

作为稍微有点经验的 Java 开发者,应该多少都听过 Netty 的大名,但如果你要问 Netty 是什么,它的特色有哪些,实现机制如何,适用于什么场景并解决什么问题,能完整回答出来的人并不多。本文试着基于上述维度对 Netty 进行深入介绍,帮助读者对 Netty 知其然并知其所以然。
基础篇
Netty 是什么?
首先我们来看 Netty 是什么,关于这个问题,其官网有一段阐述:
Netty is a NIO client server framework which enables quick and easy development of network applications such as protocol servers and clients.
这段翻译过来意思就是:
Netty 是一个基于 NIO 的异步网络编程框架,基于 Netty 能快速的搭建高性能易扩展的网络应用(包括客户端与服务端)。
具体来说,Netty 就是对于 Java NIO 的封装,NIO 又是什么呢?NIO 是 Java 1.4 后引入的基于事件模型的非阻塞 IO 框架,在 NIO 之前,对于数据的处理都是基于 BIO(blocking IO),从名字上就知道 BIO 是以阻塞的形式对数据进行处理,这种处理形式比较简单,但是既然阻塞的,那么就不可避免会涉及到线程的操作。熟悉并发的小伙伴应该都知道,线程是一种昂贵的资源,无论是创建、销毁,还是切换,这就导致 BIO 在面对一些特定场景如高并发等束手无策,而这些场景在互联网应用中却又很常见。
对应的,NIO 能较好的应对这些场景。遗憾的是,Java 在刚推出 NIO 时,由于各种原因,致使其使用复杂,且经常会出现 Bug。结果就是:广大开发者有需求,但解决需求的工具就是不好用这样尴尬的局面,怎么办呢? -- 自己动手,丰衣食足!大不了再造个"轮子",所以就出现了一系列解决 NIO 问题的框架,而 Netty 就是其中最著名的那一个(当然 Java 发展到现在,其 NIO 库原本的很多问题都得到了解决,不过很多解决方案借鉴的也是 Netty 的思想)。
另外,Netty 并不止于解决 NIO 的问题,它更进一步,还提供了一系列特色功能。
Netty 的特色
下面是 Netty 官网对于 Netty 特色的说明:
It greatly simplifies and streamlines network programming such as TCP and UDP socket server
'Quick and easy' doesn't mean that a resulting application will suffer from a maintainability or a performance issue. Netty has been designed carefully with the experiences earned from the implementation of a lot of protocols such as FTP, SMTP, HTTP, and various binary and text-based legacy protocols. As a result, Netty has succeeded to find a way to achieve ease of development, performance, stability, and flexibility without a compromise
这段话大概的意思就是:
首先,Netty 能极大的简化你的网络编程;并且,简单好用还不需要以复杂的管理和低效的性能为代价,Netty 通过优秀的设计,在易部署,高性能,稳定性,扩展性之间找到了一个较好的平衡点
我们把这句话提炼出来,大概就可以得到 Netty 的几大特色:
针对基本的需求提供了简单易用的接口,直接上手!
针对复杂的场景提供了很强的扩展性,轻松应对业务发展!
在上面两点的基础上,性能不打折!
而如果对这些特点进行细化,则可以得出:
基于事件机制(Pipeline - Handler)达成关注点分离(消息编解码,协议编解码,业务处理)
可定制的线程处理模型,单线程,多线程池等
屏蔽 NIO 本身的 bug
性能上的优化
相较于 NIO 接口功能更丰富
对外提供统一的接口,底层支持 BIO 与 NIO 两种方式自由切换
这些特性将在本文第二部分「实现篇」里做详细分析;既然 Netty 的本质还是一个基于 NIO 的网络框架,那么想要掌握 Netty 的精髓,对于 NIO 的了解就不可或缺。
NIO 处理模型介绍
在介绍 NIO 之前,最好了解一下 BIO,还没有学习过的小伙伴可以阅读我另外一篇介绍 BIO 的文章:Java IO使用入门 -- IO其实很简单。
