

HDSF 作为分布式文件系统,常常涉及 DataNode、NameNode、Client 之间的配合、相互调用才能完成完整的流程。为了降低节点之间的耦合性,HDFS 将节点间的调用抽象成不同的接口,其接口主要分为两类:HadoopRPC 接口和基于 TCP 或 HTTP 的流式接口。流式接口主要用于数据传输,HadoopRPC 接口主要用于方法调用。HadoopRPC 框架设计巧妙,本文将结合 hadoop2.7 源码,对 HadoopRPC 做初步剖析。
0.目录
RPC 工作原理
HadoopRPC 架构设计
RPC Client 解读
RPC Server 解读
关于并发时的优化
参数配置
CallQueue 与 FairCallQueue
优先级
优先级确定
优先级权重
从一个命令解析
小结
RPC 工作原理
RPC(Remote Procedure Call)即远程过程调用,是一种通过网络从远程计算机程序上请求服务的协议。RPC 允许本地程序像调用本地方法一样调用远程计算机上的应用程序,其使用常见的网络传输协议(如 TCP 或 UDP)传递 RPC 请求以及相应信息,使得分布式程序的开发更加容易。
RPC 采用客户端/服务器模式,请求程序就是客户端,服务提供程序就是服务器。RPC 框架工作原理如图 1 所示,工作流程依次见图中标号①~⑩,其结构主要包含以下部分:
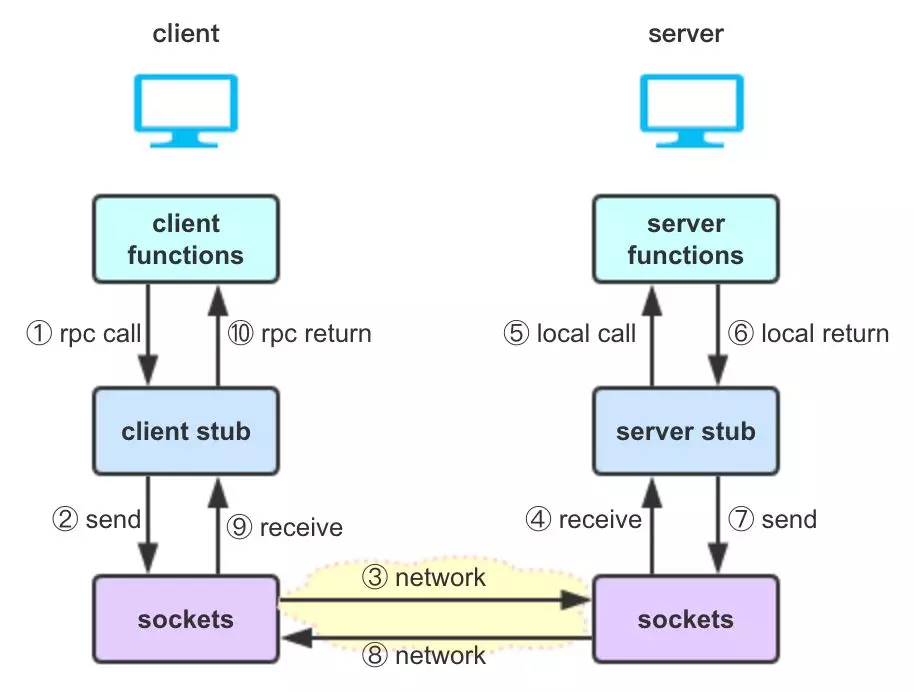
图 1 RPC 框架工作原理示例图
client functions
请求程序,会像调用本地方法一样调用客户端 stub 程序(如图中①),然后接受 stub 程序的响应信息(如图中⑩)
client stub
客户端 stub 程序,表现得就像本地程序一样,但底层却会调用请求和参数序列化并通过通信模块发送给服务器(如图中②);客户端 stub 程序也会等待服务器的响应信息(如图中⑨),将响应信息反序列化并返回给请求程序(如图中⑩)
sockets
网络通信模块,用于传输 RPC 请求和响应(如图中的③⑧),可以基于 TCP 或 UDP 协议
server stub
服务端 stub 程序,会接收客户端发送的请求和参数(如图中④)并反序列化,根据调用信息触发对应的服务程序(如图中⑤),然后将服务程序的响应信息(如图⑥),并序列化并发回给客户端(如图中⑦)
server functions
服务程序,会接收服务端 stub 程序的调用请求(如图中⑤),执行对应的逻辑并返回执行结果(如图中⑥)
那么要实现 RPC 框架,基本上要解决三大问题:
函数/方法识别
sever functions 如何识别 client functions 请求及参数,并执行函数调用。java 中可利用反射可达到预期目标。
序列化及反序列化
