

1. 前言
伴随链家业务线的拓宽和发展,以及数据生态的建设,数据规模快速增长。从 2015 年大数据部门成立至今,集群数据存储量为 9PB,服务器规模为 200 台+。与此同时,数据需求也随着业务的发展落地不断增长,如统计分析、指标 API、运营报表等,不同业务需求差异较大,维度越来越多,需要定制化开发。面对数十亿行级别的数据,低延迟响应的特性,保障服务稳定、数据准确,链家的数据分析引擎经历了如下的发展历程。
2. 早期的 ROLAP 架构
起初,数据规模不大,增长不是很快。而且,数据需求比较零散,处于摸索阶段。采用如下 ROLAP 引擎,支撑数据分析:
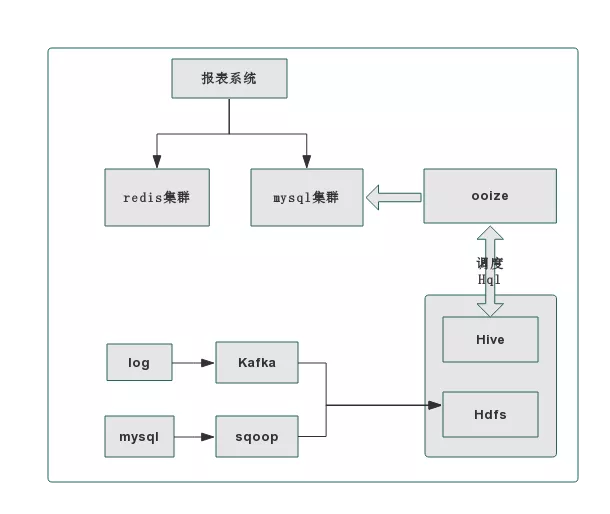
具体处理流程:数据源接入 hdfs,加载进 hive。数据开发工程师根据业务需求,开发 ETL 脚本,配置 OOZIE 任务调度执行,根据数据仓库分层模型,逐层生成数据,最终推送到 mysql,根据维度筛选、聚合展示。
随着数据规模的增长和需求的增多,瓶颈逐渐显现。每个需求都要开发数据脚本,维度增加,开发周期拉长,同时需要耗费更多的人力,无法快速产出数据和响应需求变化。
3. MOLAP 多维引擎
由于,ROLAP 无法实时响应、服务不稳定的问题愈加凸显,因此着手引入 MOLAP 引擎,搭建平台级的 OLAP 多维分析服务。
OLAP 领域还没有事实上的标准,很多引擎都可做类似事情,如普通的 MPP、Kylin、Druid 等。技术选型过程中,重点关注了基于 MapReduce 预计算生成 Cube 并提供低延迟查询的 Apache Kylin 解决方案。Kylin 最初由 eBay 开发,并于 2014 年 10 月贡献至开源社区,2015 年 11 月正式毕业成为 Apache 顶级项目,是首个由国内开源的 Apache 顶级项目。
Kylin 支持 ANSI SQL 大部分查询功能,标准 SQL 语法+JDBC/ODBC 驱动可以很方便的和现有系统做集成;用户可以与 Hadoop 数据进行亚秒级交互,随着数据量和维度组合的增长,性能衰减也不会特别明显;Cube 模型的合理设计,并支持增量更新;同时,具备良好的可伸缩性,核心组件可扩展,社区活跃。可以在数据准确度、存储空间、性能之间灵活调整,找到最适合需求场景的平衡点。
4. Kylin 基本原理
