

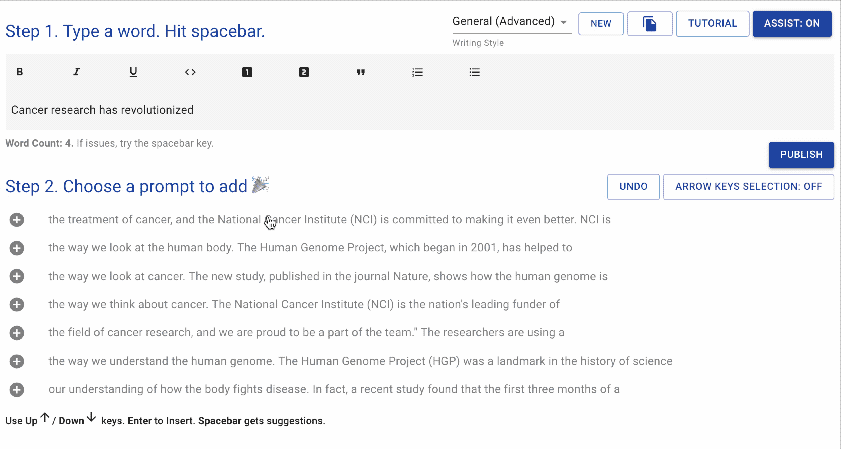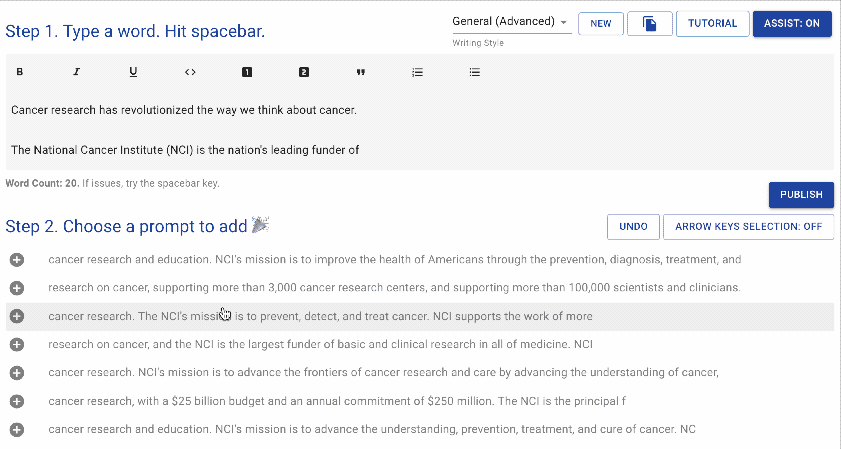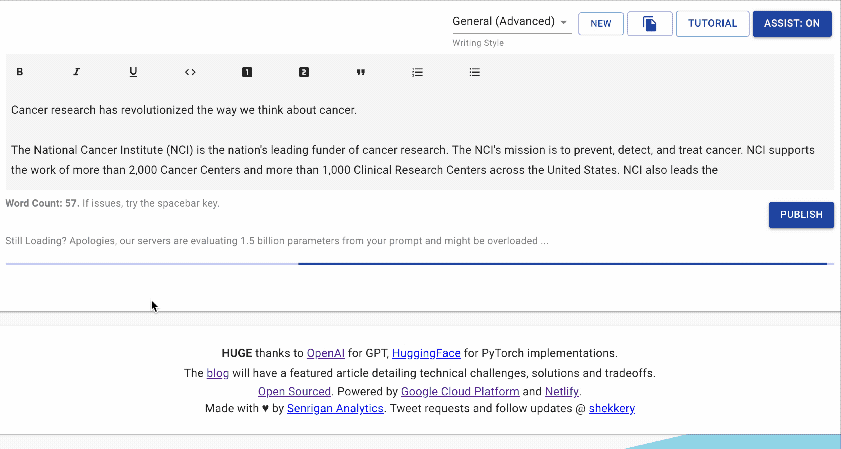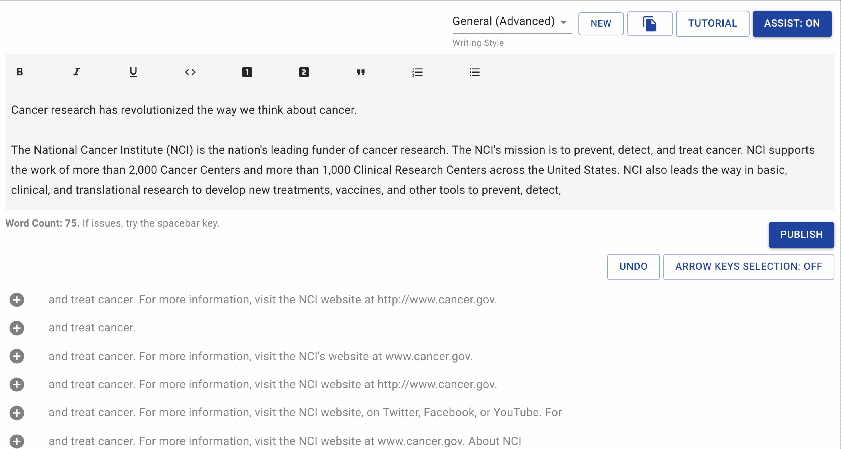
writeup.ai 是一款用于自动写作的开源文本机器人,主要基于 OpenAI 的 GPT-2,同时搭配以下一系列经过调优的模型:
法律法规
文案与声明
歌词
哈利·波特
权力的游戏
学术研究摘要
这一次,我们的主要目标是构建一套能够快速交付 OpenAI GPT-2 Medium(一套用于生成文本的机器学习模型),并同时支持 10 到 20 款面向重度用户的应用程序。
目标概述:
尝试在 NLP(自然语言处理)场景中训练机器学习模型。我借此掌握了大量关于模型部署的知识。
我最初预计整个周期大概为一个月,但最终总计投入三个月时间。
工程难度不易估算——特别是对我这种过度自信的白痴来说~
遗憾的是,我对模型训练了解得不多,所以估算自然更加困难。
需要使用大量开源训练脚本(nsheppard)。我发现 gwern 的GPT2指南特别适用于本篇文章中的场景。另外,我还想向大家推荐 Max 的gpt-2-simple repo,也是份很棒的快速入门资料。
Wrieup.ai 大体开源,我也添加了相关链接以进一步解释自己的尝试中经历的错误/失败。另外,我也添加了指向 GitHub 的代码链接。
链接:
App: writeup.ai
Frontend Repo,GitHub
Backend Repo,GitHub
背景介绍:
我个人曾拥有多年的 React、Django 以及 Flask Web 应用开发经历。
