
在前文《分支策略(续)》中,我们讨论了多组件应用程序的持续集成策略,即:为相对独立的组件创建自己专属的代码库,然后通过现代持续集成工具进行组件间的持续集成。Joe 的团队在首次发布之后,开始使用这种方式。然而,没有多久,他们就遇到了一个问题:一次提交构建所花费的时间太长。
一天,Joe 就早早地来到了办公室。因为他前一天下班前,他开发的用户故事还有一小点就完事儿了。他想利用早上这点儿时间把它搞完,交给测试人员进行测试。他修改了某个模块的一段代码,在本地构建测试通过以后,就提交了, 然后起身去楼下买些早点。十五分钟后,他回到了电脑前,令他沮丧的是,这次构建还在进行最后的阶段,即所有模块集成测试和系统级测试。他只好又起身去冲了杯咖啡。然后,一边看着屏幕上的构建进度条,一边喝着咖啡。七分钟后,构建终于成功结束了。虽然这是一次成功的构建,但总是觉得不爽,花了二十多分钟才做完提交构建。于是,他开始仔细地查看起构建脚本和构建日志。
一、一次生成,多次复用
中午吃过午饭,他把Bob 和Alice 叫到一起,开始讨论早上他遇到的问题。
“的确是非常烦人,现在构建时间太长了。”Alice 说道。
“我今天早上查看了一下我们的构建日志,发现构建时间长的原因之一是:每种测试开始之前都要更新代码,再重新编译一次。”Joe 说道。
Bob 提出了一个解决方案,并画在了白板上。“我们是否可以建立统一的产物库,每次构建的产物都以一定的规则放在其中?这样,后续的测试需要使用这些二进制产物的话,直接从产物库中获取即可。”(如图 1 所示)
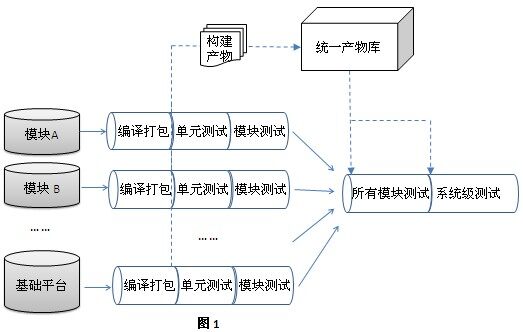
“听上去不错。然而,我们是否需要把每次构建中产生的内容都放入产物库,这会非常快地吃掉我们的磁盘空间。”Alice 不无担心的说。
“目前构建完成以后,所有的产物都放在那台构建机器上。我们也遇到过因构建机器硬件问题或误操作将所有重要历史信息都丢失的事情。所以,我们至少需要备份。”Bob 回答道,“另外,将每次构建的产物放在统一产物库中,我们就可以解决 Joe 刚才提出的重复编译问题。当然,我们需要有选择地将重要的构建产物放到统一产物库中,而不是所有内容。通过在每次构建后增加一个上传任务,让各小组将其认为有用的信息上传到产物库,比如构建日志、测试报告、构建后的二进制文件等。但一些临时文件就没有必要了。当然,这只能缓解产物库膨胀的速度。尽管持续构建的次数非常多,但我们并不是需要一直保持所有构建的产物,所以,可以定期删除那么没有保留价值的构建产物,比如对那些重要构建的产物进行标记,其它的就可以删除了。”
Alice 和 Joe 都点了点头,表示同意。但 Joe 的眉头马上又皱了起来。“嗯,好象这里还有点儿问题。”
“什么问题?”Alice 和 Bob 同时问道。
Joe 说道:“对于我们平台中的一些小游戏组件来说,这没有什么问题。因为它们的构建产物都不太大,网络传输带宽和速度都不是问题。但是,对于那些很大的二进制文件或测试数据来说,这么做的话,可能就有问题了。”大家都点了点头,并开始思考这个问题。
忽然,Joe 叫道:“不好意思,其实这不是个真正的问题。首先,我们的测试数据变化就不频繁,原来也没有放在产物库中,而是放在了一个共享目录中进行版本管理。所以,这部分在构建中的做法与之前没有什么不同。其次,对于较大的二进制文件,只要在需要它的构建机器上把它缓存起来。那么在下一次构建时,构建脚本可以对这个本地版本进行验证,如果版本正确且没有被破坏(比如通过 MD5 验证)就可以继续使用。否则,就再从统一产品库取出正确的文件将其覆盖就行了。”