NIO 是 Java 1.4 引入的一种同步非阻塞的 I/O 模型,也是 I/O 多路复用的基础;相对于 Java BIO(OIO)提供的基于面向流的阻塞式编程模型,NIO 提供的是面向缓冲区的响应式事件编程模型。

读到这里可能有些人会觉得迷糊,什么阻塞?非阻塞?基于流?基于缓冲区?这里有必要介绍一下 Linux 下的 5 中 IO 模型:
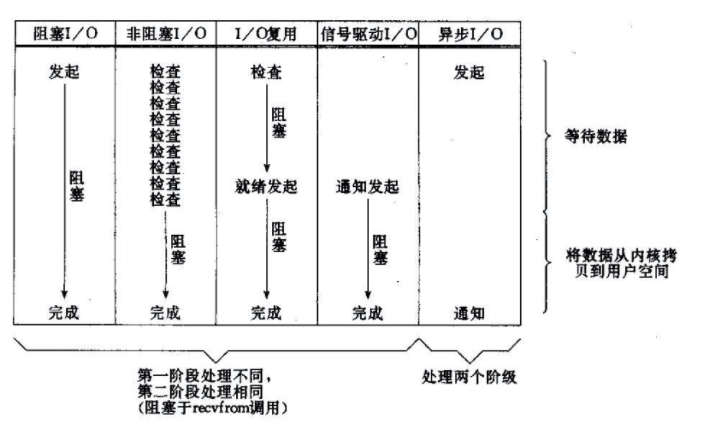
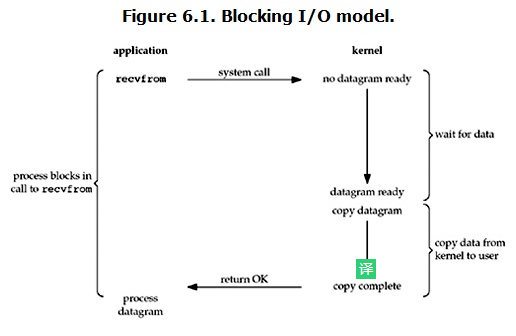
阻塞 I/O 模型:最常用的 I/O 模型就是阻塞 I/O 模型,当用户进程调用了 recvfrom 这个系统调用,kernel 就开始了 IO 的第一个阶段:准备数据(对于网络 IO 来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的 UDP 包。这个时候 kernel 就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞。当 kernel 一直等到数据准备好了,它就会将数据从 kernel 中拷贝到用户内存,然后 kernel 返回结果,用户进程才解除 block 的状态,重新运行起来。所以,blocking IO 的特点就是在 IO 执行的两个阶段都被 block 了。
非阻塞 IO 模型:linux 下,可以通过设置 socket 使其变为 non-blocking。当对一个 non-blocking socket 执行读操作时,流程是这个样子:
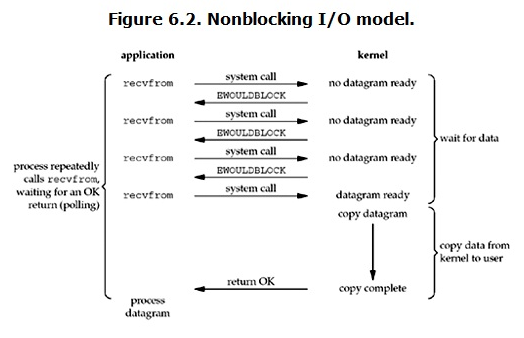
当用户进程发出 read 操作时,如果 kernel 中的数据还没有准备好,那么它并不会 block 用户进程,而是立刻返回一个 error。从用户进程角度讲 ,它发起一个 read 操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个 error 时,它就知道数据还没有准备好,于是它可以再次发送 read 操作。一旦 kernel 中的数据准备好了,并且又再次收到了用户进程的 system call,那么它马上就将数据拷贝到了用户内存,然后返回;所以,nonblocking IO 的特点是用户进程需要不断的主动询问 kernel 数据好了没有。
IO 复用模型:IO multiplexing 就是我们说的 select,poll,epoll,有些地方也称这种 IO 方式为 event driven IO。select/epoll 的好处就在于单个 process 就可以同时处理多个网络连接的 IO。它的基本原理就是 select,poll,epoll 这个 function 会不断的轮询所负责的所有 socket,当某个 socket 有数据到达了,就通知用户进程。
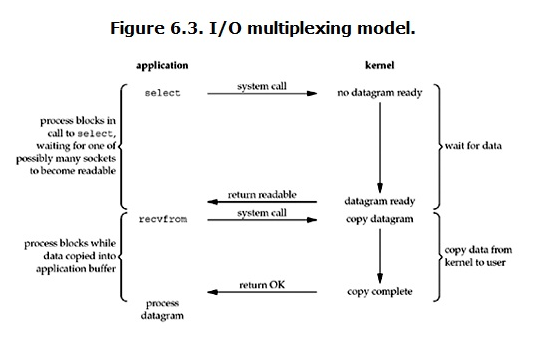
当用户进程调用了 select,那么整个进程会被 block,而同时,kernel 会监视所有 select 负责的 socket,当任何一个 socket 中的数据准备好了,select 就会返回。这个时候用户进程再调用 read 操作,内核负责将数据从 kernel 拷贝到用户进程;所以,I/O 多路复用的特点是通过一种机制使得一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回,所以说它最大的优势是系统开销小,系统不需要创建或维护新的进程/线程。另外,从上面比较 IO 复用流程图和阻塞 IO 的图可以发现,多路复用本身也是阻塞的,事实上,其效率可能还更差一些。因为这里需要使用两个 system call (select 和 recvfrom),而阻塞 IO 只调用了一个 system call (recvfrom)。但是,用 select 的优势在于它可以同时处理多个 connection。所以,如果处理的连接数不是很高的话,使用 select/epoll 的 web server 不一定比使用阻塞 IO 的 web server 性能更好,可能延迟还更大。select/epoll 的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。)在 IO 复用模型中,对于每一个 socket,一般都设置成为 non-blocking,但是,如上图所示,整个用户的 process 其实是一直被 block 的。只不过 process 是被 select 这个函数 block,而不是被 socket IO 给 block。