我在机器学习以及 MLOps(机器学习 DevOps)方面是个纯新手,因此请大家以平和的心态看待我的这段旅程~
读者敬启:
你需要拥有一定的 Web 开发背景积累,我也会在文章中主动提供链接以帮助大家理解相关术语。
最好能掌握一些机器学习方面的基础知识。
备注:
这里我会尽可能简明扼要地进行表述。
文章内会先给出全称,之后使用缩写,例如机器学习(ML)->ML。
在大多数情况下,这里的模型是指机器学习模型,因此不再写成“ML 模型”的形式。
供应链锁定确实是个问题。我非常喜欢 Google Cloud Platform(GCP),也完全不打算改旗易帜,因此本文中的某些建议也以使用 GCP 为前提。
根据以往使用 AWS 的体验来看,GCP 上的 ML 资源部署与扩展体验都要好一些。
欢迎大家通过邮件、推文以及评论等方式与我交流。
技术架构:
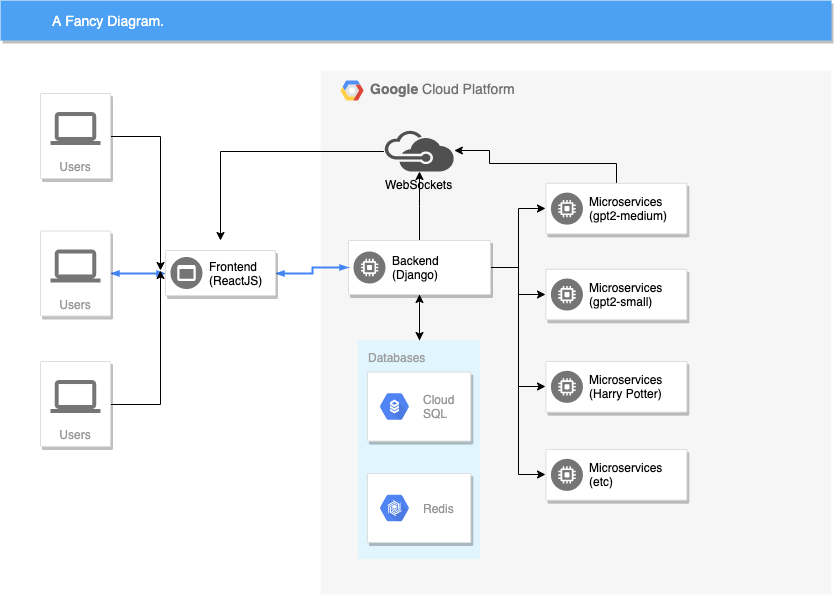
前端(ReactJS)加入后端(Django)中的 WebSocket,并通过 WebSocket 实现与后端的通信。 前端代码 | 后端代码
后端对前端请求进行解析与序列化,并将消息(文本、算法、设置等)打包并通过 WebSocket 通道发送至 Google Load Balancer。 后端代码
负载均衡器中继至适当的微服务(small、medium、large、哈利·波特、法律法规等)。
微服务会定期使用建议的词汇对 Websocket 进行实时更新,从而产生“流”效果。
前端从微服务处接收更新后的 WebSocket 消息。
各个 ML 模型(small、medium、large、哈利·波特、法律法规、学术研究等)都属于独立的微服务,并根据使用情况进行自动规模伸缩。
我尝试了无数次迭代以提高速度水平。
