

导读: 面对数据库实例和存储规模的不断增长,大促成本、调度效率等难题,2017 年阿里就开始小范围应用新型技术架构——“存储计算分离”,以更低成本支撑弹性大促。
2018 年,我们实现了全单元规模化部署存储计算分离。不过在此之前,各个业务都需要根据自身业务特性进行大量优化。数据库领域更是如此,而且要求更加苛刻,难度更大。 阿里巴巴存储技术事业部高级技术专家吕健 将详细解读在 2018 双 11 大促中,阿里如何打破存储与计算之间的技术壁垒,从而实现无需搬动数据即可灵活弹性扩容的技术突破。
一、2017 年我们做了什么?
记得早在 2017 年的时候,王坚博士就曾号召大家就关于“IDC As a Computer”是否能做到,进行过激烈的讨论。而要做到此,必须要实现存储计算分离,分离后由调度对计算和存储资源进行独立自由调度。而在实现存储计算分离的所有业务中,数据库是最难的。因为数据库对 I/O 的时延和稳定性有着极高的要求。但是从业界来看,存储计算分离又是一个未来的技术趋势,因为像 Google spanner 以及 Aurora 都已经实现了。
所以 2017 年,我们抱着坚定的信念,去实现数据库的存储计算分离。事实上,2017 年我们做到了,基于盘古和 AliDFS(ceph 分支) ,在张北单元存储计算分离承担 10%的交易量。2017 年是数据库实现存储计算分离的元年,为 2018 年大规模实现存储计算分离打下了坚实的基础。
二、2018 技术突破
如果说 2017 年是数据库实现存储计算分离的突破之年的话,那么 2018 年就是追求极致性能的一年,也是由试验走向大规模部署的一年,其技术的挑战可想而知。在 2017 年的基础上,2018 年的挑战更为巨大,需要让存储计算分离更加的高性能、普适、通用以及简单。
2018 年,为了使得在存储计算分离下数据库的 I/O 达到最高性能和吞吐,我们自研了 用户态集群文件系统 DADI DBFS 。我们通过将技术沉淀到 DADI DBFS 用户态集群文件上,赋能集团数据库交易全单元规模化存储计算分离。那么成为存储中台级产品,DBFS 又做了那些技术上的创新呢?
2.1 用户态技术
2.1.1 “ZERO” copy
我们直接通过用户态,旁路 kernel,实现 I/O 路径的“Zero”copy。避免了核内核外的 copy,使得吞吐和性能都有了非常大的提高。
