

概览
我们知道,前端 Web 网页编程采用的是 HTML + CSS + JS 这样的组合,其中 HTML 是用来描页面的结构,CSS 用来描述页面的样子,JS 通常用来处理页面逻辑和用户的交互。类似地,在小程序中也有同样的角色,一个小程序工程主要包括如下几类文件:
.json后缀的 JSON 配置文件.wxml后缀的 WXML 模板文件.wxss后缀的 WXSS 样式文件.js后缀的 JavaScript 脚本逻辑文件
例如小程序源码工程结构如下:
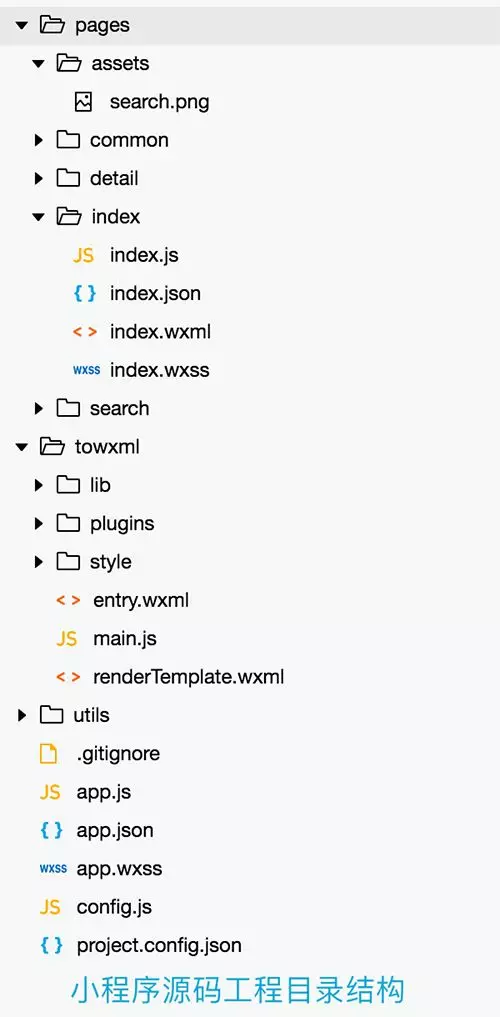
然而,根据上一篇文章介绍,对“知识小集”小程序解包后得到如下文件:
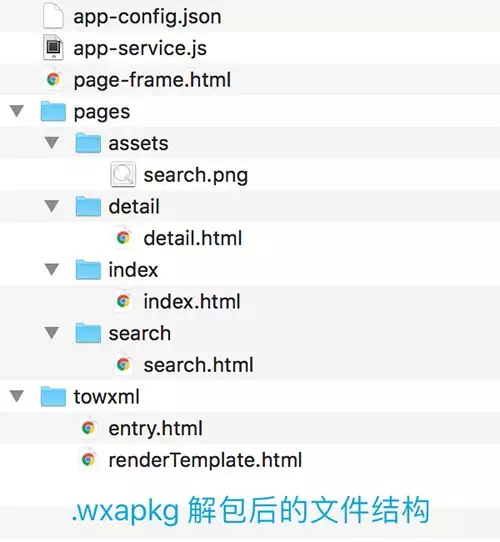
主要包括 app-config.json, app-service.js,page-frame.html, *.html, 资源文件 等,但这些文件已经被“编译混淆”并重新整合压缩,微信开发者工具并不能识别它们,无法直接对它们进行调试/编译运行。
所以,我们先尝试分析从.wxapkg 提取出来的各个文件内容的结构及其用途,然后介绍如何用脚本工具把它们一键还原为“编译”前的源码,并在微信开发者工具中跑起来。
文件分析
本节主要以 “知识小集”小程序的 .wxapkg 解包后的源码文件为例,进行分析。你也可以跳过本节的分析,直接看下一节介绍用脚本“反编译”还原源码。
app-config.json
小程序工程主要包括工具配置 project.config.json,全局配置 app.json 以及页面配置 page.json 三类 JSON 配置文件。其中:
project.config.json主要用于对开发者工具进行个性化配置以及包括小程序项目工程的一些基础配置,所以它不会被“编译”到 .wxapkg 包中;app.json是对当前小程序的全局配置,包括了小程序的所有页面路径、界面表现、网络超时时间、底部 tab 等;page.json用于对每一个页面的窗口表现进行配置,页面中配置项会覆盖 app.json 的 window 中相同的配置项。
因此“编译”后的文件 app-config.json 其实就是 app.json 和各个页面的配置文件的汇总,它的内容大致如下:
{ "page": { // 各页面配置 "pages/index/index.html": { // 某一页面地址 "window": { // 某一页面具体配置 "navigationBarTitleText": "知识小集", "enablePullDownRefresh": true } }, // 此处省略... }, "entryPagePath": "pages/index/index.html", // 小程序入口地址 "pages": ["pages/index/index", "pages/detail/detail", "pages/search/search"], // 页面列表 "global": { // 全局页面配置 "window": { "navigationBarTextStyle": "black", "navigationBarTitleText": "知识小集", "navigationBarBackgroundColor": "#F8F8F8", "backgroundColor": "#F8F8F8" } }}
通过与原工程 app.json 和各页面配置 page.json 内容的对比,我们可以得出 app-config.json 汇总文件的简单整合规律,很容易把它拆分成“编译”前对应的各 json 文件。
app-service.js
在小程序项目中 JS 文件负责交互逻辑,主要包括 app.js,每个页面的 page.js,开发者自定义的 JS 文件和引入的第三方 JS 文件,在“编译”后所有这些 JS 文件都会被汇总到app-service.js 文件中,它的结构如下:
// 一些全局变量的声明var __wxAppData = {};var __wxRoute;var __wxRouteBegin;var __wxAppCode__ = {};var global = {};var __wxAppCurrentFile__;var Component = Component || function(){};var definePlugin = definePlugin || function(){};var requirePlugin = requirePlugin || function(){};var Behavior = Behavior || function(){};
// 小程序编译基础库版本/*v0.6vv_20180125_fbi*/global.__wcc_version__='v0.6vv_20180125_fbi';global.__wcc_version_info__={"customComponents":true,"fixZeroRpx":true,"propValueDeepCopy":false};
// 工程中第三方或者自定义的一些 JS 源码define("utils/util.js", function(require, module, exports, window,document,frames,self,location,navigator,localStorage,history,Caches,screen,alert,confirm,prompt,XMLHttpRequest,WebSocket,Reporter,webkit,WeixinJSCore) { "use strict"; // ... 具体源码内容});
// ...
// app.js 源码定义define("app.js", function(...) { "use strict"; // ... app.js 源码内容});require("app.js");
// 每个页面对应的 JS 源码定义__wxRoute = 'pages/index/index'; // 页面路由地址__wxRouteBegin = true;define("pages/index/index.js", function(...){ "use strict"; // ... page.js 源码内容});require("pages/index/index.js");
在这个文件中,原有小程序工程中的每个 JS 文件都被 define 方法定义声明,定义中包含 JS 文件的路径和内容,如下:
define("path/to/xxx.js", function(...){ "use strict"; // ... xxx.js 源码内容});```
因此,我们同样很容易提取这些 JS 文件源码,并恢复至相应的路径位置中。当然,这些 JS 文件中的内容经过混淆压缩,我们可以使用 `Uglify JS` 这样的工具进行美化,但仍很难还原一些原始变量名,不过基本不影响正常阅读和使用。
### page-frame.html
在小程序中使用 `WXML` 文件描述页面的结构,`WXSS` 文件描述页面的样式。工程中有一个 app.wxss 文件用于定义一些全局的样式,会自动被 import到各个页面中;另外每个页面也都分别包含 page.wxml 和 page.wxss 用于描述其页面的结构和样式;同时,我们也会自定义一些公共的 xxxCommon.wxss 样式文件和公共的 xxxTemplate.wxml 模板文件供一些页面复用,一般在各自页面的 page.wxss 和 page.wxml 中去 import。
