

本文由 dbaplus 社群授权转载。
背景
随着公司业务发展,大数据集群规模正在不断扩大,一些大型集群物理机节点甚至已近上千。面对如此规模庞大的集群,一套优秀的监控系统是运维人员发现及处理故障的关键利器。经过多次选型和迭代,笔者选择了 Prometheus,这款时下火热而强大的开源监控组件为核心来构建大数据集群监控平台。
最初的监控平台选型
公司最初采用的监控平台为 Nagios+Ganglia 或 Zabbix+Grafana 组合,但经过上线后长时间实践验证,发现这两个组合存在如下不尽人意之处:
Nagios+Ganglia
该搭配的主要问题在于 Nagios 只能对主机性能指标进行常规监控,在对大数据集群各组件进行监控时,则需要进行大量的自定义开发工作,且对集群的监控维度并不全面。而且由于 Nagiso 没有存储历史数据的功能,在面对一些集群性能分析或故障分析工作时,Nagios+Ganglia 的搭配效果并不能达到运维人员的预期。
Zabbix+Ganglia
相比于前者,该搭配优点在于可以完成监控数据可视化的工作,在集群性能分析和故障分析方面能够实现运维人员的各类需求,且对外提供 web 管理页面,能够简化上手难度。虽然如此,该搭配还是存在一些问题,例如当集群达到一定数量规模时,监控存储数据库就会成为性能瓶颈,面对大规模的数据读写会捉襟见肘,导致 Grafana 查询缓慢甚至卡死。
监控平台选型优化
鉴于以上两种组合存在的缺点,根据实际工作需要,笔者对监控平台的选型进行了优化, 选择了 Prometheus+Alertmanager+Grafana 的组合 。之所以选择该组合作为平台核心,是因为其具有以下几点优势:
内置优秀的 TSDB 数据库,可以轻松应对大数据量并发查询,为运维人员提供关键指标;
强大的 Promql,可以通过各类内置函数,获取各维度搜索监控数据用于 Grafana 出图;
Prometheus 基于 Go 语言开发,Go 高效的运行效率,使其拥有天生的速度优势;
活跃的 Github 社区,提供丰富的 Client 库。
Prometheus+Alertmanager+Grafana 平台架构如下图所示:
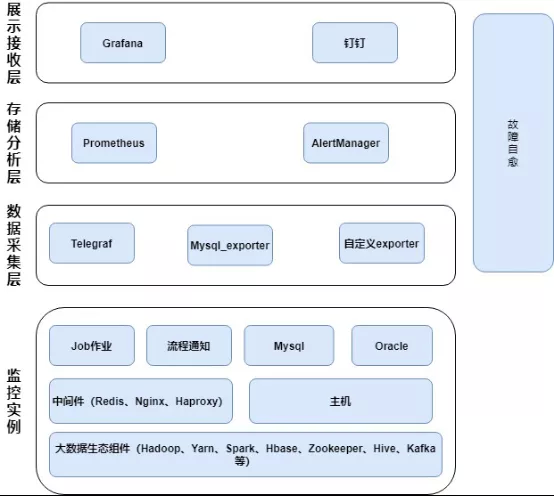
从图中可以看出,该套平台以 Prometheus 为核心,可实现对监控实例(如大数据组件、数据库、主机、中间件等,余者不再赘述)进行数据采集、分析计算、聚合抑制、智能发送、故障自愈等多种功能。并具有以下几个特点:
对于 Prometheus 官方或 Github 社区已有的 Exporter 库,如 Telegraf 及 Mysql_exporter 等,可以直接进行相关配置开箱即用,不必重复造轮子;
对于大数据生态组件如 Hadoop、Yarn、HBase 等,笔者并没有采用官方的 Jmx_exporter,因为一些特殊监控项并不能通过该组件采集到。而是自研一套 Exporter 针对各项组件进行监控,通过笔者自研的 Exporter,可以实现各类 RPC 操作负载,RPC 打开连接数、HDFS 空间及文件数监控,Yarn 总队列及子队列性能监控,Yarn job 作业性能监控,HBase 压缩及刷新队列性能监控等功能(详情见下文);