信号驱动 IO 模型:首先开启套接口信号驱动 I/O 功能,并通过系统调用 sigaction 执行一个信号处理函数(此系统调用立即返回,进程继续工作,它是非阻塞的)。当数据准备就绪时,就为该进程生成一个 SIGIO 信号。随即可以在信号处理程序中调用 recvfrom 来读数据,井通知主循环函数处理数据;一般用的较少。
异步 IO:在异步 IO 模型下,用户进程发起 read 操作之后,立刻就可以开始去做其它的事。而另一方面,从 kernel 的角度,当它收到一个 asynchronous read 之后,首先它会立刻返回,所以不会对用户进程产生任何 block。然后,kernel 会等待数据准备完成,然后依然由它将数据拷贝到用户内存,当这一切都完成之后,kernel 会给用户进程发送一个 signal,告诉它 read 操作完成了。
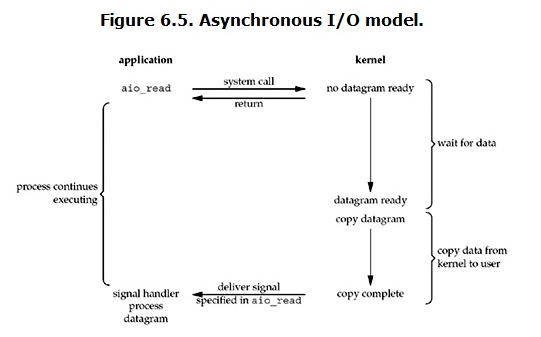
介绍完这 5 种 IO 模型后,我们回到 NIO,NIO 基于的是 IO 复用模型(就是上面的第三种 IO 模型),正如在介绍 IO 复用模型时已提到,而在 linux 下,有三种针对该模型的实现,分别为:select,poll,epoll;select 和 poll 的实现机制类似,主要区别在于描述 fd 集合的方式不同,poll 使用 pollfd 结构而不是 select 的 fd_set 结构;epoll 是 linux 2.6 后才有的,它主要是对 select 和 poll 的缺陷做了一些改进。
这两种实现方式有几个比较大的缺点:1) 每次调用 select,都需要把 fd 集合从用户态拷贝到内核态,这个开销在 fd 很多时会很大 2) 每次调用 select 都需要在内核遍历传递进来的所有 fd,这个开销在 fd 很多时也很大 3) select 支持的文件描述符数量太小了,默认是 1024(当然可以手动改,但改大了不一定效果好,以为前面的 1,2 两点)对于第一个缺点,epoll 在每次注册新的事件到 epoll 句柄中时,会把所有的 fd 拷贝进内核,而不是在 epoll_wait 的时候重复拷贝。这样就保证了每个 fd 在整个过程中只会拷贝一次。
对于第二个缺点,epoll 的解决思路是每当一个 fd 准备就绪,就调用对应的回调函数将其加入一个就绪链表,然后只需要遍历这个就绪链表即可,不需要遍历所有 fd。
对于第三个缺点,epoll 没有这个限制,它所支持的 fd 上限是最大可以打开文件的数目,这个数字一般远大于 1024,举个例子,在 1GB 内存的机器上大约是 10 万左右,具体数目可以 cat /proc/sys/fs/file-max 察看,一般来说这个数目和系统内存关系很大。
另外顺便提一下 Windows 下的异步 IO 实现机制:I/O Completion Ports,或简称 IOCP,个人觉得它的设计比较好,极大的减少线程切换对性能的影响,同时又能保证 CPU 保持在较高的利用率,有兴趣可以阅读:https://learn.microsoft.com/en-us/windows/win32/fileio/i-o-completion-ports。
实现篇
Netty 总体结构
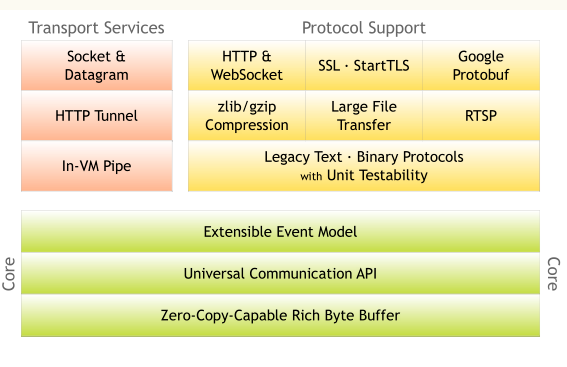
这张图摘自 Netty 官网,其展示的是 Netty 的模块结构,总体来说,Netty 分为两大模块:
核心模块核心模块主要提供的是 Netty 的一些基础类和底层接口,主要包含三部分:
用以提升性能,减少资源占用的 Zero-Copy-Capable Rich Byte Buffer,即「零拷贝」缓冲区,Netty 里的「零拷贝」与操作系统语境下的「零拷贝」不是同一个概念,具体会在后续章节做阐述。
统一的 API,这是 Netty 对外宣传的简单易用 API 的一部分,什么意思呢?就是 Netty 为同步和异步 IO 提供统一的编程接口,举个例子,如果在前期希望使用 BIO,后续随着业务变动,希望改用 NIO,只需要改动几个简单的初始化参数,而不需要变动主体流程;相反,如果一开始不是基于 Netty,而是直接基于 BIO 书写处理流程,后期想改成 NIO,其变动是很大的,毕竟是两个不同的接口模块。
易扩展的事件模型,这里的重点在于易扩展,因为 NIO 本身就是基于事件的 IO 模型,而扩展性很好理解,如果一个框架无法扩展,那么也就意味着无法应对业务的变化。
服务模块既然 Netty 的核心是 IO,那么其服务模块基本也就和 IO 操作分不开了,主要有:
网络接口数据处理相关服务,如报文的粘包,拆包处理,数据的加密,解密等
各网络层协议实现服务,主要包括传输层和应用层相关网络协议的实现