如何将请求及参数序列化成网络传输的字节类型,反之还原请求及参数。已有主流的序列化框架如 protobuf、avro 等。
网络通信
java 提供网络编程支持如 NIO。
主流的 RPC 框架,除 HadoopRPC 外,还有 gRPC、Thrift、Hessian 等,以及 Dubbo 和 SpringCloud 中的 RPC 模块,在此不再赘述。下文将解读 HDFS 中 HadoopRPC 的实现。
2.HadoopRPC 架构设计
HadoopRPC 实现了图 1 中所示的结构,其实现主要在 org.apache.hadoop.ipc 包下,主要由三个类组成:RPC 类、Client 类和 Server 类。HadoopRPC 实现了基于 TCP/IP/Sockets 的网络通信功能。客户端可以通过 Client 类将序列化的请求发送到远程服务器,服务器会通过 Server 类接收客户端的请求。
客户端 Client 在收到请求后,会将请求序列化,然后调用 Client.call() 方法发送请求到到远程服务器。为使 RPC 机制更加健壮,HadoopRPC 允许配置不同的序列化框架如 protobuf。Client 将序列化的请求 rpcRequest 封装成 Writable 类型用于网络传输。具体解析见下节—— RPC Client 解读。
服务端 Server 采用 java NIO 提供的基于 Reactor 设计模式。Sever 接收到一个 RPC Writable 类型请求后,会调用 Server.call() 方法响应这个请求,并返回 Writable 类型作为响应结果。具体解析见下节—— RPC Server 解读。
RPC 类提供一个统一的接口,在客户端可以获取 RPC 协议代理对象,在服务端可以调用 build() 构造 Server 类,并调用 start() 启动 Server 对象监听并响应 RPC 请求。同时,RPC 类提供 setProtocolEngine() 为客户端或服务端适配当前使用的序列化引擎。RPC 的主要两大接口如下:
那么,如何使用 HadoopRPC 呢?只需按如下 4 个步骤:
1. 定义 RPC 协议
RPC 协议是客户端和服务器端之间的通信接口,它定义了服务器端对外提供的服务接口。如 ClientProtocol 定义了 HDFS 客户端与 NameNode 的通信接口, ClientDatanodeProtocol 定义了 HDFS 客户端与 DataNode 的通信接口等。
2. 实现 RPC 协议
对接口的实现,将会调用 Server 端的接口的实现。
3. 构造并启动 RPC Server
构造 Server 并监听请求。可使用静态类 Builder 构造一个 RPC Server,并调用函数 start()启动该 Server,如:
4. 构造 RPC Client 并发送请求