通过上面章节的分析,我们对在线 DDL 的实现有了一定了解,在了解其优势的同时我们还应该了解一些问题和限制,以方便我们后续遇到此类问题时有更全面的考虑。
如下,为 Kylin 架构图:
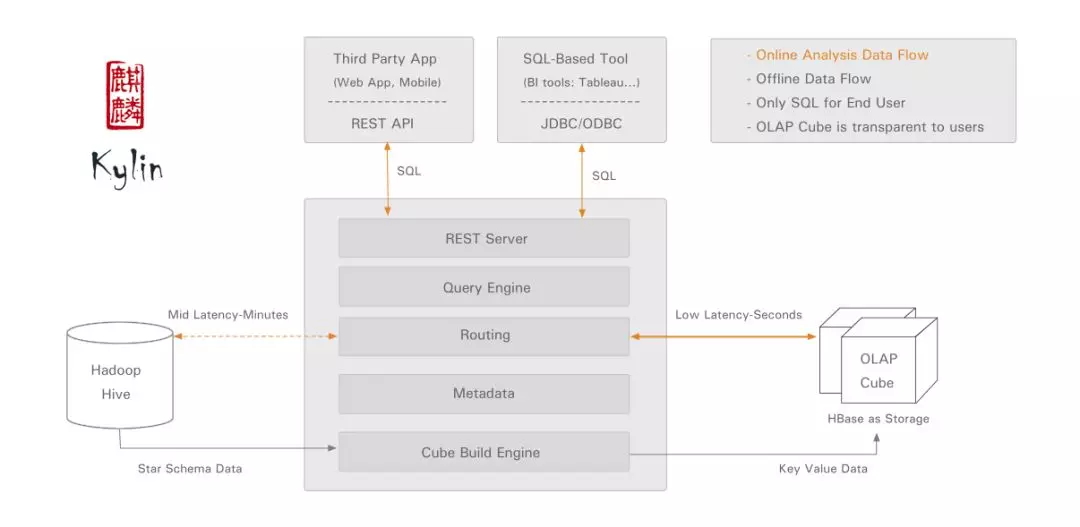
Kylin 数据源常采用 Hive,使用 MapReduce 作为 Cube 构建的引擎,预计算结果存入 HBase,对外暴露 Rest API/JDBC/ODBC 的查询接口。因为 Kylin 支持标准的 ANSI SQL,所以可以和常用分析工具(如 Tableau、Excel 等)进行无缝对接。
Data Cube,代表数据立方体。包含维度和指标,由不同维度构建出的多维空间,包含了所有要分析的基础数据,所有的聚合数据操作都在立方体上进行。Kylin 的核心思想是预计算,对多维分析可能用到的度量,基于维度组合做预计算,计算结果保存成 Cube。把高复杂度的聚合运算、多表连接等操作转换成对预计算结果的查询,通过空间换时间,获得快速查询和高并发能力。
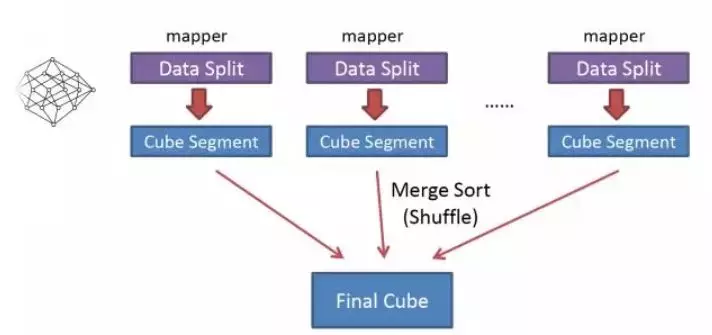
Kylin 有两种预计算方法:一、计算出最底层的 cuboid,也就是包含全部维度的 cuboid(相当于执行一个 group by 全部维度列的查询),然后在根据最底层的 cuboid 一层一层的向上计算,直到计算出最顶层的 cuboid(相当于执行了一个不带 group by 的查询);二、Fast Cubing,在采用逐层计算时,由于 Mapper 不做预聚合,即便经过 Combinder,但是依然要通过 Reducer 做聚合,期间不断的写入和读取 hdfs,耗费集群资源和耗时。fast cubing 算法最大化利用 Mapper 端的 CPU 和内存,对分配的数据块,将需要的组合全部计算出,再由 Reducer 再做一次合并(merge),经过一轮 Map-Reduce,便可计算出完整数据的所有组合。Fast Cubing 原理,如下图:
5. 链家 Olap 平台及 Kylin 使用
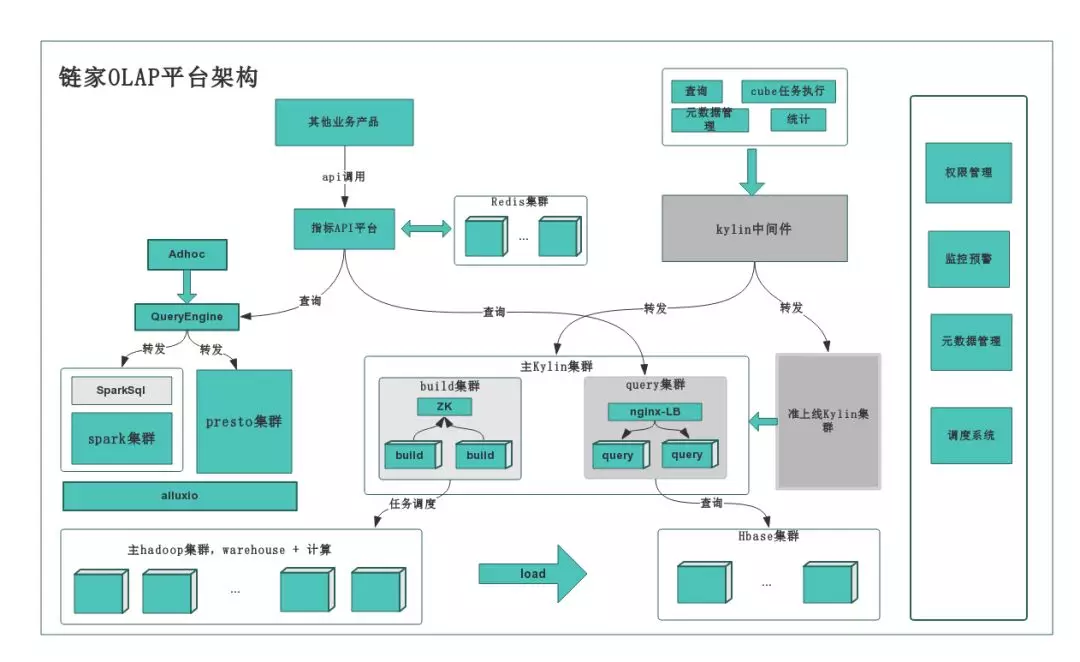