“这么做还有一个好处,而且是非常重要的好处。”Alice 补充道,“我们的手工测试版本也可以从统一的产物库中拿到,这就保证了自动化测试所有的二进制文件与部署到手工测试环境中的二进制文件是同一个文件了,也就不会出现因重新编译时的环境不同而导致的不一致问题了。而当我们做上线部署时,也从这个统一产品库中获取,从而做到自编译开始直到上线部署的二进制包的一致性啦。”
于是,Joe 与团队一起对其持续集成平台和所有构建进行了改造,将其打造成了一个具有组织级产物库的持续集成和发布管理平台。他们不但有效地缩短了每次构建的时间,还可以轻松地通过产物库追踪到每个上线版本在代码版本控制库中的对应代码,让问题追查变得更容易了。
二、依赖管理
一个月后,根据市场的需求反馈,他们开发的一个游戏升级了,反应速度非常快,效果非常好。但引申出来的一个问题是:游戏和平台的升级频率不一致,持续集成应该怎么做。对于 Joe 的团队来说,是一个非常大的问题,因为他们的开发流程严重地依赖于持续集成平台。于是,Joe 和团队的核心成员打算讨论一下,如何应对目前这种情况。
在会议室的白板前,Joe 画出了当前所用的持续集成策略(如前图所示)。
Bob 说道:“到目前为止,我们已经发布了几次,而且最近一次只发布了一个游戏应用。我们如何管理我们的发布流程呢?在我之前工作过的公司中,产品会有几个版本,包括稳定版本、已对外发布或即将发布的版本、最新版本:用于公司内部测试。每当将要发布新版本时,就拉出一个分支,进行内部测试,并修复严重的缺陷。当没有严重缺陷时,才能作为稳定版本公开发布。”
Alice 答道:“对于单个的软件交付产品来说,通常可以通过“按发布拉分支” 的方式进行开发,正如我们最开始所使用的持续集成策略。但是,现在我们的游戏平台与单个交付产品不同。我们有自己的服务器集群,只要测试覆盖率及测试质量足够好,测试速度足够快,我们就可以通过小流量试验部署后再大规模上线的方式进行发布。现在,我们的问题是由于各个游戏组件的发布频率各不相同,组件存在依赖关系,导致很难决定在持续集成过程中,到底应该使用哪个依赖版本。尤其是我们现在还有一个公共库,被多个组件使用。”
Joe 说道:“我们先梳理一下整个平台上的依赖关系吧。通常来说,软件中的依赖关系通常包括编译时依赖、测试时依赖和运行时依赖。而从依赖形式上可以分为库依赖和组件依赖。所谓库依赖,是指依赖于那些不受控的库文件,比如我们使用了一些开源或者付费的的类库文件或工具,这些库文件的特点是更新较慢,甚至基本不需要更新。而组件依赖是指依赖于那些由自己团队或公司内的其它团队开发的组件,这类依赖的特点是更新频率相对高,有些甚至非常频繁。对于库文件依赖,我们可以在代码库中建立一个目录,叫做 lib,并在其下建立 build、test、run 三个子目录,把我们所依赖的库文件放到相应的子目录中。同时,每个库文件的文件名中最好包含它的版本号,如 nunit-2.6.0.11089.bin。这样,就很容易看出依赖了哪些库文件。”
Bob 接道:“可惜我们不是用 Java 平台,否则我们可以用象 Maven 或 Ivy 这样的工具来管理这些外部库依赖了。而且,同时可以在公司内部利用 Artifactory 或 Nexus 这样的开源工具建立一个内部统一服务器,专门管理公司内部所用的这些库依赖。”
Alice 说道:“我们也可以自己做一个简单的依赖管理系统。比如使用 Key-value 的格式用文本文件来描述所用到的库文件名及版本号及存放位置,然后再写个通用脚本读取信息下载到本地使用。”
Bob 接着问道:“对于这种库文件的依赖管理相对容易一些。而我们面临的重要问题好象是组件依赖管理。有什么好办法吗?”
