

简介
TensorFlow 是 Google 研发的第二代人工智能学习系统,能够处理多种深度学习算法模型,以功能强大和高可扩展性而著称。TensorFlow 完全开源,所以很多公司都在使用,但是美团点评在使用分布式 TensorFlow 训练 WDL 模型时,发现训练速度很慢,难以满足业务需求。
经过对 TensorFlow 框架和 Hadoop 的分析定位,发现在数据输入、集群网络和计算内存分配等层面出现性能瓶颈。主要原因包括 TensorFlow 数据输入接口效率低、PS/Worker 算子分配策略不佳以及 Hadoop 参数配置不合理。我们在调整对 TensorFlow 接口调用、并且优化系统配置后,WDL 模型训练性能提高了 10 倍,分布式线性加速可达 32 个 Worker,基本满足了美团点评广告和推荐等业务的需求。
术语
TensorFlow - Google 发布的开源深度学习框架
OP - Operation 缩写,TensorFlow 算子
PS - Parameter Server 参数服务器
WDL - Wide & Deep Learning,Google 发布的用于推荐场景的深度学习算法模型
AFO - AI Framework on YARN 的简称 - 基于 YARN 开发的深度学习调度框架,支持 TensorFlow,MXNet 等深度学习框架
TensorFlow 分布式架构简介
为了解决海量参数的模型计算和参数更新问题,TensorFlow 支持分布式计算。和其他深度学习框架的做法类似,分布式 TensorFlow 也引入了参数服务器(Parameter Server,PS),用于保存和更新训练参数,而模型训练放在 Worker 节点完成。
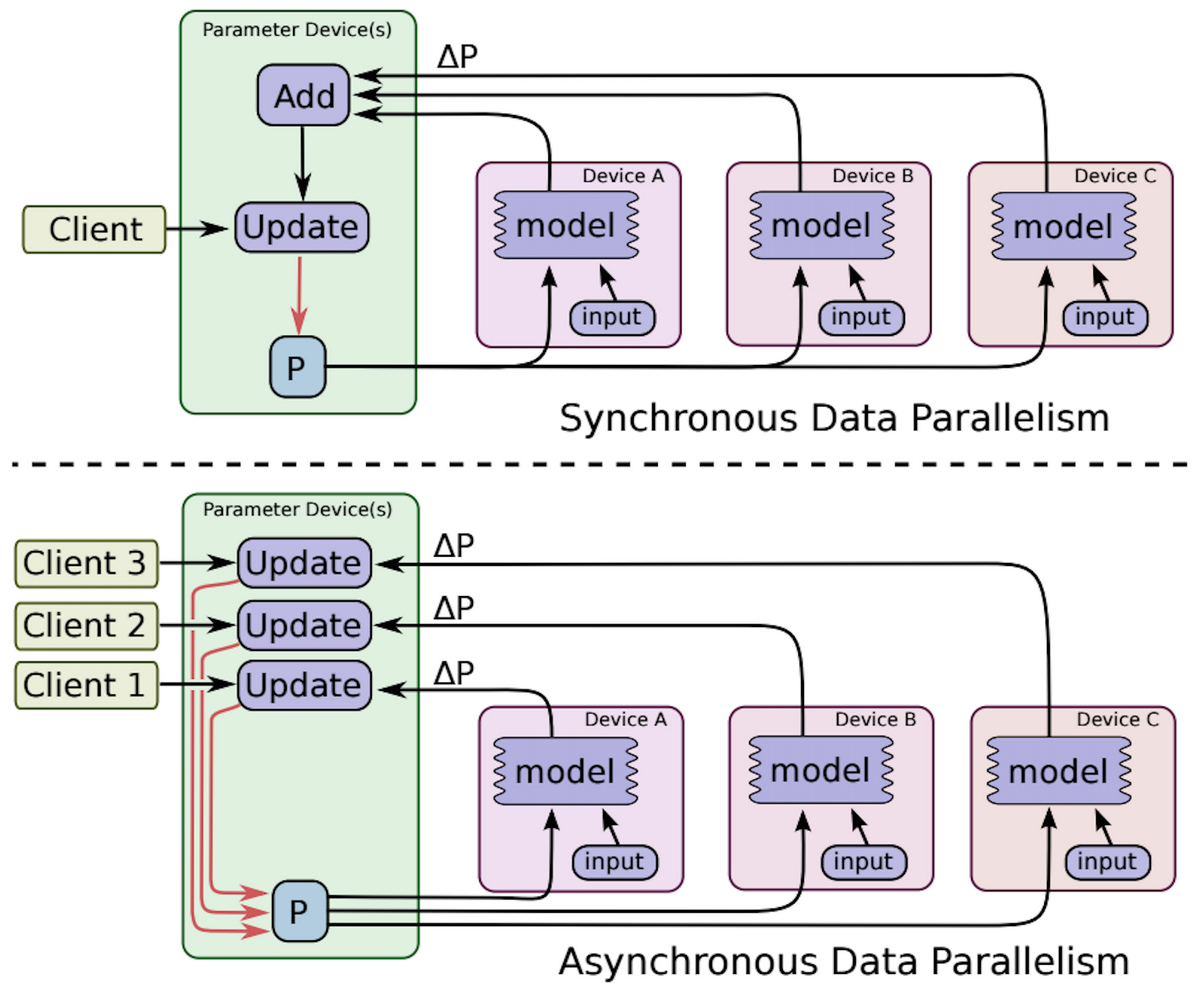
TensorFlow 分布式架构