构造客户端代理对象,当有请求时客户端将通过动态代理,调用代理方法进行后续实现,如:
RPC Client 解读
在 IPC(Inter-Process Communication)发生之前,客户端需要通过 RPC 提供的 getProxy 或 waitForProxy 获得代理对象,以 getProxy 的具体实现为例。RPC.getProxy 直接调用了 RPC.getProtocolProxy 方法,getProtocolProxy 方法如下:
RPC 类提供了 getProtocolEngine 类方法用于适配 RPC 框架当前使用的序列化引擎,hadoop 本身实现了 Protobuf 和 Writable 序列化的 RpcEngine 。以 WritableRPCEngine 为例,getProxy(…) 实现如下:
上述使用动态代理模式,Proxy 实例化时 newProxyInstance 传进去的 InvocationHandler 的实现类是 WritableRpcEngine 的内部类 Invoker。 当 proxy 调用方法时,会代理到 WritableRpcEngine.Invoker 中的 invoke 方法,其代码如下:
在 invoke 方法中,调用了 Client 类的 call 方法,并得到 RPC 请求的返回结果。其中 new WritableRpcEngine.Invocation(method, args) 实现了 Writable 接口,这里的作用是将 method 和 args 进行序列化成 Writable 传输类型。Client 类中的 call 方法如下:
以上代码展现了 call() 方法作为代理方法的整个流程。从整体来讲,客户端发送请求和接收请求在两个独立的线程中完成,发送线程调用 Client.call() 线程,而接收响应则是 call() 启动的 Connection 线程( getConnection 方法中,由于篇幅原因不再展示)。
那么二者如何同步 Server 的响应信息呢?内部类 Call 对象在此起到巧妙地同步作用。当线程 1 调用 Client.call() 方法发送 RPC 请求到 Server,会在请求对应的 Call 对象上调用 Call.wait() 方法等待 Server 响应信息;当线程 2 接收到 Server 响应信息后,将响应信息保存在 Call.rpcResponse 字段中,然后调用 Call.notify() 唤醒线程 1。线程 1 被唤醒从 Call 中取出响应信息并返回。整个流程如图 2 所示,分析如下。
在 call 方法中先将远程调用信息封装成一个 Client.Call 对象(保存了完成标志、返回信息、异常信息等),然后得到 connection 对象用于管理 Client 与 Server 的 Socket 连接。