文件处理相关服务
Netty 处理架构
介绍完 Netty 的模块结构,我们再来看一下它的处理架构:
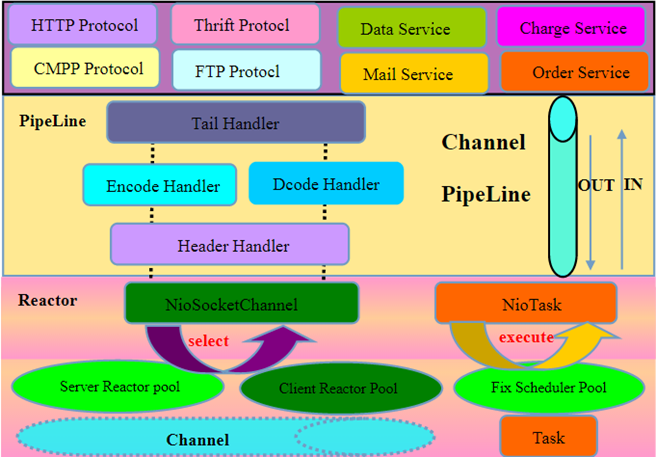
Netty 的架构也很清晰,就三层:
底层 IO 复用层,负责实现多路复用。
通用数据处理层,主要对传输层的数据在进和出两个方向进行拦截处理,如编/解码,粘包处理等。
应用实现层,开发者在使用 Netty 的时候基本就在这一层上折腾,同时 Netty 本身已经在这一层提供了一些常用的实现,如 HTTP 协议,FTP 协议等。
一般来说,数据从网络传递给 IO 复用层,IO 复用层收到数据后会将数据传递给上层进行处理,这一层会通过一系列的处理 Handler 以及应用服务对数据进行处理,然后返回给 IO 复用层,通过它再传回网络
基于 Reactor 模式的 IO 复用
在 Netty 处理架构图中,可以看到在 IO 复用层上标注了一个「Reactor」:
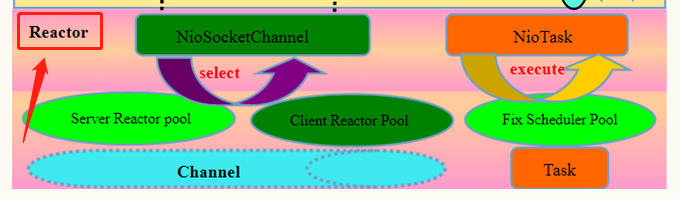
这个「Reactor」代表的就是其 IO 复用层具体的实现模式 -- Reactor 模式
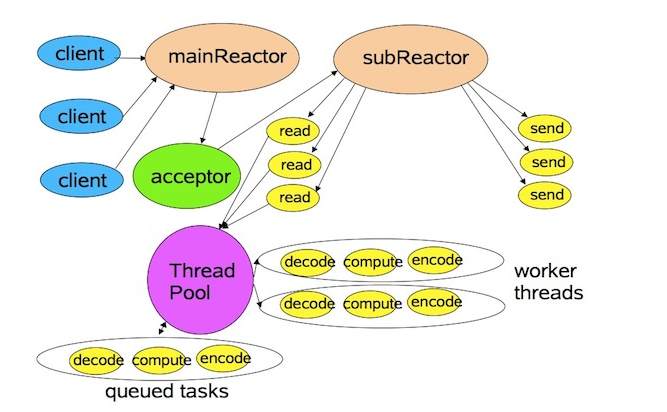
这张图是从大名鼎鼎的Doug Lea的一份演讲稿中截取下来的,通过这张图示,就可以大致明白什么是 Reactor 模式了。在 Reactor 模式中,分为主反应组(MainReactor)和子反应组(subReactor)以及 ThreadPool,主反应组(MainReactor)负责处理连接,连接建立完成以后由主线程对应的 acceptor 将后续的数据处理(read/write)分发给子反应组(subReactor)进行处理,而 Threadpool 对应的是业务处理线程池;对应代码为:
在这段代码中 bossGroup 对应的就是主反应组(MainReactor),workerGroup 对应的是子反应组(subReactor),而NioEventLoopGroup其实就是一个实现了 Java ExecutorService的线程池,其中的线程数可定制,若不设置线程数参数,则该参数值默认为2 * CPU核数量,在ServerBootstrap的初始化过程中,会为其添加一个实现了acceptor机制的Handler
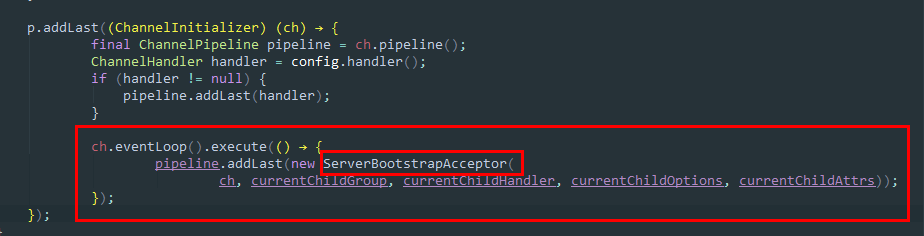
而通过ServerBootstrapAcceptor,会在 Channel 建立后触发channelRead()方法,并在channelRead()内将此 Channel 绑定至子反应组对应的处理线程,后续的数据处理就交于它进行处理
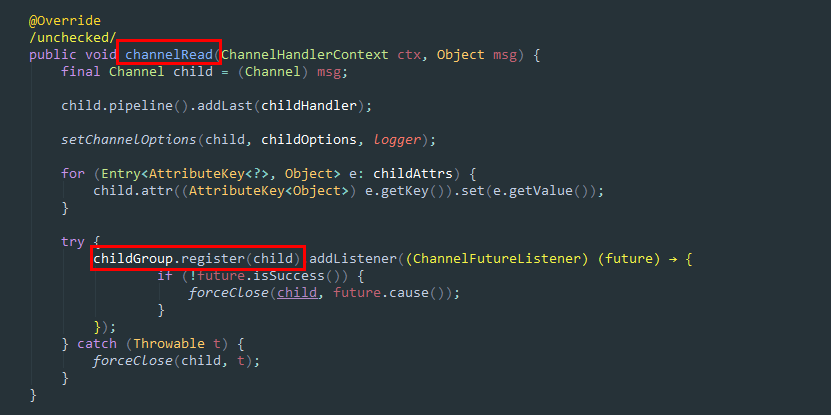
在阅读这部分源码的时候需要注意一个点,按理来说,连接的建立应该是ACCEPT事件,怎么会触发channelRead()呢 ?其实 netty 内部将READ和ACCEPT状态一并作为 read 的触发条件。
介绍完了 Netty 关于 IO 复用层的实现,继续看其「易扩展」和「关注点分离」的核心:Pipeline。
基于责任链模式的 Channel-Pipeline
同样回过头去再看 Netty 处理架构图中的中间层 -- Pipeline。
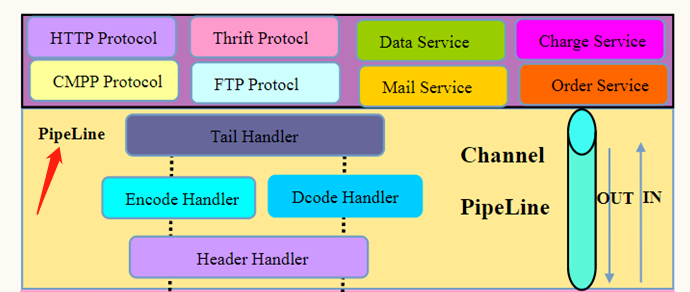
其字面意思为「管道」,顾名思义,管道的作用就在于传输,而对于 Netty 来说,它的管道传输的当然就是数据了,在本位「基础篇」关于 Netty 基础的介绍里,提到它有一个很重要的特色就在于:基于事件机制(Pipeline - Handler)达成关注点分离(消息编解码,协议编解码,业务处理),而Pipeline就是实现这一特色的核心所在,我们下面来看 Netty 是如何实现所谓的「易扩展」和「关注点分离」的。
首先,Netty 的Pipeline从数据传输的方向上来看分为进和出,这个和 BIO 相同;其次,最重要的在于 Netty 在Pipeline上通过责任链模式插入一系列的「Handler」,这一结构是它能实现「易扩展」和「关注点分离」的关键。想想看,所谓 IO,不就是数据的「进」和「出」吗?而进来干啥呢?当然就是需要应用逻辑对其处理,那处理完了呢?还需要送回给请求方以示响应,而在进的过程中需要哪些处理逻辑,这些处理逻辑的先后顺序如何,处理完后出去的过程中需要哪些处理逻辑,这些处理逻辑的顺序又是如何,如果这些都可以方便的配置调整,是不是就达到了 Netty 宣称的「易扩展」和「关注点分离」(只需关注业务相关的 Handler,网络协议相关的 Handler 直接调用即可,IO 复用更无须关注)呢?