过去使用 kernel 态时,会有两次数据 copy,一次由业务的用户态进程 copy 数据到核内,一次由核内 copy 到用户态网络转发进程。这两次 copy 会影响整体吞吐和时延。
切到纯用户态之后,我们使用 polling 模型进行 I/O request 请求的发送。另外对于 polling mode 下 CPU 的消耗,我们使用了 adaptive sleep 技术,使得空闲时,不会浪费 core 资源。
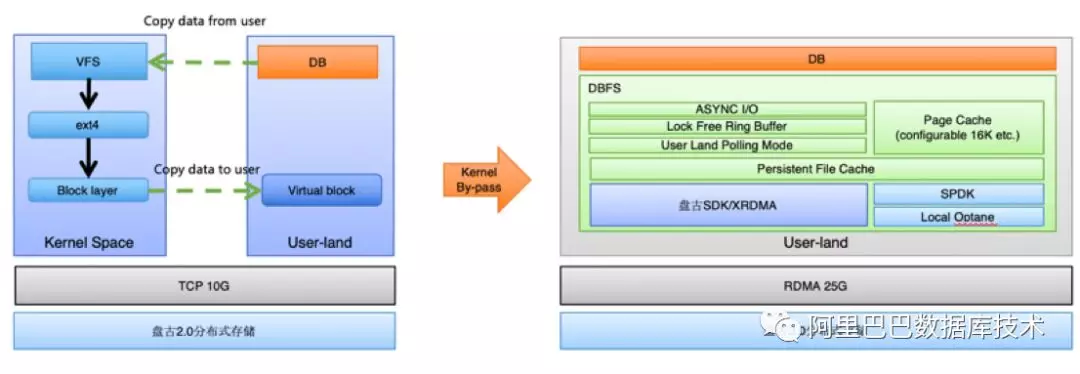
2.1.2 RDMA
另外,DBFS 结合 RDMA 技术与盘古存储直接进行数据交换,达到接近于本地 SSD 的时延和更高的吞吐,从而使得今年跨网络的极低时延 I/O 成为可能,为大规模存储计算分离打下了坚强的基础。今年集团参加大促的 RDMA 集群,可以说是在规模上为业界最大的一个集群。
2.2 Page cache
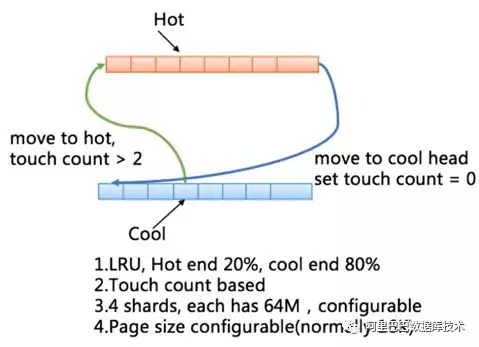
为了实现 buffer I/O 的能力,我们单独实现了 page cache。Page cahce 采用 touch count based LRU 算法实现。引入 touch count 的意义是为了更好的与数据库的 I/O 特性结合。因为数据库中时常会有大表扫描等行为,我们不希望这种使用频率低的数据页冲刷掉 LRU 的效率。我们会基于 touch count 将 page 在 hot 端和 cool 端进行移动。
Page cache 的页大小可配置,与数据库的页大小进行结合时,会发挥更好的 cache 效率。总体上 DBFS 的 page cache 具备以下的能力:
基于 touch count 进行 page 的冷热端迁移
冷热端比例可配置,目前为热冷比例为 2:8
page size 可配置,结合数据库页进行最优化配置
多 shard,提高并发;总体容量可配置
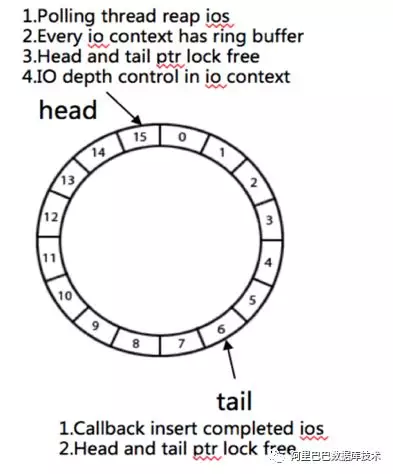
2.3 异步 I/O
为了提高数据库的 I/O 吞吐能力,大部分数据库都使用了异步 I/O。我们为了兼容上层数据库的 I/O 特性,实现了异步 I/O。异步 I/O 特性:
无锁队列实现
可配置的 I/O depth,能够使得针对数据库不同的 I/O 类型进行精确时延控制
polling adaptive,减少 CPU 消耗
2.4 原子写