TensorFlow 支持图并行(in-graph)和数据并行(between-graph)模式,也支持同步更新和异步更新。因为 in-graph 只在一个节点输入并分发数据,严重影响并行训练速度,实际生产环境中一般使用 between-graph。
同步更新时,需要一个 Woker 节点为 Chief,来控制所有的 Worker 是否进入下一轮迭代,并且负责输出 checkpoint。异步更新时所有 Worker 都是对等的,迭代过程不受同步 barrier 控制,训练过程更快。
AFO 架构设计
TensorFlow 只是一个计算框架,没有集群资源管理和调度的功能,分布式训练也欠缺集群容错方面的能力。为了解决这些问题,我们在 YARN 基础上自研了 AFO 框架解决这个问题。
AFO 架构特点:
高可扩展,PS、Worker 都是任务(Task),角色可配置
基于状态机的容错设计
提供了日志服务和 Tensorboard 服务,方便用户定位问题和模型调试
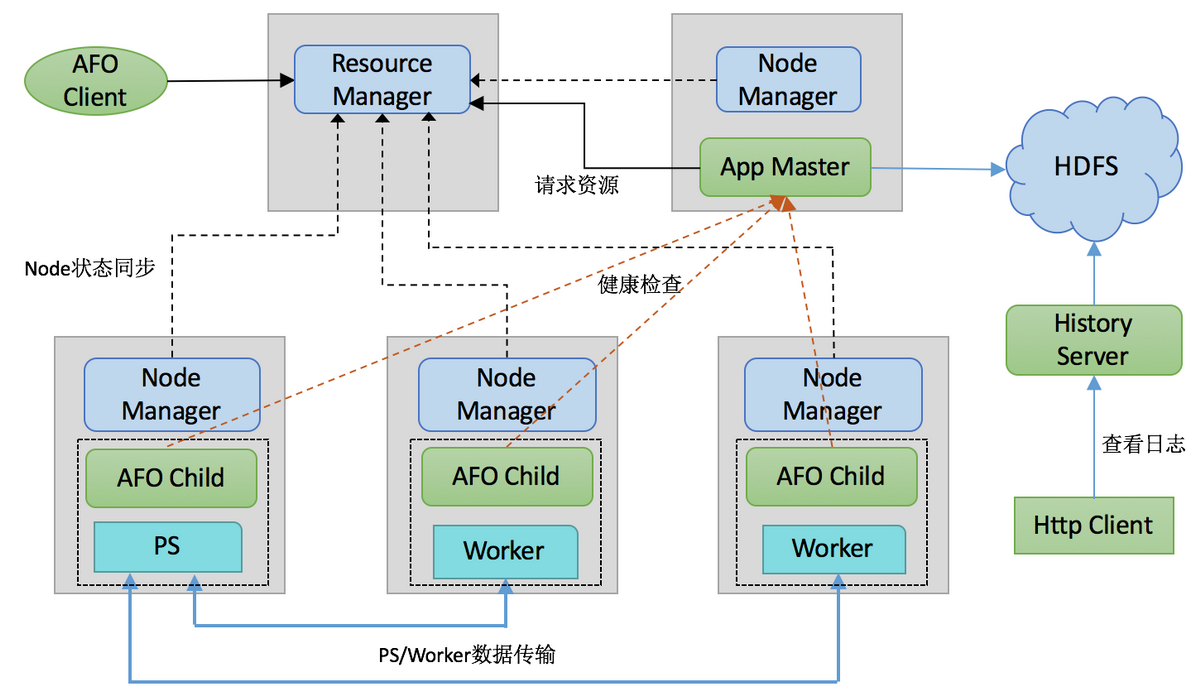
AFO 架构
AFO 模块说明:
Application Master:用来管理整个 TensorFlow 集群的资源申请,对任务进行状态监控
AFO Child:TensorFlow 执行引擎,负责 PS、Worker 运行时管理和状态同步
History Server:管理 TensorFlow 训练生成的日志
AFO Client:用户客户端
WDL 模型
在推荐系统、CTR 预估场景中,训练的样本数据一般是查询、用户和上下文信息,系统返回一个排序好的候选列表。推荐系统面临的主要问题是,如何同时可以做到模型的记忆能力和泛化能力,WDL 提出的思想是结合线性模型(Wide,用于记忆)和深度神经网络(Deep,用于泛化)。
以论文中用于 Google Play Store 推荐系统的 WDL 模型为例,该模型输入用户访问应用商店的日志,用户和设备的信息,给应用 App 打分,输出一个用户“感兴趣”App 列表。

WDL 模型网络