一般来讲,我不太喜欢微服务架构(因为会增加额外的复杂性)。但必须承认,虽然为此付出了大量精力,但微服务架构确实在性能提升方面发挥着不可替代的作用。
微服务的请求与计算成本,同传统的后端服务器存在巨大差别。传统的 Web 服务器能够轻松实现每秒 500 至 5000 条请求;但在运行 1gb 模型的实例当中,每秒 50 项请求(每项生成 50 到 100 个单词)的负载就足以让设备崩溃。(*)
后端与微服务采用 Python 3.6 编写,并使用 Django(DRF)支持后端。在微服务架构中,我使用不同的 Django 版本支持各独立实例。
所有微服务实例均附带有 GPU 或者 Cascade Lake CPU 用以运行 ML 模型。后文将具体阐述。
后端与微服务托管在 Google Cloud Platform 之上。
Google Load Balancer 负责将所有流量路由至微服务。该负载均衡器基于“/gpt2-medium, /gtp2-medium-hp”等 URL 后缀,同时亦可运行健康状态检查以识别 CUDA 崩溃问题。
(*) - 最简单的判断方法:如果你需要刻意证明自己的用例适合微服务架构,则往往代表其没必要使用微服务方法。
在秘鲁利马的三周:
我在秘鲁利马度过了三周假期,但主要内容仍然是认真编码,行程只是作为工作之余的调剂。
在旅程快结束时,几位好友帮我进行了 beta 测试。结果嘛……又慢又容易报错。
旅程当中,我把 80%的时间花在了在共享办公场地里编码身上。
我用了两周时间处理后端与 DevOps,最后一周弄前端。
随着复杂度的提升,我后来又重写了 DevOps。
在旅行结束时,前端已经能够通过 POST 请求与中继至微服务架构的后端进行通信。
速度不好,质量也不高,但在看到第一消息顺利完成从前端到后端,再到微服务的端到端传播之后,我仍然感到激动万分!