为了保证数据库页写出的时候不出现 partial write,DBFS 实现了原子写功能。基于 DBFS 的 Innodb,可以安全的将 double write buffer 关掉,从而使得在存计分离下数据库带宽节省 100%。
另外,如 PostgreSQL 使用的是 buffer I/O,也避免了 PG 在 dirty page flush 时偶发性遇到的缺页问题。
2.5 Online Resize
为了避免扩容而带来的数据迁移,DBFS 结合底层盘古实现 volume 的在线 resize。DBFS 有自己的 bitmap allocator,用于实现底层存储空间的管理。我们对 bitmap allocator 进行了优化,在文件系统层级做到了 lock free 的 resize,使得上层业务可以在任何时候进行对业务无损的高效扩容,完全优于传统的 ext4 文件系统。
Online Resize 的支持,避免了存储空间的浪费,因为不用 reserve 如 20%的存储空间了,可以做到随扩随写。
以下为扩容时的 bitmap 变化过程:
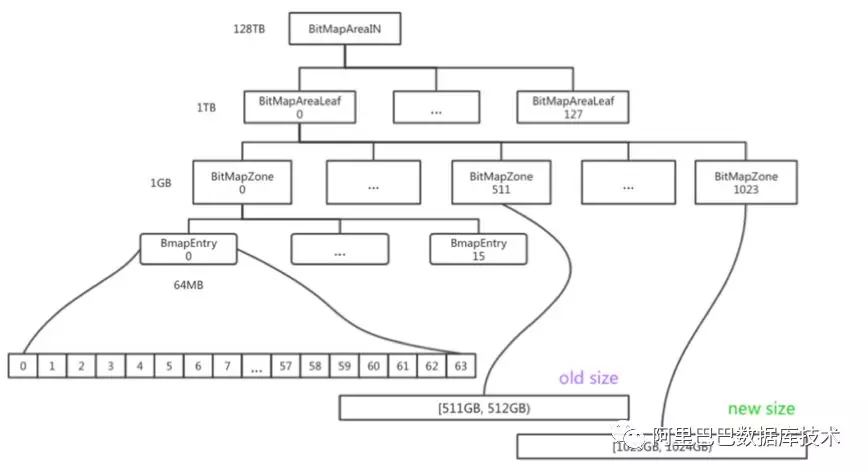
2.6 TCP 与 RDMA 互切
RDMA 在集团数据库大规模的引入使用也是一个非常大的风险点,DBFS 与盘古一起实现了 RDMA 与 TCP 互切的功能,并在全链路过程中进行了互换演练,使得 RDMA 的风险在可控的范围内,稳定性保障更加完善。
另外,DBFS,盘古以及网络团队,针对 RDMA 进行了非常多的容量水位压测,故障演练等工作,为业界最大规模 RDMA 上线做了非常充足的准备。
2.7 2018 年大促部署
在做到了技术上的突破和攻关后,DBFS 最终完成艰巨的任务通过大促全链路的考验以及双“十一”大考,再次验证了存储计算分离的可行性和整体技术趋势。
三、存储中台利器 DBFS
除了以上做为文件系统必须实现的功能以外,DBFS 还实现了诸多的特性,使得业务使用 DBFS 更加的通用化,更加易用性,更加稳定以及安全。
3.1 技术沉淀与赋能
我们将所有的技术创新和功能以产品的形式沉淀在 DBFS 中,使得 DBFS 能够赋能更多的业务实现以用户态的形式访问不同的底层存储介质,赋能更多数据库实现存储计算分离。
3.1.1 POSIX 兼容
