

本文讨论 K8S 1.3 的一些新功能,以及正在进行中的功能。读者应该对 kubernetes 的基本结构已经有所了解。
支持更多类型的应用
Init container
Init container 是 1.3 中的 alpha feature,目的是支持一类需要在启动 Pod“普通容器”前,先进行 Pod 初始化的应用。执行该初始化任务的容器被成为“初始化容器”(init container)。例如,在启动应用之前,初始化数据库,或等待数据库启动等。下图是一个包含 init container 的 Pod:
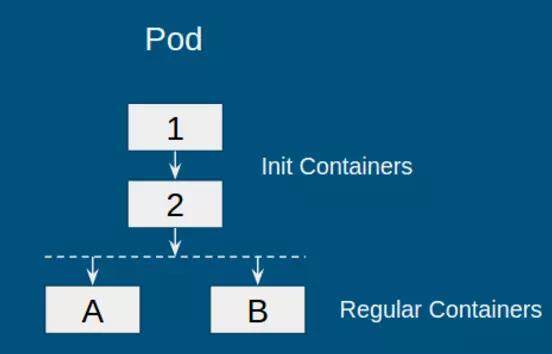
对于此类 Pod,kubernetes 的运行策略如下:
初始化容器按顺序依次执行,即图中容器 1->2
若其中某一个初始化容器运行失败,则整个 Pod 失败
当所有初始化容器运行成功,启动普通容器,即图中容器 A 和 B
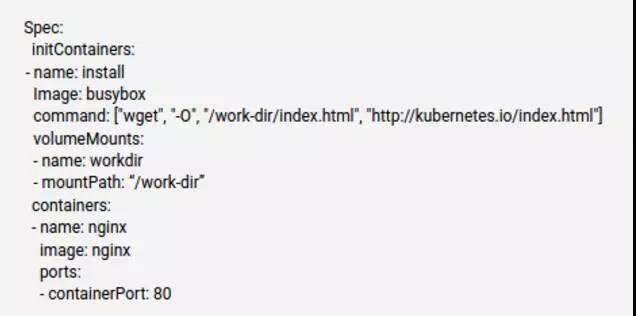
在 alpha 版本中使用 init container 需要用 annotation,下图是来自 k8s 的一个例子(略有裁剪):

可以看到,我们在启动 nginx 普通容器之前,先用 init container 来获取 index.html,之后访问 nginx 就会直接返回该文件。当 init container 功能稳定后,k8s 会直接在 pod.spec 内加上 init Containers 字段,如下所示:
init container 看起来是一个小功能,但是在实现上还是需要考虑不少问题,比如几个比较重要的点:
资源问题:当调度存在 init container 的 Pod 时,应该怎样计算所需要的资源?两个极端情况:如果对 init container 和 regular container 所需要的资源求和,那么当 init container 成功初始化 Pod 之后,就不会再使用所请求的资源,而系统认为在使用,会造成浪费;反之,不计算 init container 的资源又会导致系统不稳定(init container 所使用的资源未被算入调度资源内)。目前的方法是取折中:由于初始化容器和普通容器不会同时运行,因此 Pod 的资源请求是两者中的最大值。对于初始化容器,由于他们是依次运行,因此选择其中的最大值;对于普通容器,由于是同时运行,选择容器资源的和。
Pod Status: 目前,Pod 有 Pending, Running, Terminating 等状态。对于有初始化容器的 Pod,如果仍然使用 Pending 状态,则很难区分 Pod 当前在运行初始化容器还是普通容器。因此,理想情况下,我们需要增加一个类似于 Initializing 的状态。在 alpha 版本中暂时还未添加。
健康检查及可用性检查:有了 init container 之后,我们该如何检查容器的健康状态?alpha 版本将两个检查都关闭了,但 init container 是会在 node 上实实在在运行的容器,理论上是需要进行检查的。对于可用性检查,关闭掉是一个可行的办法,因为 init container 的可用性其实就是当它运行结束的时候。对于健康检查,node 需要知道某个 Pod 是否处在初始化阶段;如果处在初始化阶段,那么 node 就可以对 init container 进行健康检查。因此,kubernetes 很有可能在添加类似 Initializing 的 Pod 状态之后,开启 init container 的健康检查。
围绕 init container 的问题还有很多,比如 QoS,Pod 的更新等等,其中不少都是有待解决的问题,这里就不一一展开了。
PetSet