MVP 版本
在利马期间完成的工作:
一套规模合理的前端。其拥有一款简单的文本编辑器,以及可通过微服务填充的决策选项。
后端可以创建 WebSocket 以建立与前端的通信。在第一次迭代中,后端原本通过 POST 请求与微服务通信,而后将消息中继至 WebSocket。我当时特别希望让微服务简单一点,不要涉及 WebSocket。
通过 Ansible 进行自动部署(后来被重构/迁移至 Google Startup 脚本当中)。
错误:启动过早! 事后来看,我应该在构建 4 到 5 周之后再进行启动。毕竟到那时候,这才是一套真正能够正常工作的 MVP。但我太紧张了,怕这东西折腾半天没个结果,有点讽刺~

随拍:凌晨两点加上空荡荡的共享办公场所,在这个神奇的地方,一切皆有可能。
90/90 原则:
代码中前 90%的部分占据总体开发周期的 90%。但余下 10%的代码部分将占用同样长度的开发周期。——贝尔实验室 Tom Cargill
工程师们不擅长估算项目周期。
严重低估了机器学习 DevOps(也有人将其称为「MLOps」)的难度。
我也低估了特征渐变的管理难度。
我发现在 Docker 容器上运行微服务,以及扩展并安装能够与模型相匹配的 CUDA 驱动程序非常困难,远超预期。
为了让这套机器学习微服务架构在 Docker 容器上正常运行,我不得不:
使用一套已经安装有 CUDA 的定制化 TensorFlow 启动镜像。
向谷歌方面递交了一份特别申请以安装 nvidia-drivers(特殊情况,并不代表所有特定镜像)。
在 GCP 实例上安装 Docker。
利用 nvidia 覆盖 docker 默认运行时(以降低 docker 与 docker-compose 的使用难度)。
确保 docker 不会删除我的配置变更或者还原配置。
对 GitHub 与 GCP 进行同步;根据 push 内容构建 Docker 镜像。
对 Google Cloud Storage 与 ML 模型进行同步。我发现指向 GCP 存储与实例的读取速度非常快。
从 Google Cloud Build 处 pull 预构建完成的 Docker 镜像。
从云存储桶处 pull ML 模型,同时在 Docker 中挂载不同的独立文件夹。
祈祷所有要求(TensorFlow/PyTorch)都能正常安装。
保存磁盘镜像/快照,以便实例能够利用镜像快速冷启动。
其他传统 DevOps 工作(git、监控、启动 docker 容器等等)。
现在回想起来,这些工作都可以通过更简单的方式实现;但当时我有点手忙脚乱,所以没有规划好时间。
以上提到的步骤都需要完全自动化,否则无法正常扩展。都 2019 年了,在自动化部署流程中手动编写 bash 脚本确实挺傻的,但不这样就没法使用谷歌 startup-scripts 的自动规模伸缩功能。Kubernetes 当然也能完成任务,但我智商不够,用不明白 K8s~谷歌 strtup-scripts 会在机器启动时运行一个 shell 脚本,。另外,我发现在这种实例需要自动规模伸缩的情况下,很难使用 Ansible。
提示: 一定要用startup-script-url! 它能通知实例利用自定义的存储桶 URL 运行脚本。这种方式比将脚本复制/粘贴至 GCP 的 CLI/UI 中更好。当然,大家还需要对启动脚本进行不少小幅修改。
设置后端非常简单。这是我第一次使用 Django Channels,基本思路就是为 Django-Channels 配置 WebSockets 属性。
由于特征在不断变化,因此前端耗费了我不少时间。我一直在添加一个又一个特征,希望尽可能改善实际效果。
我的微服务架构最早是用 Flask 编写(也是听了大家的建议)。但后来我观察了一下基准测试,并发现完全可以使用 django-rest-framework 获得相同的性能。对我来说,把所有内容都保存在 django-rest-fraemwork 当中要轻松得多(毕竟我对 Django 更熟悉)。
微服务的优化需要不少时间。我试过好几款不同的显卡、CPU、内存以及镜像配置,这一点稍后再说。
令人震惊的事实:
直到两个月之前,TensorFlow 镜像中默认使用的仍然是 Python 2.7 版本。
PyTorch 的 docker 镜像使用 conda。