getConnection 方法中通过 setupIOstreams 建立与 Server 的 socket 连接,启动 Connection 线程,监听 socket 读取 server 响应。
call() 方法发送 RCP 请求。
call() 方法调用 Call.wait() 在 Call 对象上等待 Server 响应信息。
Connection 线程收到响应信息设置 Call 对象返回信息字段,并调用 Call.notify() 唤醒 call() 方法线程读取 Call 对象返回值。
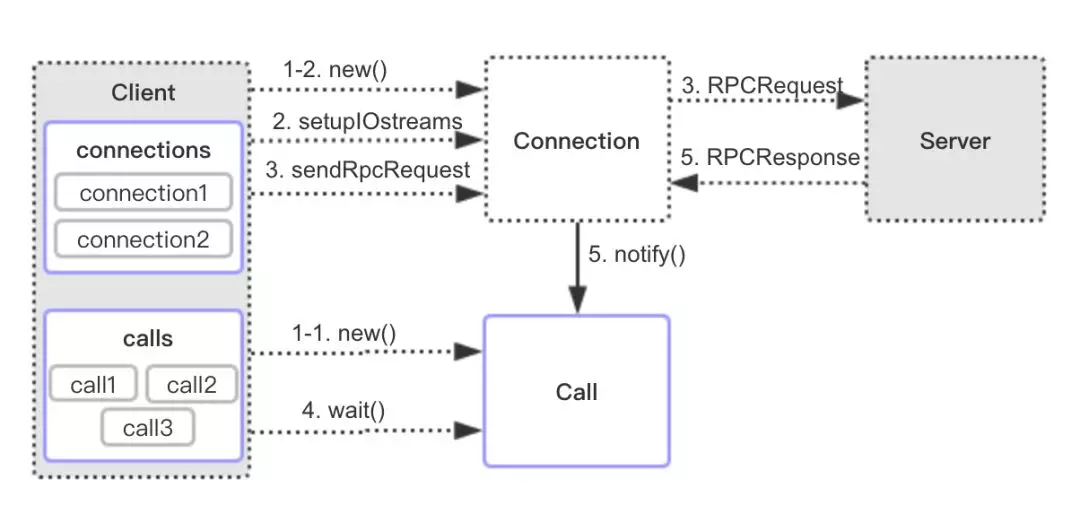
图 2 RPC Client 工作流程
RPC Server 解读
Server 部分主要负责读取请求并将其反序列化,然后处理请求并将响应序列化,最后返回响应。为了提高性能,Server 采用 NIO Reactor 设计模式。服务器只有在指定 IO 事件发生时才会执行对应业务逻辑,避免 IO 上无谓的阻塞。首先看一下 Server 类的内部结构,如图 3 所示,其中有 4 个内部类主要线程类:Listener、Reader、Hander、Resonder。
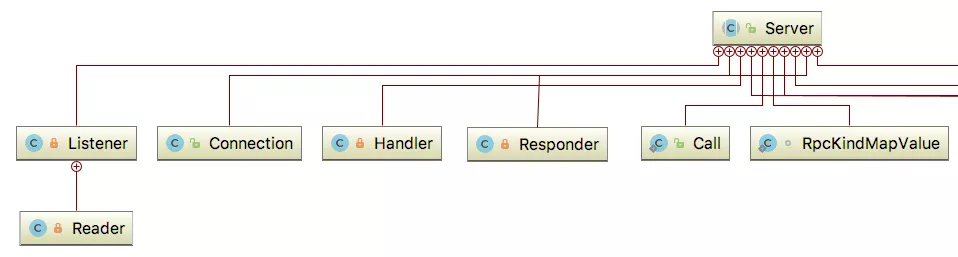
图 3 Server 类内部结构关系
Server 将各个部分的处理如请求读取、处理逻辑等开辟各自的线程。整个 Server 处理流程如图 4 所示。
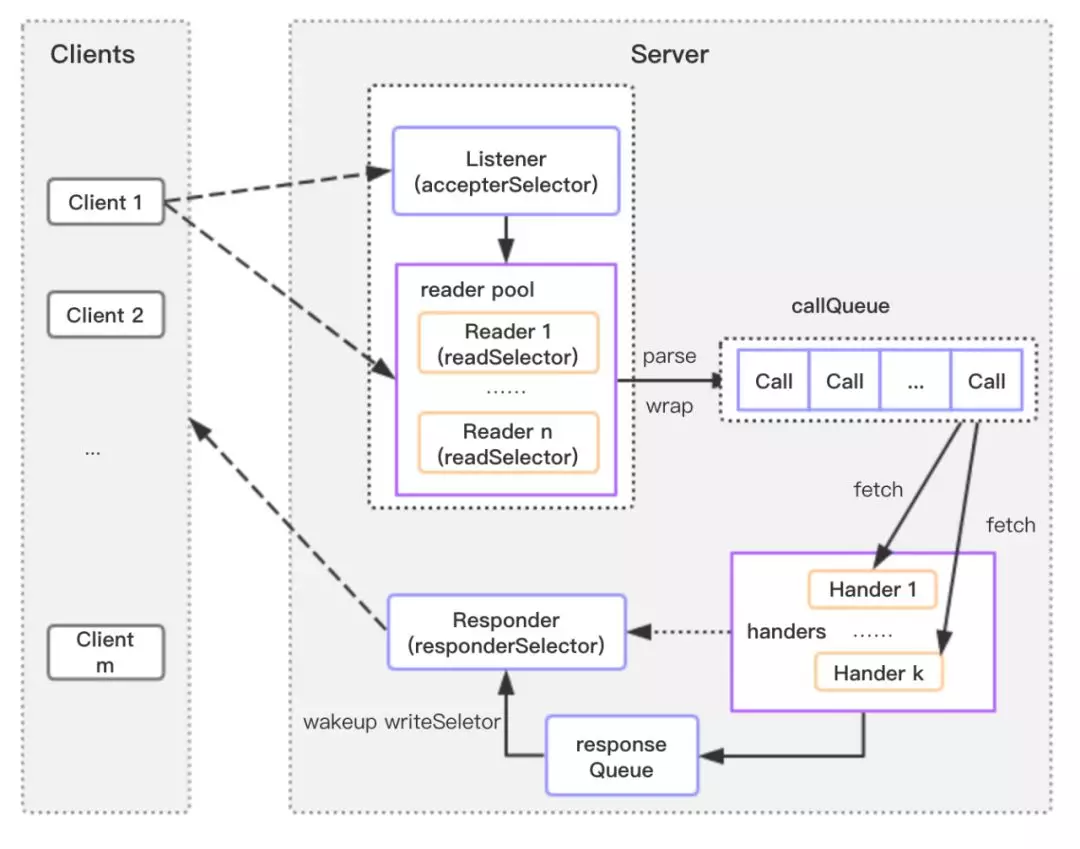
图 4 RPC Server 处理流程
Server 处理流程解读如下:
1.整个 Server 只有一个 Listener 线程,Listener 对象中的 Selector 对象 acceptorSelector 负责监听来自客户端的 Socket 连接请求。acceptorSelector 在 ServerSocketChannel 上注册 OP_ACCEPT 事件,等待客户端 Client.call() 中的 getConnection 触发该事件唤醒 Listener 线程,创建新的 SocketChannel 并创建 readers 线程池;Listener 会在 reader 线程池中选取一个线程,并在 Reader 的 readerSelector 上注册 OP_READ 事件。
2.readerSelector 监听 OP_READ 事件,当客户端发送 RPC 请求,触发 readerSelector 唤醒 Reader 线程;Reader 线程从 SocketChannel 中读取数据封装成 Call 对象,然后放入共享队列 callQueue。