当“编译”小程序后,所有的 .wxml 文件和 app.wxss 及公共 xxxCommon.wxss 样式文件的将被整合到 page-frame.html 文件中,而每个页面的 page.wxss 样式文件,将分别单独在各自的路径下生成一个 page.html 文件。文件的内容结构如下:
```<!DOCTYPE html><html lang="zh-CN"> <head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0" /> <meta http-equiv="Content-Security-Policy" content="script-src 'self' 'unsafe-inline'"> <link rel="icon" href="data:image/ico;base64,aWNv"> <script> // 一些全局变量的声明 var __pageFrameStartTime__ = Date.now(); var __webviewId__; var __wxAppCode__ = {}; var __WXML_GLOBAL__ = { entrys: {}, defines: {}, modules: {}, ops: [], wxs_nf_init: undefined, total_ops: 0 }; // 小程序编译基础库版本 /*v0.6vv_20180125_fbi*/ window.__wcc_version__ = 'v0.6vv_20180125_fbi'; window.__wcc_version_info__ = { "customComponents": true, "fixZeroRpx": true, "propValueDeepCopy": false }; var $gwxc var $gaic = {} $gwx = function(path, global) { // $gwx 方法定义(最核心) } var BASE_DEVICE_WIDTH = 750; var isIOS = navigator.userAgent.match("iPhone"); var deviceWidth = window.screen.width || 375; var deviceDPR = window.devicePixelRatio || 2; function checkDeviceWidth() { // checkDeviceWidth 方法定义 } checkDeviceWidth() var eps = 1e-4; function transformRPX(number, newDeviceWidth) { // transformRPX 方法定义 } var setCssToHead = function(file, _xcInvalid) { // setCssToHead 方法定义 } setCssToHead([])(); // 先清空 Head 中的 CSS setCssToHead([...]); // 设置 app.wxss 的内容到 Head 中,其中 ... 为小程序工程中 app.wxss 的内容 var __pageFrameEndTime__ = Date.now() </script> </head> <body> <div></div> </body></html>```
相比其他文件,page-frame.html 比较复杂,微信把 .wxml 和部分 .wxss 直接“编译”并混淆成 JS 代码放入上述文件中,然后通过调用这些 JS 代码来构造 Virtual-Dom,进而渲染页面。其中最核心的是 \$gwx 和 setCssToHead 这两个方法。
* `$gwx` 用于通过 JS 代码生成所有 .wxml 文件,其中每个 .wxml 文件的内容结构都在 $gwx 方法中被定义好并混淆了,我们只要传给它页面的 .wxml 路径参数,即可获取到每个 .wxml 的内容,再简单加工一下即可还原成“编译”前的内容。