必须覆盖之后,才能在 Docker 上使用 nvidia 运行时。
ML 开源代码示例很多,大家可以根据需要随意添加使用。
谷歌的 TensorFlow Docker 镜像优化效果超好,甚至能让 PyTorch 获得比官方镜像更快的运行速度。这可能是因为上游 PyTorch 镜像当中存在 bug,我也不太清楚。
从 Docker 容器(TensorFlow/PyTorch)处 pull 来的 builds 可能用不了,主要原因就是 ML 发展速度太快了,大家习惯就好。
提示 1:尽量不要手动安装 CUDA。使用预先安装完成的谷歌引导镜像才是正确选择。
提示 2:请务必记录好 CUDA 版本/其他配置。这能确保谷歌云与你的 CUDA 版本及其他要求良好匹配。我遇到过不少由于 CUDA 版本以及框架版本冲突引发的 bug,大家需要尽量避免。
总结:在了解了配置的运作方式之后(包括引导镜像、Docker 镜像、Docker 配置以及 CUDA),剩下的工作就简单多了。可惜有很多问题我是遇上之后才知道的……
推理与其他专业术语解释
ML 社区传代使用大量令人望而生畏的技术术语。我用了几个月时间学习数学,之后情况才有所好转。

总体来讲,我非常佩服那些数学水平高超的人,同时也深深为自己的愚钝感到惭愧……
提示:这当然是一份戏谑性质的术语表啦,实际上机器学习领域有着诸多新表达/专业术语。我建议大家创建并更新一套你自己的术语表。
推理分析:GPU 相关术语解释
在 Web 上运行机器学习模型时,大家只有两种硬件选项:GPU(显卡)或者 CPU。
优势:GPU 速度更快,性能一般可达 CPU 的 5 到 10 倍。缺点:成本更高,会增加部署复杂度。
很多机器学习任务只需要花费大约一秒钟时间(例如图像分类)。这些任务比较适用于 CPU。
大部分用户并不会注意到异步任务当中 0.05 秒与 0.5 秒之间的运行时间差别。你的见面应该快速加载,但对任务结果则可以采用懒加载方式。
在 CPU 上运行 gpt-2 medium 模型(1.2 至 1.5 GB)速度较慢。CPU 平均每秒只能生成 3 到 7 个单词,非常影响使用体验。
Google Cloud 上提供的选项包括 Cascade Lake(最新一代至强 CPU,针对机器学习进行了优化)、K80、V100 以及 P100。
这些基准并非科学基准,而更像是那种写在餐巾纸上的快速排序小心得……总之仅供参考。
(1) - 这一结果来自运行多个 PyTorch 实例的场景。之所以这样做,是为了消除 CPU/GPU 之间的运行阻塞问题。例如,在能够消除 CPU/GPU 阻塞的前提下,在同一台安装有 GPU 的设备上,双 PyTorch 实例的单词生成量可达单一 PyTorch 实例的 1.5 倍。使用单一 PyTorch 应用的运行实例可能每秒会产生 15 个单词,但在双 PyTorch 应用程序场景下其可能每秒各生成 10 个单词。
(2) - 这里我出现了重大失误,我没有安装最新的 MKL-DNN 驱动程序。我不清楚影响大不大,大家可能会在实际测试中获得显著的性能提升,也可能没啥变化。
随着文本输入量的增加,内存容量越大效果越好。
就单周期成本来看,Cascade Lakes 与 GPU 具有相同的成本效益。根据我的感觉,Cascade Lakes 的实际使用体验只略低于“足够快”——换言之,Cascade Lakes 生成单词的速度没有我想象的快。
我发现,当一次性生成的单词数量低于 50 个时,K80 与 P100 的使用体验基本相当。
除了 GPT-2 Large 之外,我最终决定主要使用 Cascade Lakes 与 K80。成本嘛,成本是个大问题。
提示 1:大家可以为大部分负载选取抢占式运行,成本将直接缩减至二分之一。除了产品发布阶段,其余时段我都会选择抢占式运行。
提示 2:如果使用抢占式方法,则谷歌会每 24 小时强制实例进行一次重启。请在凌晨 2 点创建实例,从而尽可能降低对访问者的影响。
提示 3:Cascade Lakes 绝对是最好的权衡选项。
注意:这些“基准”结果仅适用于推理(即实时运行模型)。大部分训练任务都在 GPU 上完成。
Thomson 的望远镜加工新手原则
“先做四英寸镜,再做六英寸镜,速度要快于单做一块六英寸镜。”——Programming Pearls, Communications of the ACM,1985 年 9 月