3.最初,handlers 线程池都在 callQueue 上阻塞(BlockingQueue.take()),当有 Call 对象加入,其中一个 Handler 线程被唤醒。根据 Call 对象上的信息,调用 Server.call() 方法(类似 Client.call() ),反序列化并执行 RPC 请求对应的本地函数,最后将响应返回写入 SocketChannel。
4.Responder 线程起着缓冲作用。当有大量响应或网络不佳时,Handler 不能将完整的响应返回客户端,会在 Responder 的 respondSelector 上注册 OP_WRITE 事件,当监听到写条件时,会唤醒 Responder 返回响应。
整个 HadoopRPC 工作流程如图 5 所示。其中,动态代理与反射执行目标方法贯穿整个 Client 与 Server,Server 整体又采用 NIO Reactor 模式,使得整个 HadoopRPC 更加健壮。
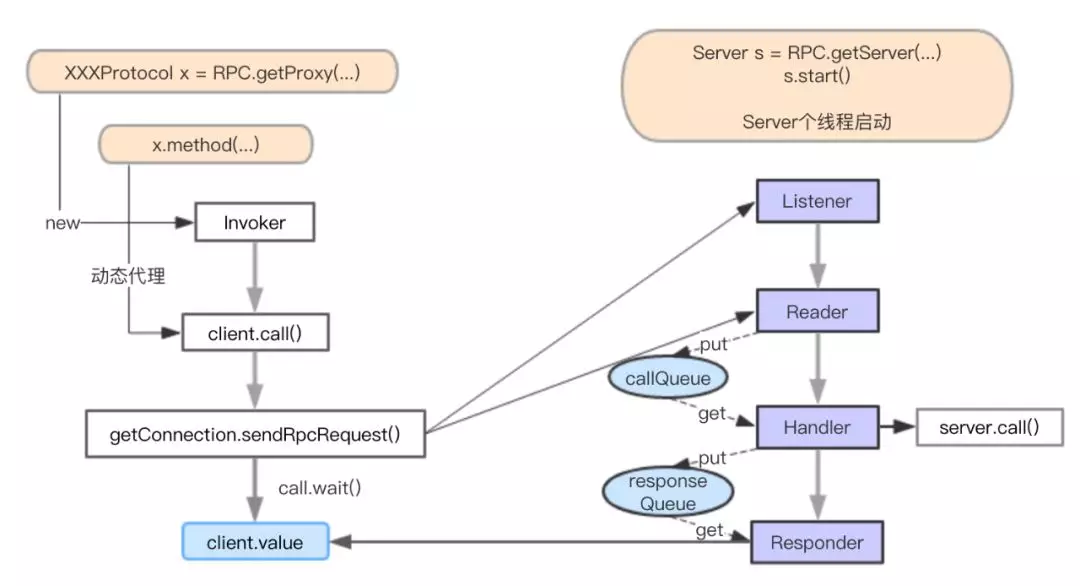
图 5 HadoopRPC 整体工作流程
3.关于并发时的优化
参与配置
Server 端仅存在一个 Listener 线程和 Responder 线程,而 Reader 线程和 Handler 线程却有多个,那个如何配置 Reader 与 Handler 线程个数呢?HadoopRPC 对外提供参数配置,使用常见的配置方式即在 etc/hadoop 下配置 xml 属性:
ipc.server.read.threadpool.size:Reader 线程数,默认 1
dfs.namenode.service.handler.count:Handler 线程数,默认 10
ipc.server.handler.queue.size:每个 Handler 处理的最大 Call 队列长度,默认 100。结合 Handler 线程数,则默认可处理的 callQueue 最大长度为 10*1000=1000
CallQueue 与 FairCallQueue
共享队列 CallQueue 以先进先出(FIFO)方式提供请求,如果 99% 的请求来自一个用户,则 99% 的时间将会为一个用户服务。因此,恶意用户便可以通过每秒发出许多请求来影响 NameNode 性能。为了防止某个用户的 cleint 的大量请求导致 NameNode 无法响应,HadoopRPC 引入 FairCallQueue 来替代共享队列 CallQueue,请求多的用户将会被请求降级处理。CallQueue 和 FairCallQueue 对比图如图 6、图 7 所示。

图 6 CallQueue 示例图
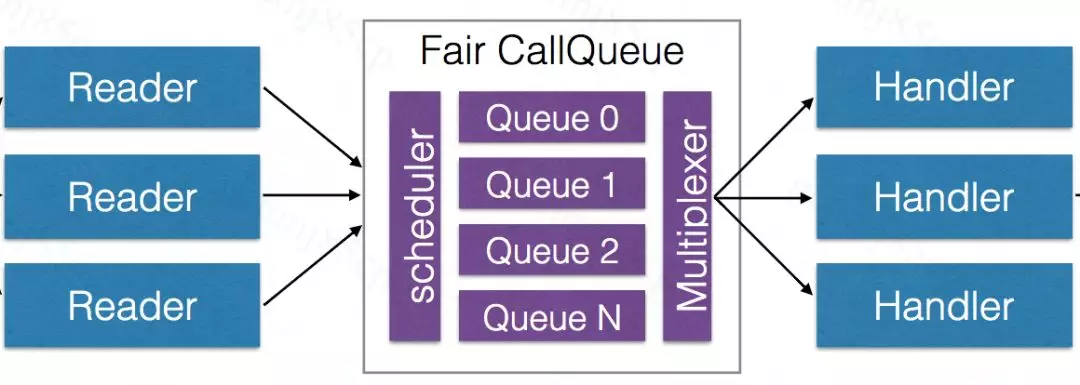
图 7 FairCallQueue 示例图