在 $gwx 中有一个 x 数组用于存储当前小程序都有哪些 .wxml 文件,例如,“知识小集”小程序的 x 值如下:
```var x = ['./pages/detail/detail.wxml', '/towxml/entry.wxml', './pages/index/index.wxml', './pages/search/search.wxml', './towxml/entry.wxml', '/towxml/renderTemplate.wxml', './towxml/renderTemplate.wxml'];```
此时我们可以在 Chrome 中打开 page-frame.html 文件,然后在 Console 中输入如下命令,即可得到 index.wxml 的内容(输出一个 JS对象,通过遍历这个对象即可还原出 .wxml 的内容)
```$gwx("./pages/index/index.wxml")```
* `setCssToHead` 方法用于根据几段被拆分的样式字符串数组生成 .wxss 代码并设置到 HTML 的 Head 中,同时,它还将所有被 import 引用的 .wxss 文件(公共 xxxCommon.wxss样式文件)所对应的样式数组内嵌在该方法中的 \_C 变量中,并标记哪些文件引用了 \_C 中数据。另外在 page-freme.html 文件的末尾,调用了该方法生成全局 app.wxss 的内容设置到 Head 中。
因此,我们可以在每个调用 setCssToHead 方法的地方提取相应 .wxss 的内容并还原。对于 page-freme.html 文件中
\$gwx 和 setCssToHead 这两个方法更详细的分析,可以参考这篇文章 `https://bbs.pediy.com/thread-225289.htm` 。
此外,checkDeviceWidth 方法顾明思议,用于检测屏幕的宽度,其检测结果将用于 transformRPX 方法中将 rpx 单位转换为 px 像素。
>`rpx` 的全称是 `responsive pixel`,它是小程序自己定义的一个尺寸单位,可以根据当前设备屏幕宽度进行自适应。小程序中规定,所有的设备屏幕宽度都为 `750rpx`,根据设备屏幕实际宽度的不同,`1rpx`所代表的实际像素值也不一样。
### *.html
上面提到,每个页面的 page.wxss 样式文件,“编译”后将分别在各自的所在路径下生成一个 `page.html` 文件,结构如下:
```<style></style><page></page><script> var __setCssStartTime__ = Date.now(); setCssToHead([...])() // 设置 search.wxss 的内容 var __setCssEndTime__ = Date.now(); document.dispatchEvent(new CustomEvent("generateFuncReady", { detail: { generateFunc: $gwx('./pages/search/search.wxml') } }))</script>```
在该文件中通过调用 setCssToHead 方法将 `.wxss` 样式内容设置到 Head 中,所以同样地,我们可以根据 setCssToHead 的调用参数提取每个页面的 `page.wxss`。
### 资源文件
小程序工程中的图片、音频等资源文件在“编译”后将直接被拷贝到 `.wxapkg`包中,其原始的路径也保留不变,因此我们可以直接使用。
## “反编译”
在上一节,我们完成了 .wxapkg 包几乎所有文件内容的简要分析。现在我们介绍一下如何通过 `node.js` 脚本帮我们还原出小程序的源码。