如上,为链家 Olap 平台结构,于 16 年底搭建。Kylin 采用集群部署模式,共部署 6 台机器,3 台用于分布式构建 Cube,3 台用于负载均衡查询,query 单台可用内存限制在 80G。同时,计算集群一旦运行大任务,内存压力大的时候,HBase 就会性能非常差,为避免和计算集群互相影响,Kylin 集群依赖独立的 Hbase 集群。同时,对 Hbase 集群做了相应的优化,包括:读写分离、SSD_FIRST 优先读取远程 SSD、并对依赖的 hdfs 做了相应优化。
由于 Kylin 只专注预计算,不保存明细数据,对于即席查询和明细查询,通过自研 QE 引擎实现,底层依赖 spark、presto、hive,通过特定规则,路由到相应查询引擎执行查询。多维分析查询,由 Kylin 集群提供查询服务,可实现简单的实时聚合计算。
当前 Kylin 主要查询方为指标 API 平台,能根据查询 sql 特征,做相应缓存。指标 API 作为数据统一出口,衍生出其他一些业务产品。使用统计,如下:Cube 数量 500+,覆盖公司 12 个业务线。Cube 存储总量 200+TB,数据行万亿级,单 Cube 最大 40+亿行。日查询量 27 万+,缓存不命中情况下,时延<500ms(70%), <1s(90%),少量复杂 sql 查询耗时 10s 左右。
6. Kylin 应用场景及使用规范
适用场景:数据规模大,非实时,目前能支持小时级别;维度组合和查询条件组合在可预见的范围内;查询条件扫描范围不会太大;不适合需要大范围模糊搜索排序的场景(类似 Search)。
如何能规范的使用 Kylin 很重要,在 Kylin 建设初期,踩过很多坑。并不是程序的错误,而是未能详细了解 Kylin 使用流程及规范,逐渐摸清积累了一些经验,沉淀到公司 wiki,供相关人员参考。大致如下:
维度优化,预计算的结果需要存储到 hbase,且支持实时查询,因此,在配置维度时,要考虑到存储和查询的优化。包括:维度的编码,根据维度的值类型,选择合适的存储类型,可节省空间,加快 hbase scan 效率;可根据业务需要,对维度进行分片存储,增加查询的并发度,缩短查询时间;基数允许范围内的维度,尽量采用字典编码;对于分区字段,一般格式为 yy-MM-dd hh:mm:ss,若只需要细化到天级别,可保存为数字类型 yyMMdd,极大降低维度基数。
根据 hbase 的查询特性,rowkeys 是由维度组合拼接而成,因此要考虑到以后查询场景:对于查询频繁的维度,在设置 rowkeys 时,优先放在前面。
