
A/B 测试在 Twitter 的整个产品流程中是着非常核心的一个环节,Twitter 通过它来验证新功能是否有效。前段时间,Twitter 发布了博客介绍了他们是如何实施A/B 测试的。日前,他们又介绍了A/B 测试背后的系统。
概览
Twitter 从 2010 年开始使用他们的 A/B 测试工具 DDG(Duck Duck Goose ),它已经成为聚合数据、记录用户行为、分析指标的系统性平台。
下图为 A/B 测试工具概要数据流。
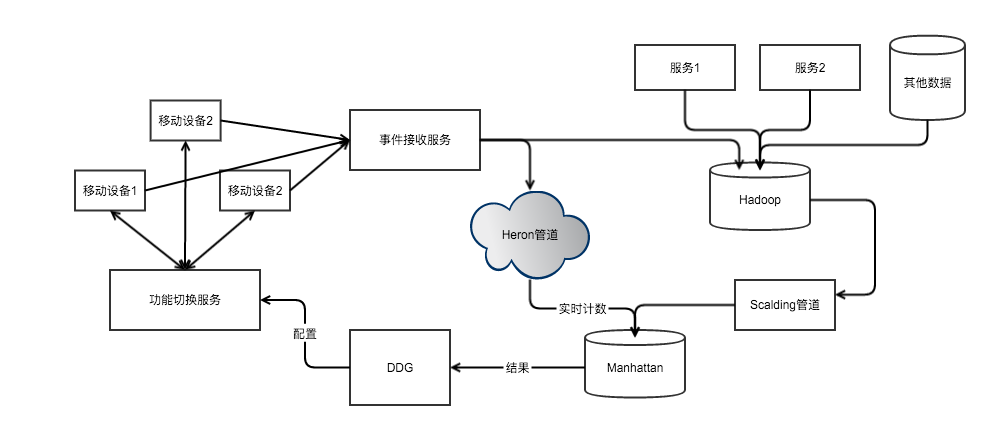
A/B 测试的基本流程
通常来说,A/B 测试需要事先设置一些参数和度量值。通过 DDG,测试人员可以直接通过网页设置 A/B 测试的细节:
- 实验范围,比如限定语言、国家、操作系统等参数;
- 实验对照组,确定测试修改点和当前产品的区别;
- 实验指标,设置需要追踪的指标,DDG 默认会采集一些基础数据,其他指标可以自定义,或者从库中选取;
通过上述设置,DDG 会提供给实验人员一些代码,作为“需求开关”。然后,系统会开始记录实验过程中需要度量的数据。
指标定义
DDG 提供三种指标类型:
- 内置指标,大部分由实验团队定义和维护(例如登录次数、发推次数等),在实验中这些指标值会被自动追踪;
- 实验者定义和配置的指标,实验者可以通过轻量级的领域专用语言(Domain Specific Language,DSL)定义需要记录的事件,DDG 的管道会为实验者计算这些指标;
- 导入的指标,这些指标完全由 Twitter 工程师创建,实验者可以创建自定义聚合方法,度量自定义内容;
这些可以被聚合到“指标组”中,以方便实验人员选择。同时,每个指标组都由创建人维护,所有修改记录都会被记录。
数据处理管道
指标数据收集,都会通过管道进行运算。聚合数据也是整个系统中最大的挑战。一个指标源数据每天可能会产生非常大数量级的数据。
实验平台使用 Hadoop 的 Map-Reduce 任务来解决运算的性能问题。为了尽可能提高性能,Twitter 团队还和 Hadoop 团队共同合作,做了大量调优。
另外有一些轻量级的流处理任务,会通过 TSAR 在 Twitter 的 Heron 平台进行实时计算。
上图中的 Scalding 管道,可以被认为有三个不同的阶段。
首先,将原始数据聚合成每个用户、每个小时的基础数据集。这些数据会被作为下一阶段的输入数据,同时也会被用作计算其他数据。
然后,第一阶段生成的数据会加入 A/B 测试的表达式,并在实验过程中计算每个指标、每个用户的聚合数据。第二阶段的结果可以被用于深入挖掘结果。
最后,第三阶段会汇总所有实验数据。这些实验数据会被加载到 Manhattan 中,产品团队可以在内部看板中进行浏览。
总结
支撑 Twitter A/B 测试平台的技术设施非常广泛,究其原因主要是因为庞大的数据量。平台需要对大量数据加以处理,以进行分析和实验。通过管道的设计,也使得平台可以对多粒度数据进行不同类型的分析。
感谢徐川对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 )。
)。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论