其中,installed apps 和 impression apps 这类特征具有稀疏性(在海量大小的 App 空间中,用户感兴趣的只有很少一部分),对应模型“宽的部分”,适合使用线性模型;在模型“深的部分”,稀疏特征由于维度太高不适合神经网络处理,需要 embedding 降维转成稠密特征,再和其他稠密特征串联起来,输入到一个 3 层 ReLU 的深度网络。最后 Wide 和 Deep 的预估结果加权输入给一个 Logistic 损失函数(例如 Sigmoid)。
WDL 模型中包含对稀疏特征的 embedding 计算,在 TensorFlow 中对应的接口是 tf.embedding_lookup_sparse,但该接口所包含的 OP 无法使用 GPU 加速,只能在 CPU 上计算,因此 TensorFlow 在处理稀疏特征性能不佳。不仅如此,我们发现分布式 TensorFlow 在进行 embedding 计算时会引发大量的网络传输流量,严重影响训练性能。
性能瓶颈分析与调优
在使用 TensorFlow 训练 WDL 模型时,我们主要发现 3 个性能问题:
每轮训练时,输入数据环节耗时过多,超过 60%的时间用于读取数据。
训练时产生的网络流量高,占用大量集群网络带宽资源,难以实现分布式性能线性加速。
Hadoop 的默认参数配置导致 glibc malloc 变慢,一个保护 malloc 内存池的内核自旋锁成为性能瓶颈。
TensorFlow 输入数据瓶颈
TensorFlow 支持以流水线(Pipeline)的方式输入训练数据。如下图所示,典型的输入数据流水线包含两个队列:Filename Queue 对一组文件做 shuffle,多个 Reader 线程从此队列中拿到文件名,读取训练数据,再经过 Decode 过程,将数据放入 Example Queue,以备训练线程从中读取数据。Pipeline 这种多线程、多队列的设计可以使训练线程和读数据线程并行。理想情况下,队列 Example Queue 总是充满数据的,训练线程完成一轮训练后可以立即读取下一批的数据。如果 Example Queue 总是处于“饥饿”状态,训练线程将不得不阻塞,等待 Reader 线程将 Example Queue 插入足够的数据。使用 TensorFlow Timeline 工具,可以直观地看到其中的 OP 调用过程。