维度组合优化,由于维度的组合影响最终的数据量,因此如何能减少维度的组合,是 Cube 配置时所要考虑的。根据业务需要,及 Kylin 支持的特性,可进行的维度组合优化有:使用衍生维度,只物化维度表的主键,牺牲部分运行时性能进行实时 join 聚合;使用聚合组,将相关维度内聚成一组,并在聚合组内,根据维度的特征,配置强制维度、层级维度、联合维度。聚合组的设计可以非常灵活,例如,高基数的维度,可以单独一个 group。
及时清理失效数据。由于构建过程出错或者集群故障,会导致一些垃圾文件,随着时间积累的一些无用 segment,不但占用存储空间,增加 namenode 内存压力,以及占用 hbase、hive 及 kylin 元数据空间,因此需要定期清理掉,保持存储环境干净。
应该实时监控集群状态,重点关注 Cube 构建和查询的低延迟,不断优化数据模型及 Cube 的设计和存储,根据用户真正的需求,在存储、构建及查询性能间找到最佳的平衡点。
7. 链家 Kylin 能力扩展
当前,kylin 在用版本为 1.6,最新版本为 2.3。自 2.0 版本之后,又新增了一些新的特性,配置文件和属性也做了一些调整。由于,Cube 数据量大,涉及业务方多,在当前无明显瓶颈的情况下,没有实时更新新版本。但是,引入了 2.0+新增的一些重要特性,如分布式构建和分布式锁。
我们维护了自己的一套 Kylin 代码,使用过程中,针对特定场景的进行一些优化开发,包括:
支持分布式构建。原生 kylin 是只能有一台机器进行构建。的当 kylin 上的 cube 越来越多,单台机器显然不能满足任务需求,除了任务数据有限制,任务多时也会互相影响数据构建的效率。通过修改 kylin 的任务调度策略,支持了多台机器同时构建数据。使 kylin 的构建能力可以横向扩展,来保证数据构建;
优化构建时字典下载策略。原生 kylin 在 build cubiod data 时用的字典,会将该字段的全部字典下载到节点上,当字段的字典数量很多或者字典文件很大时,会在文件传输上消耗很多不必要的时间。通过修改代码,使任务只下载需要的字典文件,从而减少文件传输时间消耗,加快构建;
全局字典锁,在同一 Cube 所任务构建时,由于共享全局字典锁,当某执行任务异常时,会导致其他任务获取不到锁,此 bug 已修复并提交官方;