目前为了支撑数据库业务,我们兼容了大多数常用的 POSIX 文件接口,以方便上层数据库业务的对接。另外也实现了 page cache,异步 I/O 以及原子写等,为数据库业务提供丰富的 I/O 能力。另外,我们也实现了 glibc 的接口,用于支持文件流的操作和处理。这两种接口的支持,大大简化了数据库接入的复杂度,增加了 DBFS 易用性,使得 DBFS 可以支撑更多的数据库业务。
posix 部分大家比较熟悉就不再列出,以下仅为部分 glibc 接口供参考:
// glibc interface
FILE fopen(constcharpath,constcharmode);FILE fdopen(int fildes,constcharmode);size_t fread(voidptr, size_t size, size_t nmemb, FILE stream);size_t fwrite(constvoidptr, size_t size, size_t nmemb, FILE *stream);
intfflush(FILE *stream);
intfclose(FILE *stream);
intfileno(FILE *stream);
intfeof(FILE *stream);
intferror(FILE *stream);
voidclearerr(FILE *stream);
intfseeko(FILE *stream, off_t offset,int whence);
intfseek(FILE *stream,long offset,int whence);
off_t ftello(FILE *stream);
longftell(FILE *stream);
voidrewind(FILE *stream);
3.1.2 Fuse 实现
另外,为了兼容 Linux 生态我们实现了 fuse,打通 VFS 的交互。Fuse 的引入使得用户在不考虑极致性能的情况下,可以不需要任何代码改动而接入 DBFS,大大提高产品的易用性。另外,也大大方便了传统的运维操作。
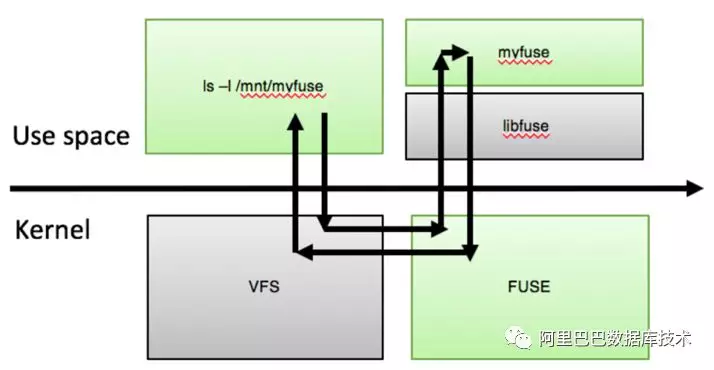
3.1.3 服务化能力
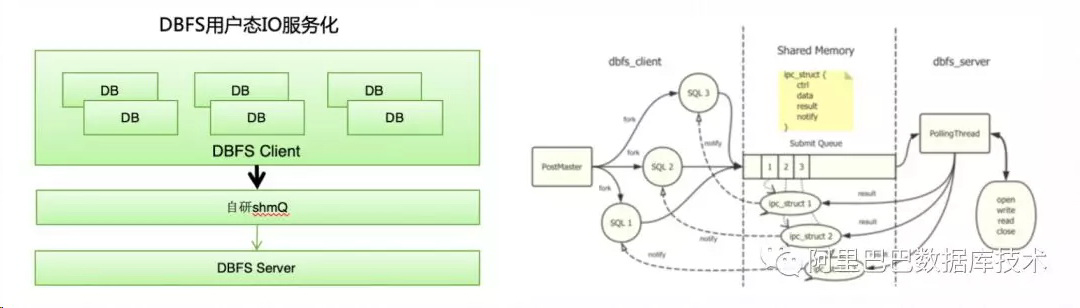
DBFS 自研了 shmQ 组件,基于内享内存的 IPC 通信,从而拉通了对于 PostgreSQL 基于进程架构和 MySQL 基于线程架构的支持,使得 DBFS 更加的通用化和安全,为以后在线升级提供坚实的基础。