PetSet 应该算是社区期待已久的功能,其目的是支持有状态和集群化的应用,目前也是 alpha 阶段。PetSet 的应用场景很多,包括类似 zookeeper、etcd 之类的 quorum leader election 应用,类似 Cassandra 的 Decentralized quorum 等。PetSet 中,每个 Pod 都有唯一的身份,分别包括:名字,网络和存储;并由新的组件 PetSet Controller 负责创建和维护。下面依次看一看 kubernetes 是如何维护 Pod 的唯一身份。
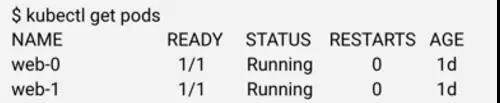
名字比较容易理解,当我们创建一个 RC 之后,kubernetes 会创建指定副本数量的 Pod,当使用 kubectl 获取 Pod 信息时,我们会得到如下信息:

其中,5 个字符的后缀为 kubernetes 自动生成。当 Pod 重启,我们会得到不同的名字。对于 PetSet 来讲,Pod 重启必须保证名字不变。因此,PetSet 控制器会维护一个 identityMap,每一个 PetSet 中的每个 Pod 都会有一个唯一名字,当 Pod 重启,PetSet 控制器可以感知到是哪个 Pod,然后通知 API server 创建新的同名 Pod。目前的感知方法很简单,PetSet 控制器维护的 identityMap 将 Pod 从 0 开始进行编号,然后同步的过程就像报数一样,哪个编号不在就重启哪个编号。
此外,该编号还有另外一个作用,PetSet 控制器通过编号来确保 Pod 启动顺序,只有 0 号 Pod 启动之后,才能启动 1 号 Pod。
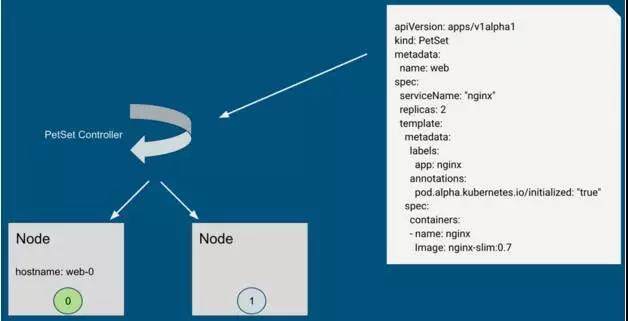
网络身份的维护主要通过稳定的 hostname 和 domain name 来维护,他们通过 PetSet 的配置文件指定。例如,下图是一个 PetSet 的 Yaml 文件(有裁剪),其中 metadata.name 指定了 Pod 的 hostname 前缀(后缀即前面提到的从 0 开始的索引),spec.ServiceName 指定了 domain name。
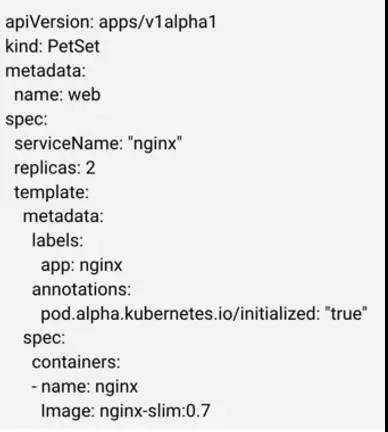
通过上面的 Yaml 文件创建出来两个 Pod:web-0 和 web-1。其完整的域名为 web-0.nginx.default.svc.cluster.local,其中 web-0 为 hostname,nginx 为 Yaml 中指定的 domain name,剩下的部分与普通 service 无异。当创建请求被下发到节点上时,kubelet 会通过 container runtime 设置 UTS namespace,如下图所示(省略了部分组件如 apiserver)。
此时,hostname 已经在容器层面设置完成,剩下还需要为 hostname 增加集群层面的解析,以及添加 domain name 的解析,这部分工作理所当然就交给了 kube dns。了解 Kubernetes 的读者应该知道,要添加解析,我们需要创建 service;同理,这里也需要为 PetSet 创建 service。不同的是,普通的 service 默认后端的 Pod 是可替换的,并采用诸如 roundrobin,client ip 的方式选择后端的 Pod,这里,由于每个 Pod 都是一个 Pet,我们需要定位每一个 Pod,因此,我们创建的 service 必须要能满足这个要求。在 PetSet 中,利用了 kubernetes headless service。Headless service 不会分配 cluster IP 来 load balance 后端的 Pod,但会在集群 DNS 服务器中添加记录:创建者需要自己去利用这些记录。下图是我们需要创建的 headless service,注意其中的 clusterIP 被设置为 None,表明这是一个 headless service。