在 Netty 里,这一实现机制的核心类叫做ChannelPipeline:
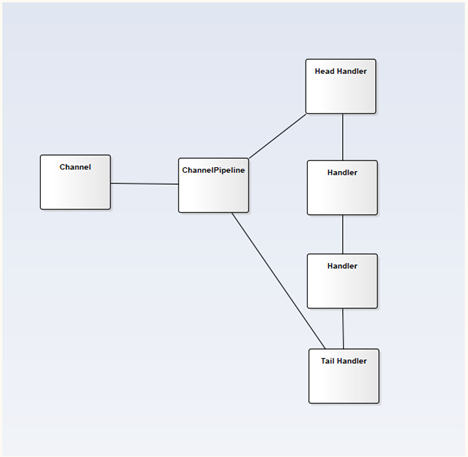
其中Channel负责数据通信,Handler负责逻辑处理,而ChannelPipeline就相当于一个由Handler串起来的处理链条,在 Neety 源码里有一个关于ChannelPipeline的比较形象的图形化描述:
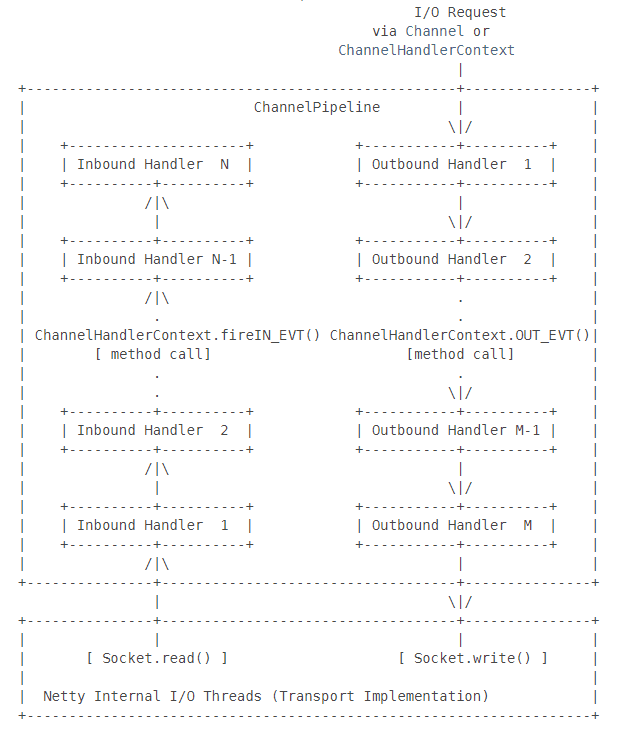
看到没有,其实很简单,就是一个针对不同方向数据流的责任链,其中Inbound对应的是输入流,Outbound对应的是输出流(在这里再多提一句,责任链模式在很多框架里都有使用,比如 Spring MVC 里看到的各种 Handler,也是基于责任链的封装)。
强大的 ByteBuf
既然是对 Netty 进行分析,就必然绕不过 Netty 自己封装的数据缓冲区:ByteBuf,它是 Netty 对外宣称的高性能的重要支撑,另外有必要提一下,在 Netty 里其核心缓冲区类叫「ByteBuf」,以便与 NIO 本身的缓冲区类「ByteBuffer」做区分,ByteBuf 有如下特点:
功能丰富的接口,Java NIO 本身的缓冲区接口比较简单
支持零拷贝,提升性能,减少资源占用
支持动态扩展
缓冲区初始块大小动态控制
读写切换不需要手动调用 clear(),flip();使用过 Java NIO 的小伙伴应该知道,其在进行读写切换时需要不停的通过 clear()和 flip()进行模式切换,很麻烦
池化,提升性能,减少资源占用
下面将对上面提到的几个 ByteBuf 的重要特性进行实现分析,首先来看下 ByteBuf 是如何避免 NIO 中那繁琐的读写切换的。我们知道,对于 Java NIO 的 Buffer,其有几个重要的属性:position,limit,capacity,其中position代表的是下一个读或写的位置,limit是可被读或写的最高位,而capacity就是 Buffer 的容量了,之所以要在读和写切换的时候进行手动操作(clear(),flip()),主要是因为在 NIO 中,position和limit在读的时候代表的是下一个需读的位和可读的最高位,但是在写的时候又代表下一个需写的位和可写的最高位(其实就是capacity),换句话说这两个变量在不同的操作场景下有不同的含义,对应值也不同,所以需要在读写切换的时候进行手动操作。

而 Netty 的 ByteBuf 则对这一点做了改进,其针对读写操作分别增加上了readerIndex,writerIndex,使用的时候不需要考虑读写转换。
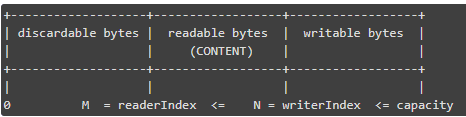
读的时候就变动readerIndex的值,而此时可读的最高位(对应 NIO 中的 limit)其实就是writerIndex,同理写的时候就变动writerIndex,此时可写的最高位(对应 NIO 中的 limit)就是capacity,说白了就是两个变量分别管理读和写的操作位,互不冲突,也就不存在读写切换的时候手动操作了;其实看到这里我们可以发现,NIO 在接口设计的时候确实没有考虑周到,毕竟 Netty 的这种优化并不是有多难!