shmQ 基于无锁实现,性能和吞吐表现优异,从目前测试来看,在 16K 等数据库大页下能控制在几个 us 以内的访问时延。服务化以及多进程架构的支持,目前性能与稳定性符合预期。
3.1.4 集群文件系统
集群功能是 DBFS 的又一大明显特性,赋能数据库基于 shared-disk 模式,实现计算资源的线性扩展,为业务节省存储成本。另外,shared-disk 的模式也为数据库提供了快速的弹性能力,也大大提高了主备快速切换的 SLA。集群文件系统提供一写多读以及多点写入的能力,为数据库 shared-disk 和 shared nothing 架构打下坚实的基础。与传统的 OCFS 相比,我们在用户态实现,性能更好,更加自主可控。OCFS 严重依赖于 Linux 的 VFS,如没有独立的 page cache 等。
DBFS 支持一写多读模式时,提供多种角色可选(M/S),可以存在一个 M 节点多个 S 节点使用共享数据,M 节点和 S 节点共同访问盘古数据。上层数据库对 M/S 节点进行了限制,M 节点的数据访问是可读可写的,S 节点的数据访问是只读的。如果主库发生故障,就会进行切换。主从切换步骤:
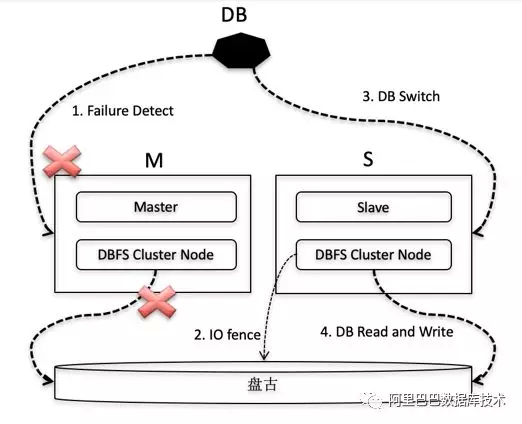
业务监控指标探测发现 M 节点出现无法访问或者异常的时候,进行决策,是否要进行切换。
如果发生切换,由管控平台发起切换命令,切换命令完成,代表 DBFS 和上层数据库都已经完成角色切换。
在 DBFS 切换的过程中,最主要的动作就是 IO fence,禁止掉原本的 M 节点 IO 能力,防止双写情况。
DBFS 在多点写入时,对所有节点进行全局的 metalock 控制,blockgroup allocation 优化等。另外也会涉及到基于 disk 的 quorum 算法等,内容比较复杂,暂不做详细陈述。
3.2 软硬件结合
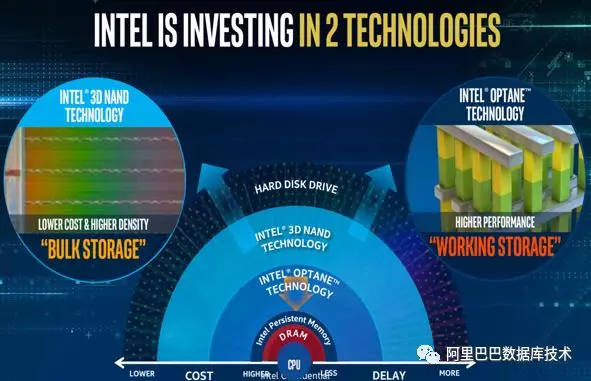
随着新存储介质的出现,数据库势必需要借其发挥更好的性能或者更低成本优化,并且做到对底层存储介质的自主可控。
从 Intel 对存储介质的规划来看,从性能到容量,会形成 AEP,Optane 和 SSD 这三种产品,而在向大容量方向上,又会有 QLC 的出现。所以综合性能和成本来看,我们觉得 Optane 是一个比较不错的 cache 产品。我们选择它作为 DBFS 机头持久化 filecache 的实现。
3.2.1 持久化 file cache