Kube dns 进行一番处理之后,会生成如下的记录:

可以看到,访问 web-0.nginx.default.svc.cluster.local 会返回 pod IP,访问 nginx.default.svc.cluster.local 会返回所有 Pet 中的 pods IP。一个常见的方式是通过访问 domain 的方式来获取所有的 peers,然后依次和单独的 Pod 通信。
存储身份这块采用的是 PV/PVC 实现,当我们创建 PetSet 时,需要指定分配给 Pet 的数据卷,如下图:
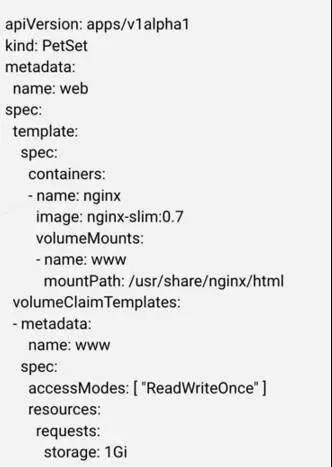
这里,volumeClaimTemplates 指定每个 Pet 需要的存储资源。注意目前所有 Pet 都得到相同大小和类型的数据卷。当 PetSet 控制器拿到请求时,会为每一个 Pet 创建 PVC,然后将每个 Pet 和对应的 PVC 联系起来:

之后的 PetSet 只需要确保每个 Pet 都与相对应的 PVC 绑定在一起即可,其他工作,类似于创建数据卷,挂载等工作,都交给其他组件。
通过名字,网络,存储,PetSet 能够 cover 大多数的案例。但是,目前还存在很多需要完善的地方,感兴趣的读者可以参考。
Scheduled Job
Scheduled Job 本质上是集群 cron,类似 mesos chronos,采用标准的 cron 语法。遗憾的是在 1.3 中还并未达到发布的标准。Scheduled Job 其实在很早就提出来过,但当时 kubernetes 的重点还在 API 层面,并且即使有很大需求,也计划在 Job(1.2GA)之后实现。当 scheduled job 在之后的版本发布之后,用户可以用一条简单的命令在 kubernetes 上运行 Job,例如:kubectl run cleanup -image=cleanup --runAt=“0 1 0 0 *” – /scripts/cleanup.sh 一些关于 scheduled job 的更新可以参考。
Disruption Budget
Disruption Budget 的提出是为了向 Pod 提供一个反馈机制,确保应用不会被集群自身的变动而受影响。例如,当集群需要进行重调度时,应用可以通过 Disruption Budget 来说明 Pod 能不能被迁移。Disruption Budget 只负责集群自身发起的变动,不负责突发事件比如节点突然掉线,或者应用本身的问题比如不断重启的变动。Disruption Budget 同样没有在 1.3 中发布。
与 kubernetes 大多数资源类似,我们需要通过 Yaml 文件创建一个 PodDisruptionBudget 资源,例如,下图所示的 Disruption Budget 选中了所有带有 app:nginx 标签的 pod,并且要求至少有 3 个 Pod 在同时运行。
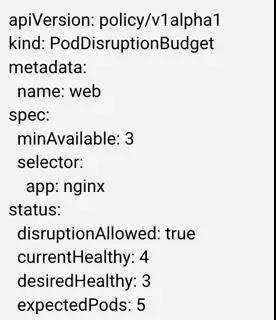
Controller manager 内有一个新的组件 Disruption Budget Controller,来负责维护所有 Budget 的状态,例如上图中的 status 表明当前共有 4 个健康的 Pod(currentHealthy),应用要求至少有 3 个(desiredHealthy),总共有 5 个 Pod(expectedPods)。为了维护这个状态,Disruption Budget Controller 会遍历所有的 Budget 和所有的 Pod。有了 Budget 的状态,需要改变 Pod 状态的组件都要先查询之。若其操作导致最小可用数低于应用要求,则操作会被拒绝。