零拷贝 Buf
在分析 ByteBuf 的「零拷贝」特性之前,先说说什么是「零拷贝」,所谓「零拷贝」, 通常指的是在 OS 层面上为了避免在用户态(User-space) 与 内核态(Kernel-space) 之间进行数据拷贝而采取的性能优化措施;例如 Linux 提供的 mmap 系统调用,它可以将一段用户空间内存映射到内核空间,当映射成功后,用户对这段内存区域的修改可以直接反映到内核空间;同样地,内核空间对这段区域的修改也直接反映用户空间。正因为有这样的映射关系,我们就不需要在用户态(User-space) 与内核态(Kernel-space) 之间拷贝数据,从而提高了数据传输的效率;对于 Java 的网络操作来说,网络接口在收到数据的时候需要先将数据复制到内核内存,然后在从内核内存复制到用户内存,同理往网络接口发数据也是先将数据从用户内存复制到内核内存,再从内核内存中将数据传给网络接口,所以如果是直接操纵内核内存,无疑处理的性能会更好。
回到 Netty,Netty 中的 「零拷贝」与上面我们所提到到 OS 层面上的 「零拷贝」其实不太一样,Netty 的 「零拷贝」 完全是在用户态里的,或者说更多的是偏向于减少 JVM 内的数据操作,具体体现在如下几个方面:
通过
CompositeByteBuf类,将多个ByteBuf合并为一个逻辑上的ByteBuf,避免了各个ByteBuf之间的拷贝通过
wrap操作,将byte[]数组、ByteBuf、ByteBuffer等多个数据容器合并成一个ByteBuf对象,进而避免了拷贝操作通过
slice操作,将ByteBuf分解为多个共享同一个存储区域的ByteBuf,避免了内存的拷贝通过
FileRegion包装的FileChannel.tranferTo实现文件传输,将文件缓冲区的数据发送到目标Channel,避免了传统通过循环write方式导致的内存拷贝问题
这些操作之所以能避免不必要的拷贝操作,其实就在于内部对数据进行的是逻辑操作而非物理操作,操作完成后根据各逻辑引用的数据信息(大小,位置等)重新计算ByteBuf内部的控制属性(limit,capacity,readerIndex,writerIndex),如通过CompositeByteBuf将原本两个分别表示 head 和 body 的 buffer 组装成一个 buffer:
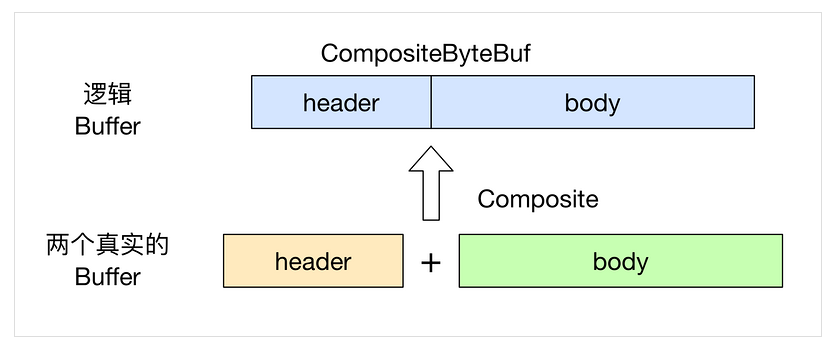
虽然看起来CompositeByteBuf是由两个ByteBuf组合而成的,不过在CompositeByteBuf内部,这两个ByteBuf都是单独存在的(指针引用),CompositeByteBuf只是逻辑上是一个整体;这样在数据操作的时候不需要对数据进行物理挪动,只需要操作数据引用并计算关键因子即可,这种方式不但能提升性能,还可以减少内存占用,值得借鉴。
Buf 池化
在 Netty 中,ByteBuf 用来作为数据的容器,是一种会被频繁创建和销毁的对象,ByteBuf 需要的内存空间,可以在 JVM Heap 中申请分配,也可以在 Direct Memory(堆外内存)中申请,其中在 Direct Memory 中分配的 ByteBuf,其创建和销毁的代价比在 JVM Heap 中的更高,但抛开哪个代价高哪个代价低不说,光是频繁创建和频繁销毁这一点,就已奠定了效率不高的基调。Netty 为了解决这个问题,引入了池化技术,池化技术的思想不复杂,和线程池思想类似,说白了就是对一些可重用的对象用完不回收,后面需要再次使用,以减少创建和销毁对象带来的资源损耗,下面结合 Netty 源码对其池化技术做剖析。