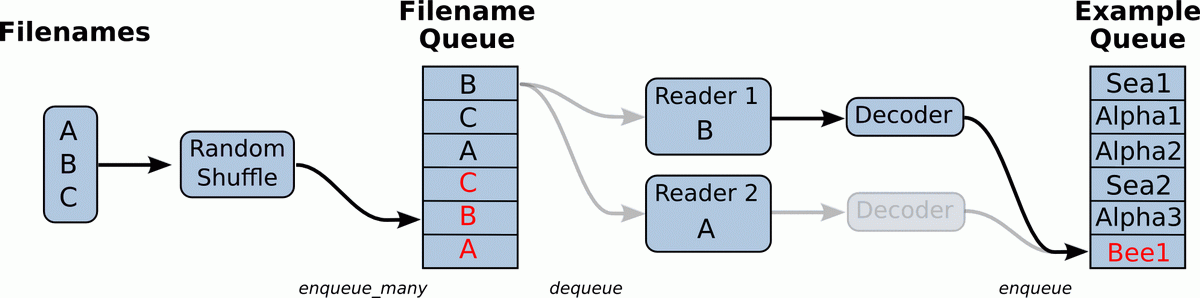
TensorFlow 输入数据流水线
使用 Timeline,需要对 tf.Session.run()增加如下几行代码:
这样训练到 global step 在 1000 轮左右时,会将该轮训练的 Timeline 信息保存到 timeline_01.json 文件中,在 Chrome 浏览器的地址栏中输入 chrome://tracing,然后 load 该文件,可以看到图像化的 Profiling 结果。
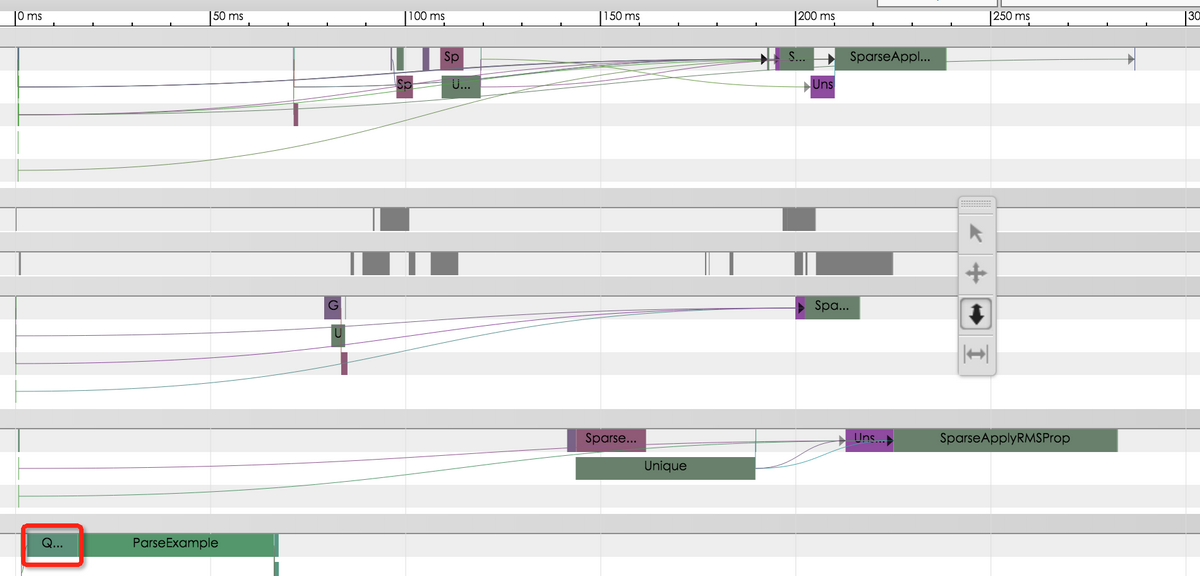
业务模型的 Timeline 如图所示:

Timeline 显示数据输入是性能瓶颈
可以看到 QueueDequeueManyV2 这个 OP 耗时最久,约占整体时延的 60%以上。通过分析 TensorFlow 源码,我们判断有两方面的原因:
(1)Reader 线程是 Python 线程,受制于 Python 的全局解释锁(GIL),Reader 线程在训练时没有获得足够的调度执行;
(2)Reader 默认的接口函数 TFRecordReader.read 函数每次只读入一条数据,如果 Batch Size 比较大,读入一个 Batch 的数据需要频繁调用该接口,系统开销很大;
针对第一个问题,解决办法是使用TensorFlow Dataset接口,该接口不再使用 Python 线程读数据,而是用 C++线程实现,避免了 Python GIL 问题。针对第二个问题,社区提供了批量读数据接口 TFRecordReader.read_up_to,能够指定每次读数据的数量。我们设置每次读入 1000 条数据,使读数句接口被调用的频次从 10000 次降低到 10 次,每轮训练时延降低 2-3 倍。