Joe 想了想,说道:“方法倒是有几个,各有优缺点。一种方法是将组件依赖转成库依赖。其适用的场景是该组件经过一段时间的开发的维护后已趋于稳定,变化不太多。此时就可以将这个组件打包后与其它外部依赖库放在一起,并加入正确的描述,以便依赖于它的所有组件都可以正确地拿到正确的版本。还有一种方法是我们目前所用的方法。即每个组件各自进行持续构建,然后再做集成构建。其中存在的问题是我们如何管理各组件不同版本之间的组合关系。我们一直使用的策略是无论哪次提交,都会触发整个构建。目前要做的有两件事:一是将公共库独立出来,进行单独构建,并且一旦构建成功,自动触发那些依赖于它的其它组件构建,最后进行集成构建。只要我们记录每次构建后的版本及源代码的 revision 就行,以便可以追踪。二是将游戏平台的持续构建触发其它游戏组件的持续集成。所以,触发关系应该是这样的。”Joe 拿起笔,在白板上重新画了一下触发关系图(图 2)。
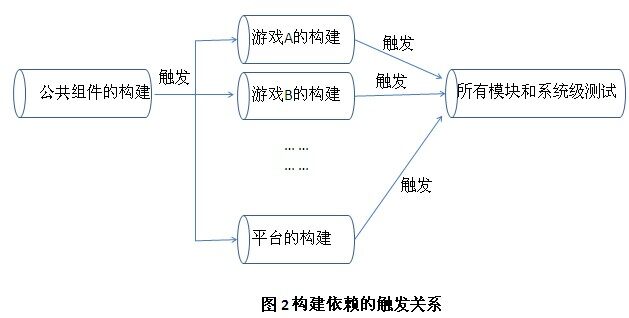
Bob 摇了摇头,说道:“这样还是解决不了我们之前说过的问题,即我们的发布频率不一致,如何来管理这些发布之间的关系。”
“噢,这个问题是这样的。”Joe 回答道:“我认为,我们之前单独发布一个游戏组件是不对的。我们因市场压力而将该游戏组件直接部署到生产环境中,尽管在发布前的评估认为,该游戏所依赖的平台接口没有发生变化。正确的做法有两种:(方案 A) 将平台作为一个整体一同发布,因为我们对平台也做了修改,当时,所有的持续集成测试都是基于主干的最新版本所做的。(方案 B)让所有游戏组件依赖于游戏平台的最新发布的稳定版本进行开发。由于平台的新功能开发较慢,所以只要平台接口不发生变更,各游戏应用都可以基于平台的稳定发布版本进行快速更新。但只要某个游戏需要修改平台的接口,就必须与平台的最新代码进行持续集成,并一同发布。”
Alice 皱了皱眉,说道:“这么看来,对于整个软件来说,能够保持主干随时可以发布才更容易管理组件依赖。因为每当需要发布时,直接做主干发布就行了。实在不行的话,只要将所有组件在同一时间点拉出一个发布分支,然后统一上线就行了。”
Bob 说道:“这样也有问题。我们的部署会很麻烦,时间可能会很长。”
Joe 笑着说:“部署麻烦,我们可以通过一系统列的自动化操作来解决。部署时间长的话,我们使用的是集群部署,因此可以采用分批替换的方式来部署。但这种发布方式给我们带来的益处是可以很快的响应市场需求。”
Joe 拿起杯子喝了口咖啡,接着说道:“当然,这对我们的开发工作也提出了挑战。我们必须使用多种手段才能做到主干持续可发布状态。比如(1)将新功能隐蔽起来,直到它完成为止;(2) 把所有的变更都变成一次次非常小的增量式修改,每个修改都做到可发布 ;(3)通过抽象达到分支的目的( Branch by Abstraction )。另外,我们的自动化测试也需要保持在较高的覆盖率,并丰富其它类型的自动化测试,比如性能测试,压力测试等。如果遇到特殊情况,我们再坐下来商量对策。”
Bob 仍旧有点迟疑,“这样可能会增加我们的开发成本。不过,可以试一下,看看效果如何。”
于是,整个团队开始行动起来了。他们在这条道路上还会遇到什么情况呢?让时间来回答这个问题吧。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论