对于一些流程调度或数据具备、日周报等实时消息,可以引入该平台,进行通知消息实时发送(只通知不需要恢复);
故障自愈也是该平台的一个重要特点,对于大数据平台的常见故障如 Datanode、Nodemager、Regionserver 离线、硬盘故障、时钟异常等,都可以进行自动恢复(详情见下文)。
监控平台功能实现
适配大数据生态组件监控
Prometheus 性能虽然十分强大,但是适配大数据生态组件的监控却不是一件容易的事情。当下流行的搭配是用 Jmx_exporter 来采集各组件的监控数据供 Prometheus 拉取。这种搭配虽然可以满足开箱即用的原则,但是当运维人员关注一些组件特有的监控项时,因为 Jmx_exporter 没有收集相关监控项,就会捉襟见肘。
但通过笔者自研的 Exporter 定时采集组件 Jmx 或 CDH 版本的特定 API 的方式来获取监控数据,经过转换处理形成 Metrics 供 Prometheus 获取,则可以很好地解决上述问题。下面选取几个具有代表性的实例进行介绍:
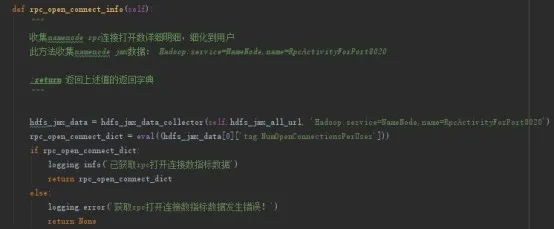
1、Namenode RPC 打开连接数
在排查 Namenode RPC 延迟的问题时,一定程度上,可以通过查看 RPC 打开连接数观察 Namenode 的工作负载情况。namenode 监控数据可通过 Url 地址 http://localhost:50070/jmx?qry=Hadoop:service=NameNode,name=RpcActivityForPort8020 查询。
访问该 url 数据后,通过一系列的转换,可以返回我们需要的格式化数据,如以下代码所示:
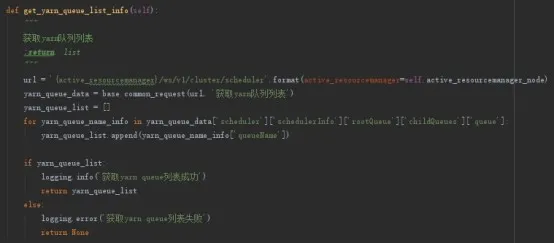
2、Yarn 队列获取
当处理多租户 Yarn 集群资源争抢问题的时候,运维人员最需要的就是获取 Yarn 各队列的资源使用情况。对此,首先要做的就是获取 yarn 队列列表,可以通过下面的 Url 来获取,http://localhost:8088/ws/v1/cluster/scheduler
范例代码如下:
实时消息发送
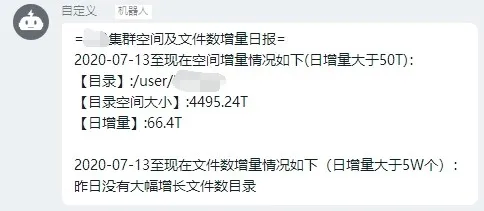
在生产环境中,有一些消息通知需要即时或定时发送到相关人员钉钉上,如果用 Prometheus 当做告警触发来完成,会导致这些消息通知一遍又一遍地发送到钉钉上,但事实上这些消息并不同于告警,只发送一次即可。面对这一问题,其实可以通过调用钉钉机器人 Webhook 发送即时消息进行解决,如以下一则实例:
笔者管理的某个多租户 HDFS 集群存储资源比较紧张,每个租户都有自己的单独目录,事先已针对这些目录进行了实时数据量及文件数使用统计,统计数据保存到 Prometheus 里。每天早上通过 Prometheus 的 API 来获取当日 8 时及前一日 8 时所有租户目录使用情况,并进行对比。当增量超过设定阈值时,就会发送一条实时消息到钉钉上,提醒对应租户管理数据。消息界面如下图所示:
故障自愈
当大数据集群总规模达到上千台时,对于一些常见故障如计算存储节点硬件故障导致离线、数据硬盘故障、NTP 时钟异常等,如果人肉手动处理,将会耗费大量时间和精力。但笔者目前使用的自愈系统则可以自动解决大部分常见故障。该自愈系统逻辑如下图所示:
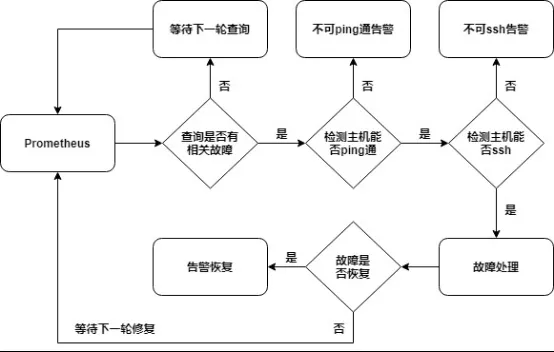
该自愈系统具有以下特点:
故障修复前自动检测主机联通性,对于异常主机可以直接转交主机侧同事处理;
各类通知智能发送,对于连接异常类消息,夜间(00:00-06:00)只发送一次,避免夜间无意义打扰;
沉淀各种常见故障修复过程,使故障修复更加精准智能;
监控自愈程序,如程序异常退出或修复过程中发生异常,可及时告知运维人员进行手动修复。
故障自愈通知界面如下:
1、自愈通知

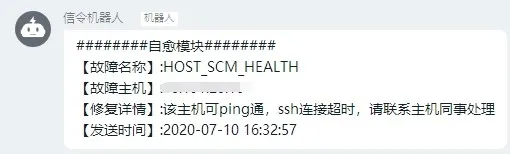
2、可 ping 通无法 ssh 主机通知:
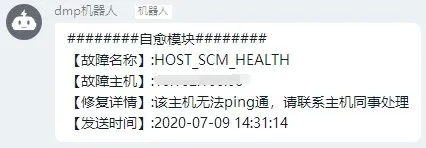
3、无法 ping 通主机通知:
监控成效
为了更加直观地实时查看监控平台各监控项情况,笔者引入了集群监控大屏进行可视化效果展示,动态展现数据变化,直观体现数据价值,大屏展示效果如下图所示:
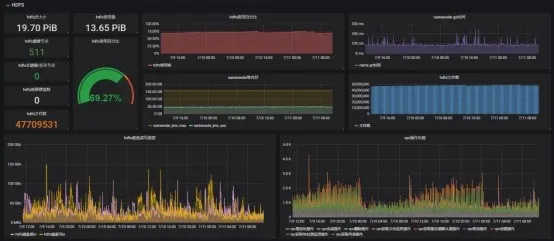
HDFS 基础指标展示(容量信息、健康节点、文件总数、集群 IO、RPC 负载、Namenode GC 情况等)
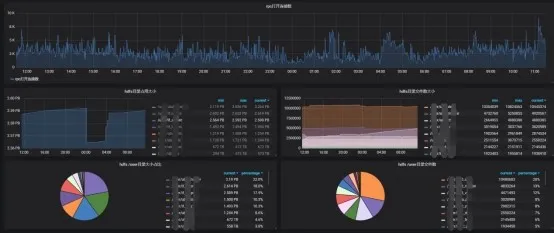
HDFS 定制监控展示(RPC 打开数、HDFS 租户目录数据大小/文件数监控、目录使用占比画像等)
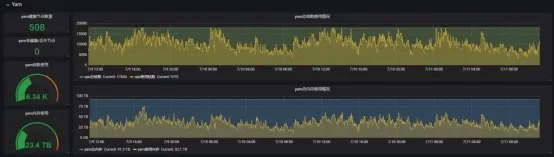
Yarn 基础信息展示(健康节点数、总队列及子队列资源监控等)
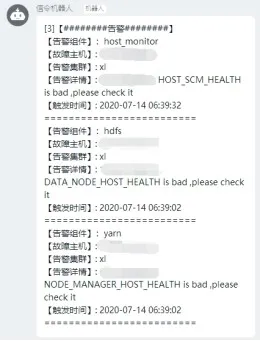
除此之外,监控集群各组件的健康状态,如有异常,也会通过钉钉消息告知运维人员,如下图所示:
集群告警通知:
多租户集群不可避免的就是租户计算资源抢占问题,当单个 Job 作业资源占用过大时,告警通知如下:
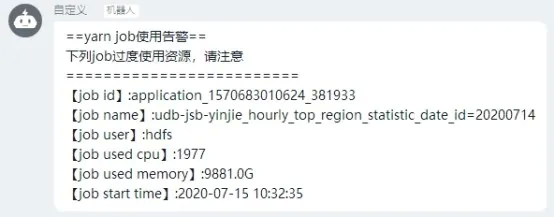
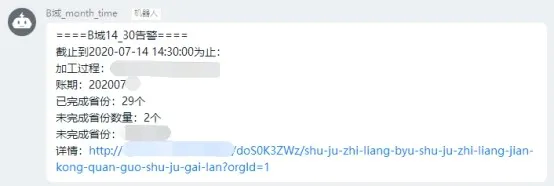
上文提到的数据具备、流程具备通知消息:
总结与展望
该套监控平台目前承载 10 个大型的大数据集群、50+个数据库、若干中间件及业务流程监控任务,平均每秒 5W 左右监控数据入库。通过对告警数据的精确分析、判断、预警,能够帮助运维人员深入了解业务集群及其他监控对象的运行状态,从而及时规避或协助处理严重问题,将隐患扼杀在萌芽之时。
接下来,笔者计划对监控平台的智能发送、存储周期及高可用性进行研究和优化,使其更加智能、高效、规范,并陆续向其他业务体系进行推广,打通与其他业务体系的数据交互通道,从而全面深度挖掘数据的价值。
作者介绍:
洪迪,联通大数据高级运维开发工程师,主要负责大数据平台运维管理及核心监控平台开发工作。具有多年大数据集群规划建设、性能调优及监控体系建设经验,对 Prometheus 架构设计、运维开发等方面有深入理解和实践。
原文链接:

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论