先从简单的部分开始:API 端点从 gpt2-medium 处生成单词。别着急,先从任务同步、Flask 使用以及单端点场景开始。
添加前端。需要查询 API 端点。别着急,重复请求可能会导致 API 崩溃。
为 API 端点添加作为网守的后端。
将 Flask 端点重写为 Django-DRF 形式。
在后端当中集成 django-channels 以处理 WebSockets。添加 redis-cache 以检查重复请求,而后再将请求转发至微服务架构。
变更前端以通过 WebSockets 进行通信。
重写来自 Ansible 的部署脚本,以符合 Google Cloud 的启动脚本范式。
整合微服务以通过 WebSockes 进行通信,即允许“流传输”。
训练并添加更多微服务(small、medium、large、法律法规、写作、哈利·波特、歌词、企业、xlnet 等)。
从简单端点起步,逐渐提高复杂程度。
优势:在经历以上流程之后,我个人在 ML 部署方面获得了全方位的提升。
缺点:与 GCP 核心产品(特别是存储、云构建、自动规模伸缩以及镜像)紧密耦合。无论是从技术层面还是策略层面来看,与单一服务供应商紧密耦合都不是件好事。
提示:如果与 GCP 产品紧密耦合,则可加快构建速度。在使用 startup-scripts 之后,一切操作都简单了很多。
总结:如果我一开始就意识到最终架构有多么复杂(我本人对 DevOps 确实所知甚少),那我可能直接就被吓倒了。由于缺少充足的计划,我根本不清楚自己将会面临怎样的风险。在所有错误当中,最值得反省的就是:我本应该先利用一套简单的架构进行应用程序构建,而后逐步提高复杂度并进行重构——这能让我少走很多弯路。
部署难题汇总
注意:GCP 与 Docker 都具有镜像概念。为了避免混淆,我在文章中将 GCP 镜像全部称呼为引导镜像。
一般来说,使用 Docker 容器有助于简化部署、服务配置以及代码可重复性。
但在机器学习中使用 Docker 相当困难,具体问题包括:
镜像往往变得出奇的大。官方 TensorFlow Docker 镜像往往高达 500 mb 甚至 1.5 gb。
大部分 GCP 机器学习引导镜像并不包含 Docker/Compose。
大部分包含 Docker 的引导镜像不提供 CUDA。
如果各位够胆从零开始安装 TensorFlow 与 CUDA,请受我一拜~
最好的办法是找一套相对符合要求的启动镜像,然后从二者中选择安装难度相对较低的一种(CUDA 或者 Docker)。在大多数情况下,Docker 加相关工具的安装难度,要略低于 CUDA。
大部分模型的体积都超过 1 gb,超出源代码控制范围。我们需要在启动/部署时配合能够实现大型模型同步的脚本。
经常忘记使用命令把 nvidia 运行时导入 Docker。
DevOps 中的反馈循环比传统编程慢得多。单单是发现错误并做出修改这个流程,就能轻松耗掉 10 来分钟。如果使用谷歌的滚动部署,那周期还会更长。
优势:一旦容器设置完成,其运行健壮性还是相当靠谱的。
缺点:Docker 会令部署变得更为复杂。合理的意见:既然如此,为什么不引入 Kubernetes?回答是,我脑子不行,用不明白 Kubernetes。
提示 1:一定要谨慎,确保将正在运行的每一条 shell 命令都添加到 Quiver 日志(或者其他记录机制)当中。我们可能需要多次复制并粘贴命令,而后自动执行其中大部分操作。如果单靠脑袋硬记命令顺序,那么整个流程将很难实现自动化。
提示 2:以绝对路径的形式运行/保存各项命令,以避免覆盖错误的目录。例如"rsync /path1 /path2"是正确的,"rsync path1 path2"是错误的……真的很容易出问题。
提示 3:如果你熟悉 Ansible,可以利用 Ansible 在目录上重新运行谷歌 startup-scripts,其速度要远高于 GCP rolling-deploys。
提示 4:其他一些耗时的工作
哪些模型应该保存在哪个存储桶中。建议大家明确区分哪些云存储桶用于训练,哪些用于生产。
明确实例中的存储桶/目录应如何同步。
如果可能,请让实例与 docker 容器的安装目录处于同一位置。例如实例的/models 应对应 docker 容器的/models 路径。