在这里需要再次感谢 wxappUnpacker 作者提供的还原工具,让我们可以“站在巨人的肩膀上”轻松地去完成“反编译”。它的使用如下:
* `node wuConfig.js ` `<path/to/app-config.json>` : 将 app-config.json 中的内容拆分成各个页面所对应的 page.json 和 app.json;* `node wuJs.js ` `<path/to/app-service.js>` : 将 app-service.js 拆分成一系列原先独立的 JS 文件,并使用 Uglify-ES美化工具尽可能将代码还原为“编译”前的内容;* `node wuWxml.js [-m] ` `<path/to/page-frame.html>` : 从 page-frame.html 中提取并还原各页面的 .wxml 和 app.wxss 及公共 .wxss 样式文件;* `node wuWxss.js ` `<path/to/unpack_dir>` : 该命令参数为 .wxapkg 解包后目录,它将分析并从各个 page.html 中提取还原各页面的 page.wxss 样式文件;
同时,作者还提供了一键解包并还原的脚本,你只需要提供一个小程序的 .wxapkg 文件,然后执行如下命令:
```node wuWxapkg.js [-d] <path/to/.wxapkg>```
此脚本就会自动将 `.wxapkg` 文件解包,并将包中相关的已被“编译/混淆”的文件自动地恢复原状(包括目录结构)。
PS: 此工具依赖uglify-es,vm2,esprima,cssbeautify,css-tree 等 `node.js` 包,所以你可能需要 npm install xxx 安装这些依赖包才能正确执行。更详细的用法及相关问题请查阅该开源项目的 GitHub repo。
最后,我们在微信开发者工具中新建一个空小程序工程,并将上述还原后的相关目录文件导入工程,即可编译运行起来,如下图为“知识小集”小程序的 .wxapkg 包还原后的代码工程:
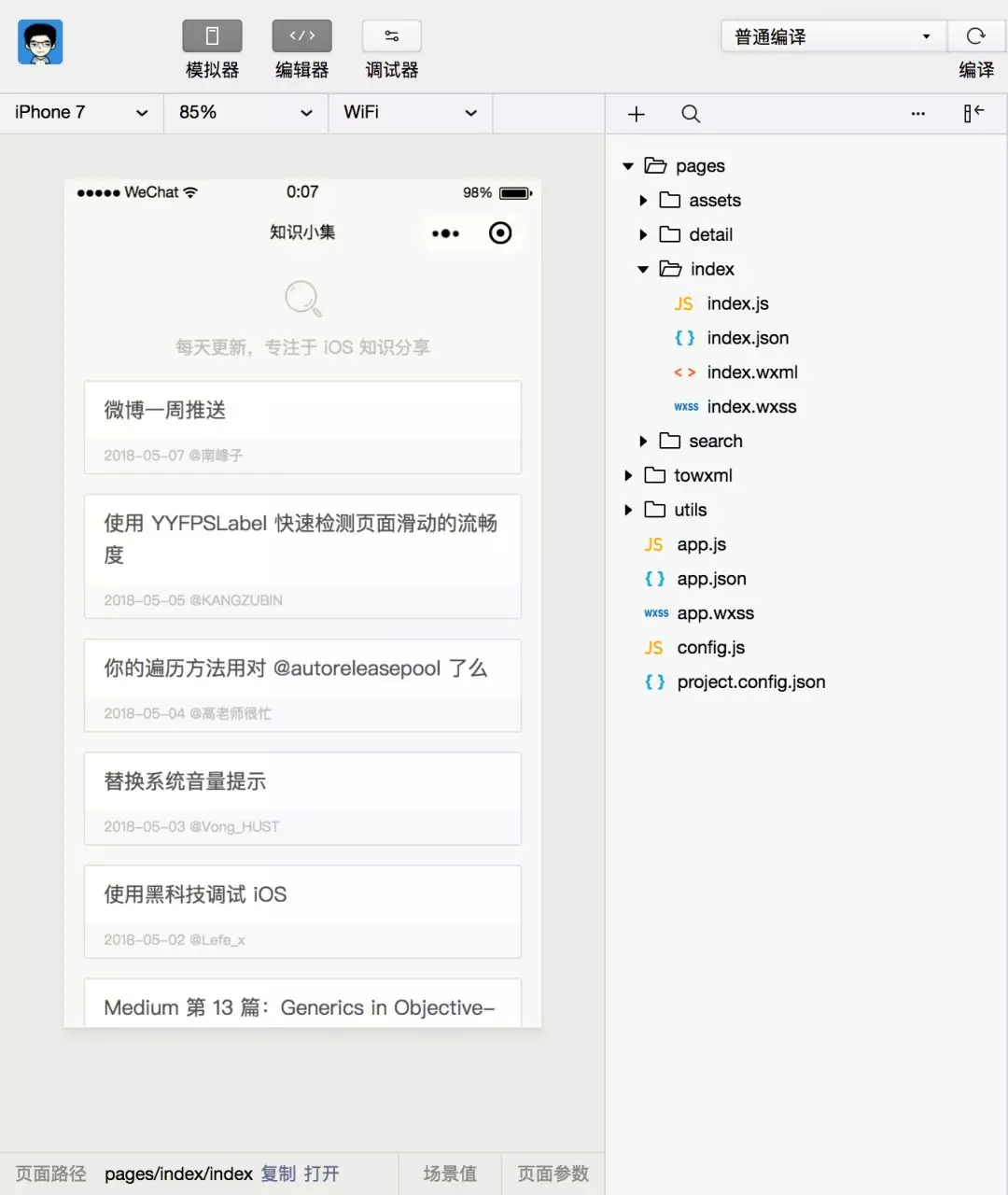
以上,大功告成!
## 总结
本文详细分析了 .wxapkg 解包后的各文件结构,并介绍了如何通过脚本“一键还原”得到任意小程序的源码。
对于一些简单的,且使用微信官方介绍的原生开发方式开发的小程序,用上述工具基本可以直接还原得到可运行的源码,但是对于一些逻辑复杂,或使用 `WePY、Vue` 等一些框架开发的小程序,还原后的源码可能会有一些小问题,需要我们人肉去分析解决。
## 后续
本文对小程序源码“编译”后的各文件内容结构及用途的分析相对比较零散,而且没有对各文件的依赖关系及加载逻辑进行研究,后续我们再写一些文章讲解微信客户端是如何解析加载小程序 `.wxapkg` 包并运行起来。
## 参考链接
* **wxappUnpacker** `https://github.com/qwerty472123/wxappUnpacker`* **wechat-app-unpack** `https://github.com/leo9960/wechat-app-unpack`
**特别感谢**:上文使用的还原工具来自于 GitHub 上的开源项目 `wxappUnpacker`,在此特别感谢原作者的无私贡献。更多内容推荐
从 0 到 1,带你解剖 MVP 的神秘之处,并自己动手实现 MVP !
脱离主工程独立运行,独立调试。这样就i使得在以后的版本维护及迭代中,
2021-10-30
本周四晚 19:00 知识赋能第八期第 3 课丨涂鸦小游戏的实现
本节直播将继续由巴延兴老师讲解《涂鸦小游戏的实现3》——本次分享将主要介绍三方面内容,包括OpenHarmony新增组件的介绍、新增组件的实际应用以及使用canvas组件,开发涂鸦小游戏,依旧干货满满!