支持设置 Cube 强制关联维表,过滤事实表中无效的维度数据。kylin 创建的临时表作为数据源。当使用 olap 表和维表关联字段作为维度时,会默认不关联维表,直接使用 olap 中的字段做维度。而在 Build Cube 这一步又会使用维表的字典来转换维度的值。如果 olap 中的值维表中没有就会产生问题。我们通过增加配置项,可以使 kylin 强制关联维表,来过滤掉 olap 表中的脏数据;
Kylin query 机器,查询或者聚合,会加载大量的数据到内存,内存占用大,甚至存在频繁 Full GC 的情况。这种情况下,CMS 垃圾回收表现不是很好,因此更换为 G1 收集器,尽量做到 STW 时间可控,并及时调优。
除了上述对 kylin 本身的修改外,我们开发了 kylin 中间件实现了任务调度、状态监控、权限管理等功能。
8. Kylin 中间件
中间件承接 Cube 管理及任务的调度,对外屏蔽了 Kylin 集群,架构图如下:
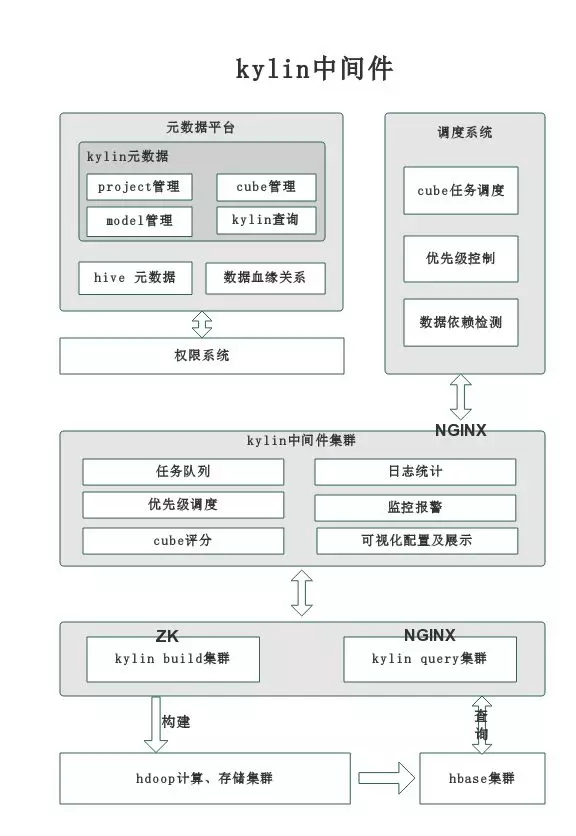
可实现如下功能增强:
理论上,可实现无限容量队列,现实中不会有这么大任务量,也不会一直堆积;
同时,针对特定的 Cube,实现优先调度,保障重要数据的及时产出;
元数据管理平台,可通过中间件执行 sql 查询,而指标 API 平台,需要预先在元数据管理平台配置 API 查询接口,配置时可看到自身权限对应的数据,由此实现权限的管控;
当任务执行失败,可进行有限次数重试,重试不成功会报警;
同时,可实现并发控制,由于 Kylin 集群的承载能力有限,过多的任务同时执行,会造成大量任务失败,目前设置最多提交 50 个构建任务同时运行。
9. 总结
未来,我们会持续跟踪业务需求,不断优化集群性能,提升集群稳定性和易用性。并重点关注大结果集查询性能、Spark 构建引擎、任务资源隔离等。
链家网大数据架构团队负责公司大数据存储平台、计算平台、实时数据流平台的架构、性能优化、研发等,提供高效的大数据 OLAP 引擎、以及大数据工具链组件研发,为公司提供稳定、高效、开放的大数据基础组件与基础平台。
本文转载自公众号贝壳产品技术(ID:gh_9afeb423f390)。
原文链接:
https://mp.weixin.qq.com/s/GHgJRVkU3hsrSLy-Rhviwg

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论