将正确的 rsync 命令写入存储桶。再次强调,一定要使用 rsync(而非 cp)!在效率方面,重新启动要比通过 cp 提取同一文件高得多。
提示 5:对 PyTorch (torch.cuda.is_available) 或者 TensorFlow (tf.test.is_gpu_available)进行快速自动检查,可以省去每次启动后确保 Docker 使用 nvidia 的麻烦。
总结:在这方面,很多 Web 工程师可能都会像我这样,在部署训练完成的 ML 应用程序时遇到困难。
发现瓶颈——显存不足问题
对传统 Web 服务器的负载进行监控一般比较简单。所有 GCP 页面都会列出 CPU 的使用率百分比。在内存方面,命令开头就会快速提示当前程序正在仅代表和多少内存。谷歌的 StackDriver 能够将内存使用量自动转发至 Google Cloud。
DevOps 长期以来一直关注对 CPU、内存、磁盘以及网络资源使用量的监控。
但是,超频达人肯定更关注 GPU。自从 AlexNet 诞生以来(或者说社区学会利用 GPU 处理 ML 负载以来),一直没有靠谱的生产级 GPU 监控工具。
要正确监控 GPU 使用情况,我们必须使用 nvidia-smi,设定隔多久输出一次监控结果,编写脚本以供 Prometheus 读取,而后将结果传递给 StackDriver。简而言之,大家需要编写一项专门的微服务来监控其他微服务。
使用期间,CPU 与 GPU 的使用率均呈线性上升。在测试中,我发现极少数 vCPU 利用率坐飙升至 80%至 100%,而系统只会根据 CPU 使用率进行自动规模伸缩。另外,即使添加再多的 vCPU 以及 CPU,也无法缓解 GPU 的高利用率状况。
GPU 显存不足时可能引发问题。当用户传递较长的提示符(大于 200 个单词)时,PyTorch 会发生异常,其中包含大量显存泄漏情况。为了解决这个问题,我跟踪了 PyTorch 异常并强制释放了未使用的显存。之所以 nvidia-smi 未能起效,是因为显存使用统计信息为非实时且不够精确(IIRC 只显示某一进程的峰值内存使用情况)。
训练模型
我在 gpt2-medium 的 P100 上对其他模型进行了调优。训练迭代(周期)的范围从权力的游戏(GoT)与哈利·波特(HP)的 6 万次……到学术研究(20 万份论文摘要)的 60 万次。
使用 TensorFlow 1.13 进行训练。
训练时间从几小时(6 万轮)到数天(60 万轮)不等。
交叉熵损失介于 2 到 3 之间。过度训练后指标失效。
对 nsheppard 的 gpt2 repo 进行分叉,通过少量修改以加快大型数据集的启动速度。
在掌握了 ML 术语之后,,大家就可以按照 gwern 的教程进行操作(虽然还是相当困难)。
使用梯度检查点来处理显存问题。在未发生显存问题的单一 GPU 上无法调整 gpt2-large(7.74 亿个参数,1.5 gb)。
数据集范围的查找与清洁工作难度不算太高,但相当枯燥乏味。
再次强调,数据清洁工作约占整体工作量的 80%。
从 Kaggle 以及谷歌等处获取数据集。在清洁过程中,最耗时的工作包括数据集异常、处理换行符(\r、\n\以及回车等)、unicode 检测与语言检测等。
Gwern 使用大量 bash/命令行清洁他使用的莎士比亚语料库。我建议大家使用 Python,这样更易于在不同数据集上实现代码复用。
无法在 Docker 当中正确进行 16 位训练(apex)。英伟达基准(存在一定营销成分)显示,16 位模式可以将训练周期缩短至二分之一(甚至更低)。我没能成功,也不打算在这方面投入过多精力。
在训练完成后,利用 huggingface 脚本将模型转换为 PyTorch 形式。好在 pytorch-transformers 的部署过程非常简单。
我本来希望避免对哈利·波特语料库进行过度训练,但事后看来,过度训练还是要比训练不足好些。在对小型数据集进行过度训练/训练不足平衡时,得到的结果可能有所不同。
提示 1:在准备好原始训练数据集后,请记得复制一份。千万不要修改原始数据集。将修改后的输出结果复制到单独的文件夹中。另外,修改后的数据集与原始数据集一定要存放在独立的文件夹内,以免发生错误/混淆。
提示 2:如果大家发现自己需要一段时间专门清洁特定的数据集,先别急着动手,不妨找找有没有类似的可用数据集。这里说的就是哈利·波特数据集!