2022-09-28
读《软件工程之美》之 02
宝玉老师在02课中,讲到工程思维:把每件事都当作一个项目来推进;确实非常有实用性;那什么是工程思维呢;工程思维,本质是一种思考问题的方式,在解决日常遇到的问题时,尝试从一个项目的角度去看待问题、尝试用工程方法去解决问题,站在一个整体而不
2021-12-23
2022-10-12:以下 go 语言代码输出什么?A:1;B:2;C:panic;D:不能编译。 package main import “fmt“ func main() { m := m
2022-10-12:以下go语言代码输出什么?A:1;B:2;C:panic;D:不能编译。
2022-10-12
JVM 进阶 (十八)——初识 Class 文件
关于类加载机制的相关知识在前面的博文中暂时先讲那么多。中间留下了很多问题,从本篇博文开始,我们来一一解决。
2022-05-24
JavaScript 基础知识 -JS 数据类型
JavaScript变量包含两种类型的值:基本类型值和引用类型值。
2022-10-24
17|项目打包与优化:前端必备的 Webpack 打包配置详解
为了让更多用户访问视频平台界面。这节课我们就一起来学习一下,如何将我们的前端代码打包上线。
2023-05-31
linux lsquic 编译
linux lsquic编译总结
2021-11-04
华为云开源项目 OpenTiny 的 TinyCLI 是什么时候开源的?
最近华为云开源了一个前端组件库项目OpenTiny,这个里面不仅包含有两个组件库项目,一个是TinyVue另外一个是TinyNG,当然除此之外还有一个脚手架工具是TinyCLI, TinyCLI是一个跨平台的前端工程化cli工具。 为开发者提供一系列开发套件及工程插件,覆盖前端开
2023-04-10
06|框架搭建:如何用 vue-cli 搭建一个前端框架?
相信通过这节课的学习,你可以掌握从0搭建前端框架的能力
2023-05-05
Spring Boot 2 教程:WebFlux 集成 Thymeleaf(五)
文章工程:
2021-12-15
AndroidStudio 最新版(2021.1.21)编译 C++ 代码生成 so 文件
上一章节介绍了如何配置so文件需要的开发环境,今天这一章节主要介绍,如何将C++代码编译成so文件。
2022-10-11
23|Android 系统开发:Android 系统开发的版本管理、编译与自动化测试
这节课我们会学习Android系统开发的版本管理、编译调试以及相关的自动化测试等实践,了解引入这些工具及实践的目的。
2023-04-03
Jenkins pipeline 如何到子文件中去执行命令
如果需要在 Jenkins 的子文件夹中执行命令,我们不能使用
2022-10-25
版本不兼容 Jar 包冲突该如何是好?
本文主要介绍了版本不兼容Jar包冲突时,通过使用maven-shade-plugin来重命名并打包(relocation)为不同的Jar包,从而实现在同一个工程中能够同时使用多个不兼容版本的Jar包。
2021-12-28
Python 基础(七) | 文件、异常以及模块详解
⭐本专栏旨在对Python的基础语法进行详解,精炼地总结语法中的重点,详解难点,面向零基础及入门的学习者,通过专栏的学习可以熟练掌握python编程,同时为后续的数据分析,机器学习及深度学习的代码能力打下坚实的基础。
2022-10-03
34|服务端功能扩展:如何对 Vue.js 全栈项目做服务端功能扩展?
作为前端程序员,我们要学会思考如何设计或解构一个全栈服务,并且化整为零地分析处理,逐渐沉淀自己对全栈项目的功能组合的认知,构建属于自己的全栈化知识体系。
2023-03-01
11|案例演示:如何将设计最终落地到代码?
今天我们以Sharing项目为例,结合组件化架构重构的5个步骤,最终将Sharing按新的架构设计落地到代码中。
2023-03-06
14|ECharts 实战:可视化如何更好地服务于创作者?
这节课,我们将会学习应用一款轻量级数据可视化组件库——ECharts。
2023-05-24
推荐阅读
3. Hudi 源码的编译
2023-09-08
平台工程动态 MonthlyNews 2023-7
2023-07-31
中移链合约常用开发介绍(五)合约项目编译
2023-05-22
《深入浅出 Java 虚拟机 — JVM 原理与实战》带你攻克技术盲区,夯实底层基础 —— 吃透 class 字节码文件技术基底和实现原理(核心结构剖析)
2023-07-13
Andriod 微信小程序自动化测试
2023-08-28
项目概览第 2 课:客服系统技术组件设计和架构演进
2023-09-25
项目概览第 1 课:客服系统业务分析和建模
2023-09-25
电子书

大厂实战PPT下载
换一换 
高玉娴 | 极客邦科技 InfoQ 数字化主编
邓艳琴(Clara) | 极客邦科技 会议主编
张熠 | 58 同城 信息安全部-安全服务团队负责人、架构师






评论 1 条评论