
根据 Yelp 今年第二季度财报,本地广告商数量已经约有12.8 万个。Yelp 的广告系统每天都要结算上一天广告被查看的次数和点击数,以及对应需要支付的费用。基于这样的结算数据,Yelp 要生成账单以及各种各样的报告。
广告系统后台团队最近把底层数据存储从MySQL 换成了 Cassandra ,软件工程师 Qui N. 和 Shafi B. 发表文章简单介绍了改变的原因,并分享了一些向 Cassandra 迁移的经验。
在 Yelp 公司创立初期,我们把广告数据存储在了 MySQL 中。伴随着系统规模扩大和广告产品的演进,我们发现 Cassandra 才是更好的选择。我们并不需要传统关系型数据库的特性,因为我们没有什么事务操作,也不需要对数据表进行联合查询。Cassandra 对我们最大的好处就是方便扩展存储、有弹性的模式定义和高写入性能。
具体来说就是:
- 方便扩展存储:Cassandra 是分布式系统,只需要增加节点就可以扩充存储空间;
- 有弹性的模式定义:业务需求会经常要求改动数据的模式定义,Cassandra 很适合做这样的事;
- 高写入性能:Cassandra 写入性能是非常高的,Netflix 曾经在一次测试中达到每秒超过 100 万次的写入;由于 Yelp 的广告数据越来越多,写入必须保持在有限的时间内完成;
文章重点是与大家分享在使用 Cassandra 的过程中得到的经验。
1、把查询语句和表的模式定义放在一起综合考虑:Cassandra 本质上是结构型的键 - 值型存储,表的主键选择对后续的查询语句性能影响非常大。Cassandra 的表主键包括分区键和集合列,前者决定了数据能否均匀分散到多个节点上,后者决定了相同分区键的数据在同一个分区内如何排序。要根据查询语句决定表的定义,反之也要根据表的定义来改写查询语句,两者综合才能达到最佳性能。
2、数据行定义会影响数据压缩:Cassandra 的数据压缩就是合并对数据的更新操作的过程。业务程序更新数据的次数和方式决定着该选择 Cassandra 的哪种压缩策略。
其根本原因在于在 Cassandra 底层是把属于每个分区键的数据以宽行存储的。以 Yelp 的业务举例,以 campaign_id 为分区键,以 day 为集合列,那么在底层数据其实是这样存储的:

而不是大家想当然的这样:
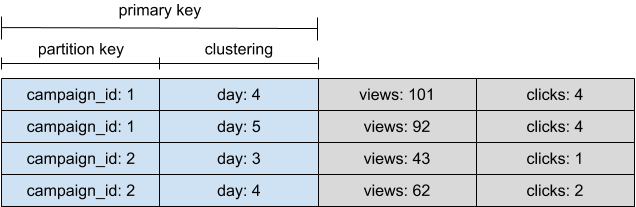
Cassandra 的默认策略 size-tiered compaction 合并操作并不频繁,而 leveled compaction 会保证未合并的对相同分区键的更新操作不会超过一定数量,因此虽然在写入时会造成更多的 I/O,却对统计查询有比较好的性能,因此更适合 Yelp 的业务。
3、迁移到 Cassandra 会增大写入量:使用 MySQL 会希望表设计遵守范式,可使用 Cassandra 之类的 NoSQL 数据库,违反范式反而常常会获得更好的性能。虽然 Cassandra 出色的写性能在一定程度上可以弥补这一代价,但千万不要对此掉以轻心。
4、Cassandra 的批量操作语句很有用:MySQL 的批量操作语句常用来提高性能,可是Cassandra 的批量操作语句却常常只是用来保证原子性的。因为Yelp 选用的 cqlengine 在底层写入操作是同步的,在写入量大的情况下就性能堪忧,因此他们最终通过批量写入来解决这个问题。批量操作上线后立刻将写入性能提高了一倍。
5、TTL 机制可能带来的麻烦更多:Cassandra 支持为每个字段设置生命期(Time To Live,TTL),如果某个字段设置了 TTL,那么在过期之后就会自动删除,不再需要用户操心。可是对于 Yelp 的这种分析型业务,由于需求的不确定性,设置这种 TTL 数据可能还不如定期检查删除一遍对整个系统影响更小。
相对于 MySQL,Yelp 因为 Cassandra 的易扩展、有弹性的模式定义和高写入性能等特性而选择了后者。如果你也在构建一个写入量很大的系统,或者在重构系统,那 Yelp 的经验也许会对你有用。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论