Disruption Budget 与 QoS 联系很紧密。例如,如果一个 QoS level 很低的应用有着非常严格的 Disruption Budget,系统应该如何处理?目前,kubernetes 还没有严格的处理这个问题,一个可行的办法是对 Disruption Budget 做优先级处理,确保高优先级的应用拥有高优先级的 Disruption Budget;此外,Disruption Budget 可以加入 Quota 系统,高优先级的应用可以获得更多 Disruption Budget Quota。关于 Disruption Budget 的讨论可以参考。
支持更好的集群管理
Cascading Deletion
在 kubernetes 1.2 之前,删除控制单元都不会删除底层的资源。例如,通过 API 删除 RC 之后,其管理的 Pod 不会被删除(使用 kubectl 可以删除,但 kubectl 里面有 reaper 逻辑,会依次删除底层的所有 Pod,本质上是客户端逻辑)。另外一个例子,当删除下图中的 Deployment 时,ReplicaSet 不会被自动删除,当然,Pod 也不会被回收。
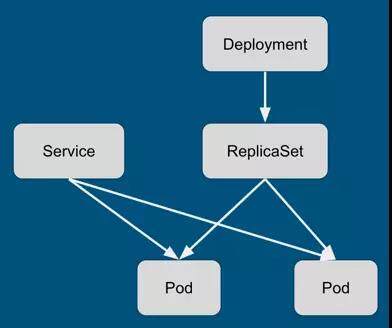
Cascading deletion 指的就是在删除控制单元后,将被管理单元也同时回收。但是,kubernetes 1.3 中的 cascading deletion 并不是简单地讲 kubectl 中的逻辑复制到 server 端,而是做了更高层次的工作:垃圾回收。简单来讲,garbagecollector controller 维护了几乎所有集群资源的列表,并接收资源修改的事件。controller 根据事件类型更新资源关系图,并将受影响的资源放入 Dirty Queue 或者 Orphan Queue 中。具体实现可以参考官方文档和 garbage collector controller 实现。
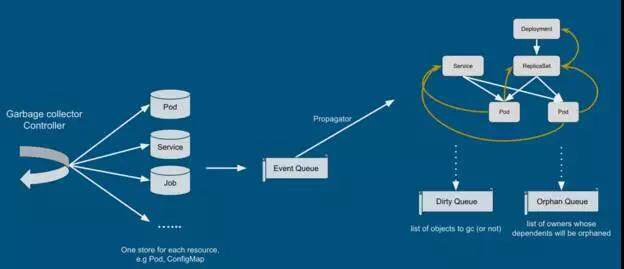
Node eviction
Node/kubelet eviction 指的是在节点将要超负荷之前,提前将 Pod 剔除出去的过程,主要是为了内存和磁盘资源。在 kubernetes 1.3 之前,kubelet 不会“提前”感知节点的负荷,只会对已知的问题进行处理。当内存吃紧时,kubernetes 依靠内核 OOM killer;磁盘方面则定期对 image 和 container 进行垃圾回收。但是,这种方式有局限性,OOM killer 本身需要消耗一定资源,并且时间上有不确定性;回收容器和镜像不能处理容器写日志的问题:如果应用不断写日志,则会消耗掉所有磁盘,但不会被 kubelet 处理。
Node eviction 通过配置 kubelet 解决了以上问题。当启动 kubelet 时,我们通过指定 memory.available, nodefs.available, nodefs.inodesFree 等参数来确保节点稳定工作。例如,memory.available < 200Mi 表示当内存少于 200Mi 时,kubelet 需要开始移除 Pod(可以配置为立即移除或者延迟移除,即 hard vs soft)。kubernetes 1.3 中,node eviction 的特性是 opt-in,默认关闭,可以通过配置 kubelet 打开相关功能。
尽管 node eviction 是 kubelet 层面采取的措施,我们也必须考虑与整个集群的交互关系。其中最重要的一点是如何将这个问题反馈给 scheduler,不然被剔除的 Pod 很有可能会被重新调度回来。为此,kubernetes 添加了新的 node condition:MemoryPressure, DiskPressure。当节点的状态包含其中任意一种时,调度器会避免往该节点调度新的 Pod。这里还有另外一个问题,即如果节点的资源使用刚好在阈值附近,那么节点的状态可能会在 Pressure 和 Not Pressure 之间抖动。防抖动的方法有很多种,例如平滑滤波,即将历史数据也考虑在内,加权求值。k8s 目前采用较为简单的方法:即如果节点处于 Pressure 状态,为了转变成 Not Pressure 状态,资源使用情况必须低于阈值一段时间(默认 5 分钟)。这种方法会导致 false alarm,比如,若一个应用每隔一段时间请求一块内存,之后很快释放掉,那么可能会导致节点一直处于 Pressure 状态。但大多数情况下,该方法能处理抖动的情况。