首先看ByteBuf,它实现了ReferenceCounted接口,表明该类是一个引用计数管理对象
而引用计数就是实现池化的关键技术点(不过并非只有池化的 ByteBuf 才有引用计数,非池化的也会有引用),继续看ReferenceCounted接口,它定义了这几个方法:
每一个引用计数对象,都维护了一个自身的引用计数,当第一次被创建时,引用计数为 1,通过refCnt()方法可以得到当前的引用计数,retain()和retain(int increment)增加自身的引用计数值,而release()和release(int increment)则减少当前的引用计数值,如果引用计数值为 0,并且当前的 ByteBuf 被释放成功,那这两个方法的返回值就为true。而具体如何释放,各种不同类型的 ByteBuf 自己决定,如果是池化的 ByteBuf,那么就会重新进池子,以待重用;如果是非池化的,则销毁底层的字节数组引用或者释放对应的堆外内存。具体的逻辑在AbstractReferenceCountedByteBuf类中可以看到:
释放对象的方法定义在 deallocate() 方法里,它是个抽象方法,既然是抽象的,那么就需要子类自行实现,对于非池化的 HeapByteBuf 来说,释放对象实际上就是释放底层字节数组的引用:
对于非池化的DirectByteBuf来说,释放对象实际上就是释放堆外内存:
对于池化的 ByteBuf 来说,就是把自己归还到对象池里:
熟悉 JVM GC 的同学应该对这个引用计数的机制不会感到陌生,因为 JVM 在判断一个 Java 对象是否存活时有一种方式使用的就是计数法;另外 Netty 的池化缓存在实现上借鉴了buddy allocation和slab allocation的思想并进行了比较复杂的设计(buddy allocation 是基于一定规则对内存进行分割,回收时进行合并,尽可能保证系统有足够的连续内存;而 slab allocation 是把内存分割为大小不等的内存块,请求内存是分配最贴近请求 size 的内存块,避免内存浪费),可以减少对象的创建与销毁对性能的影响,因为缓冲区对象的创建与销毁会占用内存带宽以及 GC 资源,另外由于池化缓存本身比较复杂,如线程私有池与全局共有池,其声明与释放都需要手动处理(比如本地池内的缓冲区对象如果不是在同一个线程内释放就会导致内存泄漏,这也是为什么 JVM GC 的时候需要有 Stop The World),Netty 提供了内存泄漏监控工具ResourceLeakDetector,如果发生了内存泄漏,它会通过日志记录并提醒,这个工具主要是防止对象被 GC 的时候其占用的资源没有被释放(如内存),或者没有执行release方法
也许有人会说,既然池化缓存实现复杂,用起来还得防止内存泄漏,那么它到底能给性能带来多大提升呢?我们可以看下 Twitter 对 Netty 池化缓存做的性能测试结果:
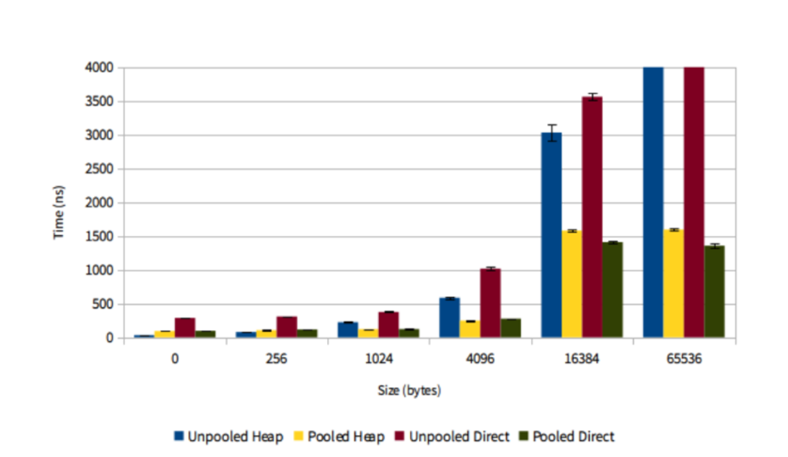
这张图的 Y 轴显示的是创建对象花费的时间,而 X 轴代表的是所创建对象的大小,同时在实验中,使用了四种不同的对象,分别是非池化堆内存对象(Unpooled Heap),池化堆内存对象(Pooled Heap),非池化直接内存对象(Unpooled Direct),池化直接内存对象(Pooled Direct)。结果现实,随着被创建对象大小的增加,池化技术的优势愈加明显,当然当对象很小时,池化反而不如 JVM 本身的对象创建性能(可以结合 ByteBuf 的实现原理,想想为什么?)