提示 3:一定要试试 tmux!使用 tmux,我们可以轻松在远程设备上开始训练,而且完全不用担心意外退出。
提示 4:使用 Quiver 保存所有命令。手动输入真的很容易发生错误。
运行模型
使用 PyTorch。Pytorch-transformers 会为模型创建便捷的 API 调用站点,类似于 huggingface 中的 run_gpt2.py 示例。接下来进行大规模重构。
在 PyTorch 加载 GPT-2 模型速度很难(大约需要 1 到 2 分钟)。
为了缩短加载时间,在微服务启动时,WSGI 会加载适当的模型(gpt2-small、medium、large 等)并将 PyTorch 实例存储为一个单项。
这一条是专门答复网友发来的,关于如何提高响应速度的邮件。
所有后续请求都使用单项 PyTorch 实例。
根据模型大小对配置中的 WSGI 进程运行数量做出限制。WSGI 进程数量过多会导致显存不足,太少则会导致 GPU 利用率过低。
当 PyTorch 显存不足以捕捉异常;释放显存泄漏。
95%的请求时间用于预测对数。其他时间则用于进行前端->后端->负载均衡器路由以及反序列化。
每生成五个单词,微服务都会利用更新文本对 WebSocket 进行更新。
向后端添加缓存以应对重复请求。
为了简化来自不同实例的相同响应,我为全部请求设定了 seed。
其他部署改进、蒸馏与思路
TensorFlow 提供 TensorFlow Serve,PyTorch 也提供 TorchScript,可用于将模型转换为生产级水平。其收益包括合理的速度改进(redditor 引用提高了 30%),以及在无 Python 设备上轻松部署等。我对某些模型上的 PyTorch 转换过程进行了跟踪,但发现速度优势并不太明显,反而引入了不少复杂性因素。
过去几个月以来,模型蒸馏(在大小与运行时降低一半的前提下,保持 90%到 95%的准确率)引起了人们的关注。Huggingface 对 gpt2-small 进行蒸馏后,体积减少了 33%,而速度则提升到 2 倍。
最近一篇关于极限语言模型压缩的论文,将 BERT 压缩了 60 倍!如果能够将其应用于 GPT2,相信将具有巨大的现实意义。
虽然存在一些反模式,但 PyTorch 与 TensorFlow 确实拥有非常出色的效果,使我能够更快地诊断问题并尝试潜在的解决方案。
我最初集成了 XLNet,但却得不到与 GPT2 一样强大的生成输出结果。我也尝试过让它提供单一词汇建议(类似于掩盖语言模型),但找不到能够与之匹配的合适写作用例/UI。
其他重要发现
有时候需要重复之前提到的步骤。
Sentry 拥有强大的错误报告能力。但在配合 ASGI(Django-Channels)时,其使用难度会有所提升。
tmux——利用它保持远程会话开启。另一种办法嘛,当然就是一直盯着屏幕呗。
django-rest-framework 的使用感受很棒,感觉就像是作弊码。
Netlify 非常适合部署。
工作中的倦怠情绪

如何克服自己的心态波动……
用头撞墙,发泄情绪~
在大概 2 个月到 2 个半月时,逐渐陷入倦怠状态。
感觉非常纠结,认为应该尽快启动,但又怕启动结果不好。强迫症般地认为自己错过了某些重要特征。
跟好朋友的交流能极大缓解自己的紧张情绪(感觉 James C 的开导)。
自我施压过度。在此期间,我很少给家人打电话,事实证明这是个错误的决定。后来,我发现哪怕只是跟妈妈聊聊家常,都能很好地帮自己平复心态。
终于完成了,我感到相当自豪。无论是否有意,我还是在过程中学到了很多关于 ML 部署的知识,相信它们将在下一个项目中为我提供助力。
鸣谢
感谢 OpenAI 的 GPT2 以及 HuggingFace 的 pytorch-transformers。
感谢 GCP 积分机制,否则我真的租不起这么多实例。可能有个人喜好的影响,份量我觉得 GCP 在整体指标(包括存储桶、网络以及易用性)方面比 AWS 更好。
帮助我进行 beta 测试并提供宝贵反馈的好友。感谢 Christine Li、James Stewart、Kate Aksay、Zoltan Szalas、Steffan Linssen 以及 Harini Babu——排名当然不分先后!
也要感谢各位 Redditor/ProductHunt 用户做出的贡献,感谢大家的反馈以及整理出的重要写作提示。
原文链接:
https://senrigan.io/blog/how-writeupai-runs-behind-the-scenes/
公众号推荐:
2024 年 1 月,InfoQ 研究中心重磅发布《大语言模型综合能力测评报告 2024》,揭示了 10 个大模型在语义理解、文学创作、知识问答等领域的卓越表现。ChatGPT-4、文心一言等领先模型在编程、逻辑推理等方面展现出惊人的进步,预示着大模型将在 2024 年迎来更广泛的应用和创新。关注公众号「AI 前线」,回复「大模型报告」免费获取电子版研究报告。


InfoQ主编

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论