启用 FairCallQueue,同样是在配置文件中修改 Queue 的实现 callqueue.impl。其中,FairCallQueue 引入了优先级机制,具体分析如下。
优先级
共享队列 callQueue 导致 RPC 拥塞,主要原因是将 Call 对象放在一起处理。FairCallQueue 首先改进的是划分出优先级关系,每个优先级对应一个队列,比如 Queue0,Queue1,Queue2 …,然后定义一个规则,数字越小的,优先级越高。
优先级确定
如何确定哪些请求该放到哪些优先级队列中呢?比较智能的做法是根据用户的请求频率确定优先级。频率越高,分到优先级越低的队列。比如,在相同时限内,A 用户请求 50 次,B 用户请求 5 次,则 B 用户将放入优先级较高的队列。这就涉及到在一定时限内统计用户请求频率,FairCallQueue 进入了一种频率衰减算法,前面时段内的计数结果通过衰减因子在下一轮的计算中,占比逐步衰减,这种做法比完全清零统计要平滑得多。相关代码如下:
从注释可知,衰减调度将对请求进行间隔几秒钟的计数统计,用于平滑计数。
优先级权重
为了防止低优先级队列“饥饿”,用轮询的方式从各个队列中取出一定的批次请求,再针对各个队列设置一个理论比重。FairCallQueue 采用加权轮询算法,相关代码及注释如下:
从注释可知,若 Q0、Q1、Q2 的比重为 9:4:1,理想情况下在 15 次请求中,Q0 队列处理 9 次请求,Q1 队列处理 4 次请求,Q2 队列处理 1 次请求。
4.从一个命令解析
接下来将从常见的一条命令解读 HadoopRPC 在 HDFS 中的应用:
首先看一下 hadoop 目录结构:
其中 hadoop 即为 bin 目录下的 hadoop 脚本,找到相关脚本:
由脚本可知,最终执行了 java -OPT xxx org.apache.hadoop.fs.FsShell -mkdir /user/test ,转换为最熟悉的 java 类调用。
进入 org.apache.hadoop.fs.FsShell 类的 main 方法中,调用 ToolRunner.run(),并由 FsShell.run() 根据参数“-mkdir”解析出对应的 Command 对象。最后由 ClientProtocol.mkdirs() 发送 RPC 请求,向 NameNode 请求创建文件夹。相关代码如下:
rpcProxy.mkdirs() 过程则 HadoopRPC 完成。
4.小结
HadoopRPC 是优秀的、高性能的 RPC 框架,不管是设计模式,还是其他细节技巧都值得开发者学习。
本文转载自公众号滴滴技术(ID:didi_tech)。
原文链接:
https://mp.weixin.qq.com/s/MnQTPty0h1Go8QyOK6XzPA

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论