除了对象创建的性能,Twitter 还测试了使用池化技术时 GC 相关的表现,实验模拟了在 16000 个连接下,对 256byte 大小的数据包进行循环传输:

结果表明,相对于非池化,池化的 GC 停顿减少了近 4 倍,而垃圾的增长也慢了 4 倍。所以说,Netty 对 ByteBuf 进行的复杂的重写还是值得的。
NIO epoll 死循环问题及 Netty 解决方案
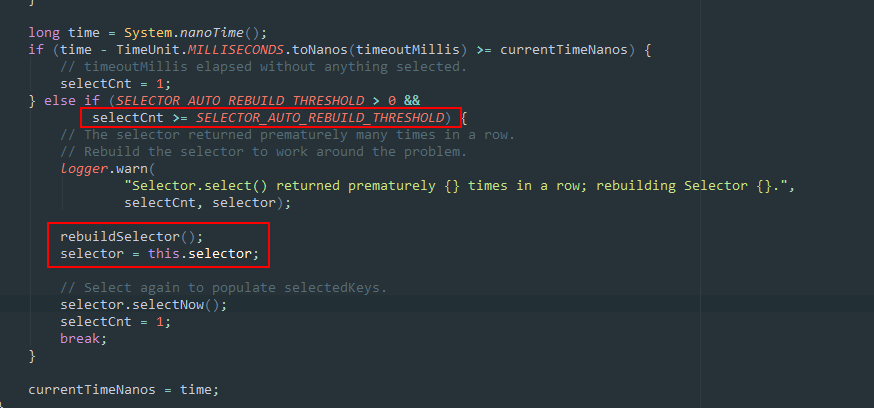
最后说说 Netty 是如何解决著名的「NIO epoll 死循环」问题的。什么是「NIO epoll 死循环」呢?在 Linux 系统中,当某个 socket 的连接突然中断后,会重设事件集 eventSet,而 eventSet 的重设就会导致 Selector 被唤醒(但其实这个时候是没有任何事件需要处理的,select()方法应该还是处于阻塞状态),虽然被唤醒了,但其实是没有事件需要处理的,所以就又返回select()方法之前(正常情况下是处理完事件重新回去被select()阻塞),此时select()方法还是会直接返回,如此反复便造成死循环:

这个问题的原因本质上就是 NIO 的 Selector 实现有问题,Netty 解决的方式其实比较简单粗暴,它会记录一段时间内空轮询的次数,如果超过一定阈值,就认为这个 bug 出现了,此时会重新生成一个新的 selector 取代旧的 selector,避免死循环,具体的处理代码在NioEventLoop中:
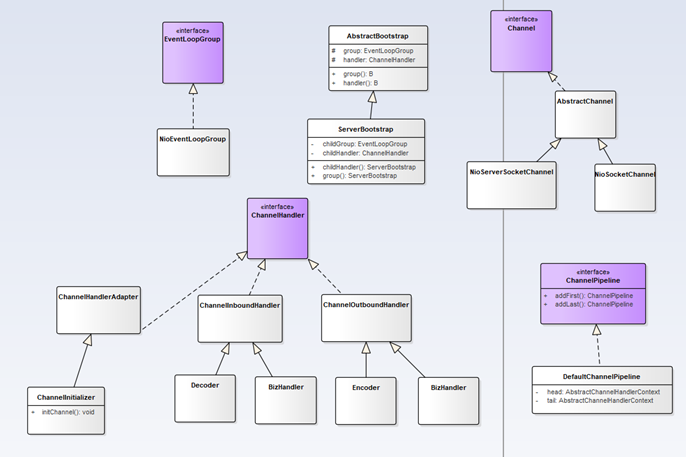
Netty 主要类关系图
这里贴一张 Netty 主要实现类的关系图,对需要阅读 Netty 源码的小伙伴可能有一个参考作用
总结篇
Netty 适用场景
Netty 只是一套网络框架,它不可能适用于所有场景,所以选用 Netty 前最好能想清楚它是否能很好的应对自己的需求。想要知道 Netty 的适用场景最好的方式就是从 Netty 本身的特性出发进行思考,具体可参考本文「基础篇」中「Netty 的特色」章节,基于此,如果你的需求属于下列场景,则 Netty 会比较适合你,包括:
高并发,实时处理,如:游戏服务器,聊天服务器,SOA 调用框架,RPC 框架等。
对网络协议(传输层与应用层)有一定的定制需求。
一套代码可能需要同时支持 BIO 和 NIO。
而其他情况,Netty 并一不定适合,如:
需求较简单的网络应用,则不必使用 Netty,毕竟在能满足需求的基础上,越简单越好。
单次请求处理耗时较长的应用,这种情况下 NIO 没有优势,此时使用 BIO 的方式可能效果会更好。
Netty 支持的协议
Netty 框架本身已经对常用的协议进行了实现,包括:
应用层:HTTP,WebSocket,HTTP2,Redis,SMTP,DNS,MQTT,SSL,STARTTLS ,RTSP。
传输层:TCP,UDP,SCTP,UDT 等。
其他:Protobuf,gzip。
可以说,一般的应用使用 Netty 本身的支持就能满足大部分需求,剩下的关注自己的业务即可
Netty & MINA & Jetty
Netty 和 MINA 经常会放在一起比较,主要是因为两个框架有很多相似的地方,或者说它们本身就是一对兄弟 -- 都是基于 Java NIO 封装的一个网络框架。其实更深入的了解会发现,Netty 的作者Trustin Lee也是 MINA 的作者(当然已经不继续参与了),据说他是对 MINA 的代码不满意,才重新写了 Netty,所以看 Netty 的代码经常能看到 MINA 的影子,但就现在来说 Netty 的社区远比 MINA 要活跃,迭代频率也更高,大部分的特性也优于 MINA。
至于 Jetty 之所以会拿来比较,主要是因为和 Netty 名字类似,但其实这两者并没有很大的可比性,因为 Jetty 是一个轻量级的 servlet 容器,而 Netty 是一个基于 NIO 的异步网络编程框架,基于 Netty 可以实现自己的 servlet 容器或者其它网络应用。
相关项目
很多项目内部都使用 Netty 作为其网络处理模块,包括:
Netty 本身是一个优秀的框架,其源码的层次和结构也很清晰,值得一读;平常很多人说熟悉网络,但是大部分人也仅仅只是知道一些皮毛(也包括我自己)。其实,想要写一个健壮易用的网络框架并不容易,如果需要同时支持高并发,那更是难上加难,而 Netty 在这一点就做得很出色,不仅体现在其本身优秀的代码组织,更多的还是把一些已有的功能和思想进行合适的组装和适当的优化。
另外,结合当今另一个炙手可热的高性能服务器 Nginx 会发现,这两者的思想有很多相通之处,如都是基于事件机制,都分为主工作组与子工作组,都是在 PipeLine 上设置一系列的 Handler 进行数据处理,都有通过逻辑映射增强内存效率的设计等等,很有意思,感兴趣的小伙伴可以找寻相关资料进行延展阅读。
作者介绍
蔡昱星,飞书深诺首席架构师;主要专注于基于云原生的互联网架构设计与落地,当前重点关注企业系统架构领域,特别是如何更好的应对业务复杂度。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 1 条评论