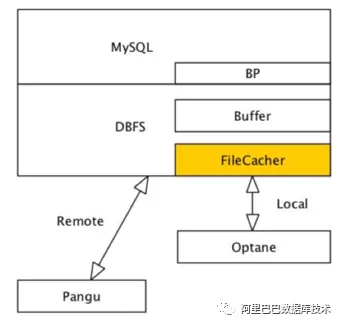
DBFS 实现了基于 Optane 的 local 持久化 cache 功能,使得在存计分离下更近一步提升数据库的读写性能。File cache 为了达到生产可用性,做了非常多的工作,如:
稳定可靠的故障处理
支持动态 enable 和 disable
支持负载均衡
支持性能指标采集和展示
支持数据正确性 scrub
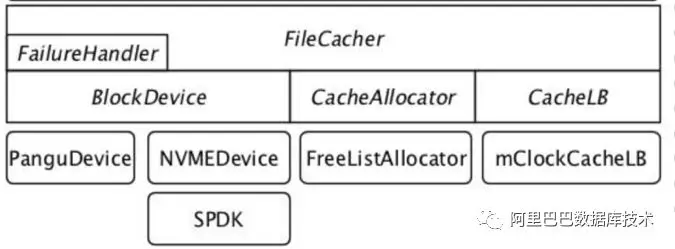
这些功能的支撑,为线上稳定性打下坚实的基础。其中,针对 Optane 的 I/O 为 SPDK 的纯用户态技术,DBFS 结合 Fusion Engine 的 vhost 实现。File Cache 的页大小可以根据上层数据库的 block 大小进行最佳配置,以达到最好的效果。
以下为 file cache 的架构图:
以下是测试所得读写性能收益数据:
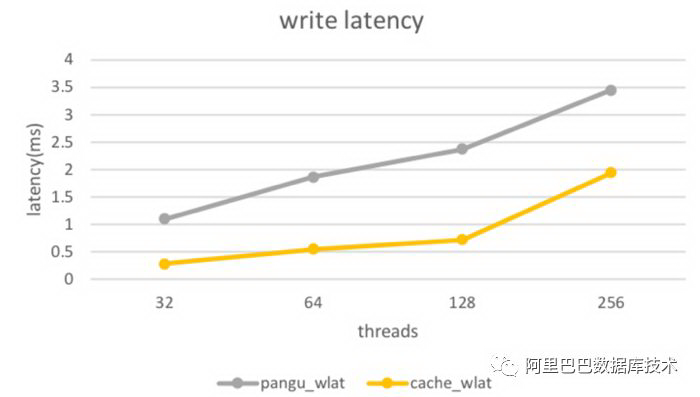
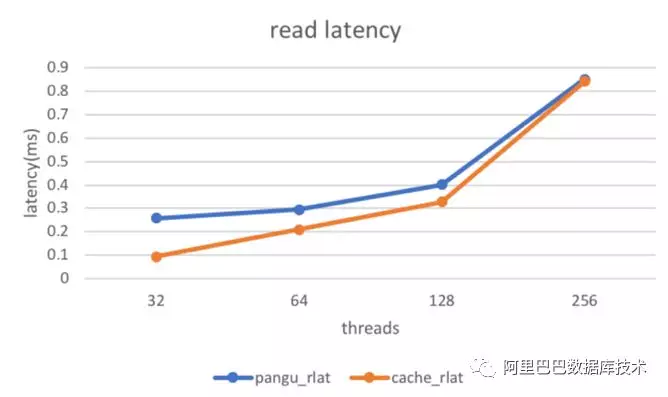
其中带有“cache”的为基于 filecache 所得。整体表现随着命中率提高,读时延开始下降。另外,我们针对 file cache,进行了诸多性能指标的监控。
3.2.2 Open Channel SSD
X-Engine 和 DBFS 以及 Fusion Engine 团队展开合作,基于 object SSD 进一步打造存储自主可控的系统。在降低 SSD 磨损,提高 SSD 吞吐,降低读写相互干扰等领域,进行了深度探索与实践,都取得了非常不错的效果。目前已经结合 X-Engine 的分层存储策略,打通了读写路径,我们期待下一步更加深入的智能化存储研发。
四、总结与展望
2018 年 DBFS 已经大规模支持了 X-DB 以存储计算分离形态支持“11.11”大促;与此同时也赋能 ADS 实现一写多读能力以及 Tair 等。
在支持业务的同时,DBFS 本身已经拉通了 PG 进程与 MySQL 线程架构的支持,打通了 VFS 接口,做到了与 Linux 生态的兼容,成为真正意义上的存储中台级产品——集群用户态文件系统。未来结合更多的软硬件结合、分层存储、NVMeoF 等技术赋能更多的数据库,实现其更大的价值。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论