说到 eviction pod,那么另外一个不得不考虑的问题就是找一个倒霉的 Pod。这里 kubernetes 定义了不少规则,总结下来主要是两点:1. 根据 QoS 来判断,QoS 低的应用先考虑;2. 根据使用量判断,使用量与总请求量比例大的 Pod 优先考虑。具体细节可以参考。
Network Policy
Network policy 的目的是提供 Pod 之间的隔离,用户可以定义任意 Pod 之间的通信规则,粒度为端口。例如,下图的规则可以解释成:拥有标签“db”的 Pod,只能被拥有标签“frontend”的 Pod 访问,且只能访问 tcp 端口 6379。
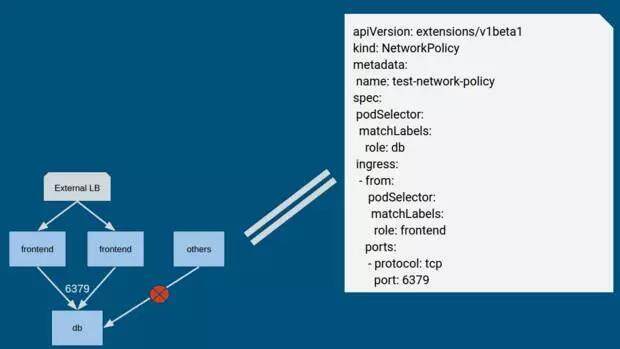
Network policy 目前处于 beta 版本,并且只是 API。也就是说,kubernetes 不会真正实现网络隔离:如果我们将上述 Yaml 文件提交到 kubernetes,并不会有任何反馈,kubernetes 只是保存了这个 Policy 内容。真正实现 policy 功能需要其他组件,比如 calico 实现了一个 controller,会读取用户创建的 Policy 来实现隔离,可以参考。关于 Network Policy 的细节,可以参考。
Federation
Federation cluster 翻译成中文叫“联合集群”,即将多个 kubernetes 集群联合成一个整体,并且不改变原始 kubernetes 集群的工作方式。根据 kubernetes 官方设计文档,federation 的设计目的主要是满足服务高可用,混合云等需求。在 1.3 版本之前,kubernetes 实现了 federation-lite,即一个集群中的机器可以来自于相同 cloud 的不同 zone;1.3 版本中,federation-full 的支持已经是 beta 版本,即每个集群来自不同的 cloud(或相同)。
Federation 的核心组件主要是 federation-apiserver 和 federation-controller-manager,以 Pod 形式运行在其中一个集群中。如下图所示,外部请求直接与 Federation Control Panel 通信,由 Federation 分析请求并发送至 kubernetes 集群。
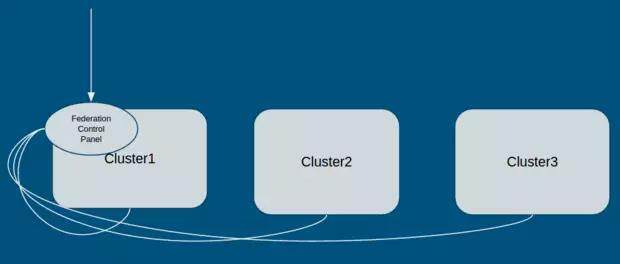
在应用层面,Federation 目前支持 federated services,即一个应用跨多个集群的访问,具体细节可以参考。
结束语
kubernetes 1.3 带来了非常多的特性,这里只 cover 了其中一部分。在安全方面,kubernetes 已经支持 RBAC,实现更好的权限控制;PodSecurityContext 也进入 beta 版本,支持运行部分需要特权的 Pod 等。在性能方面,由于 protocol buffere serialization 的引入,是性能提高了几倍,并且正在酝酿中的 etcd3 会将性能提升更进一步。相信之后的版本会带给我们更多的惊喜。
本文转载自才云 Caicloud 公众号。
原文链接:https://mp.weixin.qq.com/s/uDbsq7-7_Ps1FudYGxdOoQ

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论