
Bryan Kane 讲述了 Coursera 是如何在他们的生产环境使用 GraphQL 的。以下内容翻译自作者的博客,查看原文: Coursera’s journey to GraphQL 。
在 Coursera,前端开发人员非常喜欢 GraphQL 的灵活性、类型安全和社区支持,但后端开发人员却不怎么直接接触 GraphQL。
在过去的一年,我们开发了一些工具将 REST API 转成 GraphQL,这样后端开发人员就可以继续开发他们熟悉的 API,而前端开发人员可以通过 GraphQL 访问他们想要的数据。
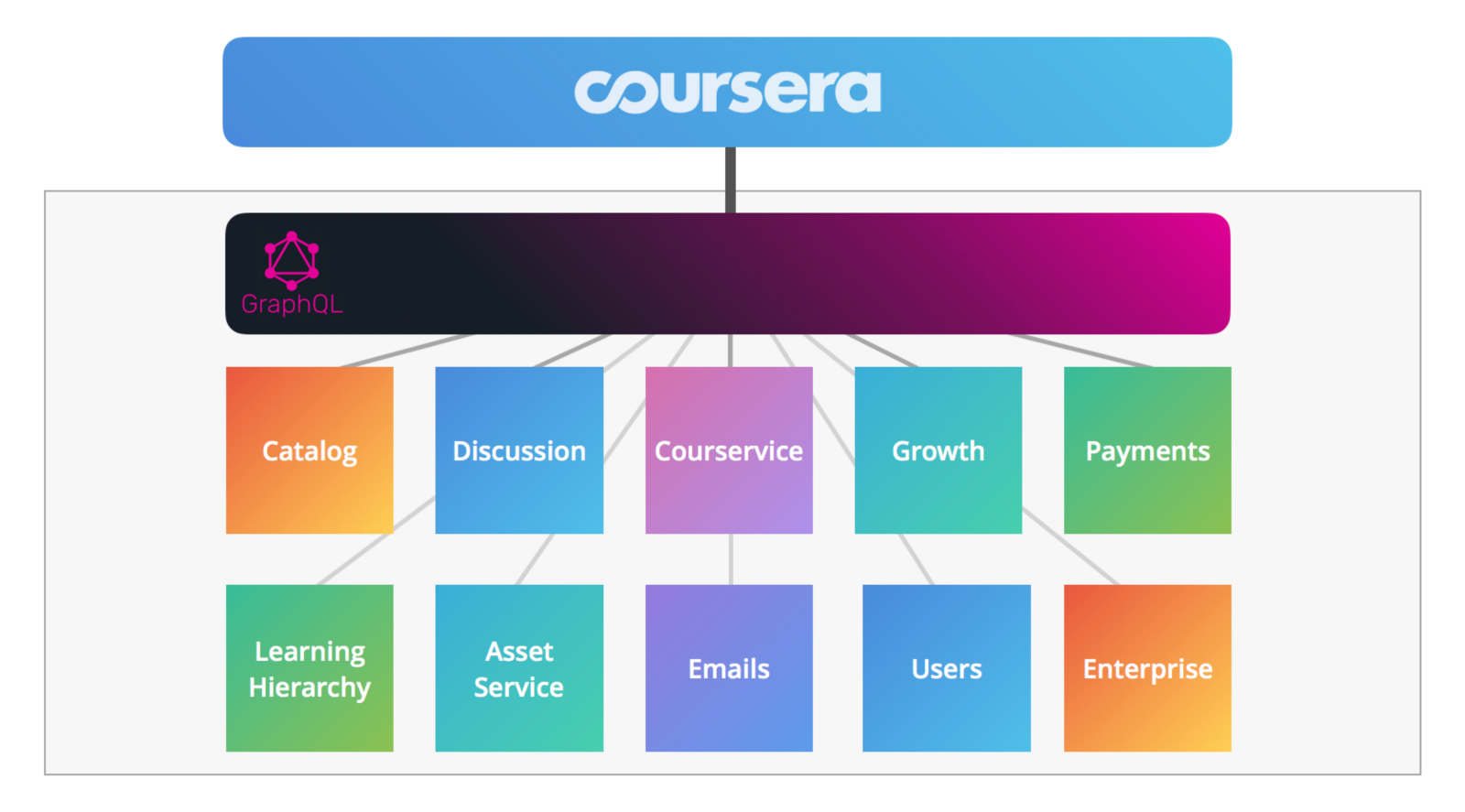
在这篇文章里,我们将介绍我们的GraphQL 之旅以及在这一过程中经历的成功与失败。
初始调研
Coursera 的 REST API 都是基于资源的,比如课程 API、导师 API、年级 API 等。这些 API 的开发和测试都很容易,而且在后端提供了非常好的关注点分离。不过,随着产品规模的增长,API 的数量也在增长,我们开始面临一系列问题,如性能问题、文档问题和易用性问题。我们发现很多页面需要四到五个网络来回才能获取到必要的数据。
我还记得在 Facebook 推出 GraphQL 时那种激动的心情,我们立刻意识到 GraphQL 将会解决我们的很多问题,我们可以一次性拿到必要的数据,并为 API 提供结构化的文档。但要在客户端完全使用 GraphQL 端点代替 REST 似乎是件不可能的事,因为:
- 那个时候,我们有超过 1000 个不同的 REST 端点(现在则更多),从 REST 到 GraphQL 的迁移成本是巨大的。
- 所有后端的服务间通信都使用了 REST API,而且后端服务为前端和其他后端服务暴露出来的是同一套 API。
- 我们有三种客户端(Web、iOS 和 Android)。
经过调研,我们找到了一种可以采用 GraphQL 的方案——我们决定在 REST API 之上增加一个 GraphQL 代理层。这种方式已经很常见了,并有详细的文档记录,所以这里就不再详述。
在生产环境使用GraphQL
我们先是构建了一个新的GraphQL 处理器,然后在生产环境启动了一个GraphQL 服务器用于向REST 端点发起调用,并将数据展示在演示页面上。经过几天的测试,我们确定这个方案是可行的。
短暂的成功
我们从这个项目中学到了一个教训,就是不要高兴得太早。
GraphQL 服务器在头几天很稳定,但在我们向团队演示数据页面那天,所有的 GraphQL 查询都失败了。这个让我们有点措手不及,因为从上次确认这个方案可行之后,就没有动过 GraphQL 服务器。
后来我们发现,下游的课程目录服务为了修复一个不相关的 bug 回滚到了前一个版本,导致 GraphQL 服务中的 schema 出现不一致。我们很快修复了 schema 问题,但我们也意识到,当 GraphQL 的 schema 规模增长到 1000 个并由 50 多个不同的服务来支撑的时候,要保持一切都同步是不可能的事情。在微服务架构里,如果有多个事实来源(source of truth),那么出现不同步是迟早的事。
自动化流程
