性能上实现了很大的提升。而且因为符合前面这个条件,所以客户有感知,他们就愿意为这个事情买单。
Alex: 前面两个我比较理解,第一个是刚需,第二个要产生重要影响,你做的事情要带来实质性的提高。第三点我不太理解,你为什么强调要从非监督学习到监督学习?
杨植麟:
其中包括两个方面:第一个方面就是我觉得深度学习,包括 NLP 一整套技术要取得效果,必须在监督学习的场景下做。因为你如果只是做一个聚类的话,跟用传统方法,用一个嵌入聚类效果差不多。第二点,相比过去,现在的监督学习需要更少的标签。因为我们有无监督的预训练,XLNet 就是一个预训练的例子,所以我们现在可以减少监督学习的标注成本。这两个东西并不矛盾,这个问题最终还是要被定义成一个监督学习,或者是一个分类结构预测(structure prediction)的问题。我们最终是希望能够用非监督学习来提升这个过程,一个是问题的定义,一个是方法本身,这两个不一样。

Robin.ly 主持人 Alex(图左)与杨植麟(图右)
创业原因与收获
Alex: 能介绍一下公司的其他几位合伙人吗?当初选择这个方向进行创业的原因是什么?目前为止最大的收获是什么?
杨植麟:
我们现在有 4 个合伙人,我跟 Edward(陈麒聪)还有张宇韬在清华读本科的时候是一个实验室的。宇韬是在清华读博。后来还有另外一个合伙人是 Jeff。我觉得我们可能每个人的背景侧重不一样,比如宇韬之前是清华出品的一个大数据分析平台 Aminer 的可能是最核心的一个开发者,他们有几百万独立 IP 的访问,有几亿的数据。除了他的学术研究能力之外,他的工程能力特别强。Edward 是一个连续创业者,他之前在美国有一些创业经历,所以他在做产品等各个方面对我们很有帮助。Jeff 也是一个连续创业者,他之前在另外一个公司曾经创造过从零到九位数的营业额的佳绩,带领团队实现了这个目标。我们各个方面的技能相对来说比较完整。
我们创立这个公司是想用 AI 去提升人类在社会活动中的沟通效率。沟通有很多种,我们现在专注于企业服务里面的销售和客户之间的沟通,因为在这一块我觉得降本增效可能带来价值,而且其中的场景更符合我刚才说的三个条件,我们的技术能够发挥更大的价值。
我觉得最大的收获就是,以前觉得只要技术做得特别好就能做一家成功的初创公司,就能改变世界。但是后来发现不是这样的,比如说你的场景要符合三个条件。另外很重要的一个经验就是我现在觉得 AI 初创公司有三个必要的生产要素,一个是我刚才说的场景,一个是人,还有一个就是数据,我们现在在这三个方面都在努力。这两点收获共同说明了一个事情,也是我的一个很重要认知,就是我从之前对技术的绝对追求,转变成了对整个生态系统、整个公司从上到下各种东西,包括生产要素的追求。我的认知有了这种视角的变化。
来源:Recurrent.ai
Alex: 你所谓的场景我的理解就是客户面临的问题。在解决问题的同时最好能利用上你们的特长,你们最擅长的技术或者现在做得最好的一些技术,这样你们在竞争里就处于领先的地位。
杨植麟:
对,客户面临的问题,你怎么去定义这个产品。如果从技术角度来说,就是你怎么把这个产品转化成一个问题的定义,再用你的工具去解决。你要打造一个壁垒,对我们来说可能用技术做壁垒是一个不错的选择。
Alex:你之前的研究工作也做得非常棒。希望你的公司能够蓬勃发展。今天感谢杨博士给我们的分享。谢谢!
原文链接:
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


硅谷AI科技、创业、领导力访谈

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论