于是我们试图寻找如何能够实现单个事实来源的解决方案——我们完全可以将 REST API 作为事实来源,因为我们的 GraphQL schema 就是基于这些 API 定义的。所以,我们需要自动化、决策性地构建我们的 GraphQL 层,体现出当前架构里正在运行的东西,而不是我们的臆想。
幸运的是,我们的 REST 框架为我们提供了所需的一切:
- 每个服务为我们提供动态的 REST 资源清单。
- 对于每一种资源,我们可以检查它们的端点和参数(比如,课程可以通过 id 获取到,或者通过导师查询到)。
- 我们可以收到由我们的 Courier Schema Language 为每个模型定义的 Pegasus Schema。
我们在 GraphQL 服务器上设置了一个任务,每五分钟 ping 一次下游的服务,获取所有必要的信息,然后在 Pegasus Schema 和 GraphQL 类型之间构建一对一的转换层。
接下来,我们使用之前开发的处理器逻辑在 GraphQL 查询和 REST 请求之间建立映射,得到一个全功能的 GraphQL 服务器,其更新速度的落后时间不会超过五分钟。
关联资源
我们使用 GraphQL 最主要的原因之一就是希望能够为页面一次性获取到必要的数据。不过,我们最初的方案只提供了 REST API 到 GraphQL 之间一对一的映射。如果不将资源关联起来,我们仍然需要进行多次 GraphQL 查询。尽管开发者体验得到了提升,但在性能方面并没有获得实际的好处。
我们的 REST API 都是一个个孤岛,但在使用了 GraphQL 之后,模型和资源需要对彼此有所了解,因为它们之间存在必要的关联。
资源之间并不会自动构建链接,所以我们定义了一个简单的注解,开发人员可以将它加在资源上面,用于指定资源之间的关系。例如,一个课程资源需要有一个导师字段,表示教授该课程的导师是谁。我们可以使用课程里的导师 ID 获取导师信息。我们称之为“前向关系”,因为我们知道使用 ID 可以获得哪些导师的信息。
courseAPI.addRelation( "instructors" -> ReverseRelation( resourceName = "instructors.v1", finderName = "byCourseId", arguments = Map("courseId" -> "$id", "version" -> "$version"))
如果我们想从一个资源跳到另一个资源,但又没有显式指定链接,那么可以使用反向查找。比如,为了找出某个用户的某一门课程的注册信息,我们可以在 userEnrollments.v1 资源上调用 byCourseId,这样就可以返回某个用户在某门课程上的注册信息。
有了这些链接,Coursera 的所有数据和资源就形成了一个网络。
结论
我们在 Coursera 的生产环境运行 GraphQL 服务器超过六个月的时间,虽然道路仍然崎岖,但 GraphQL 为我们提供的帮助无所不在。开发人员操作数据变得更加容易,GraphQL 提供的类型安全特性也让我们的网站变得更可靠,使用 GraphQL 加载数据也更快。
感谢徐川对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论