优化数据输入使性能提升 2-3 倍
可以看到经过调优后,QueueDequeueManyV2 耗时只有十几毫秒,每轮训练时延从原来的 800 多毫秒降低至不到 300 毫秒。
集群网络瓶颈
虽然使用了 Mellanox 的 25G 网卡,但是在 WDL 训练过程中,我们观察到 Worker 上的上行和下行网络流量抖动剧烈,幅度 2-10Gbps,这是由于打满了 PS 网络带宽导致丢包。因为分布式训练参数都是保存和更新都是在 PS 上的,参数过多,加之模型网络较浅,计算很快,很容易形成多个 Worker 打一个 PS 的情况,导致 PS 的网络接口带宽被打满。
在推荐业务的 WDL 模型中,embedding 张量的参数规模是千万级,TensorFlow 的 tf.embedding_lookup_sparse 接口包含了几个 OP,默认是分别摆放在 PS 和 Worker 上的。如图所示,颜色代表设备,embedding lookup 需要在不同设备之前传输整个 embedding 变量,这意味着每轮 Embedding 的迭代更新需要将海量的参数在 PS 和 Worker 之间来回传输。
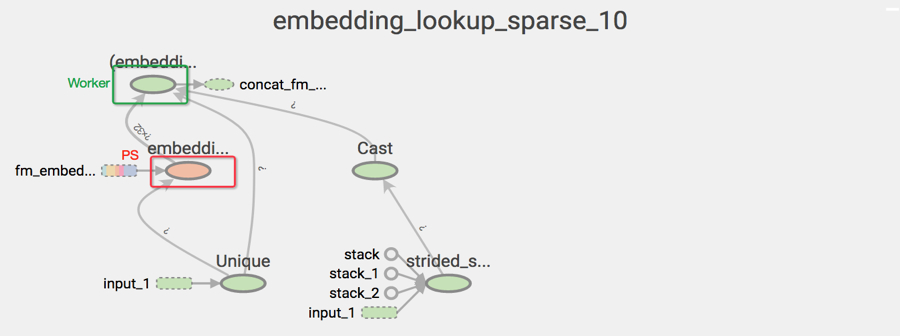
embedding_lookup_sparse 的 OP 拓扑图
有效降低网络流量的方法是尽量让参数更新在一个设备上完成,即
社区提供了一个接口方法正是按照这个思想实现的:embedding_lookup_sparse_with_distributed_aggregation接口,该接口可以将 embedding 计算的所使用的 OP 都放在变量所在的 PS 上,计算后转成稠密张量再传送到 Worker 上继续网络模型的计算。
从下图可以看到,embedding 计算所涉及的 OP 都是在 PS 上,测试 Worker 的上行和下行网络流量也稳定在 2-3Gpbs 这一正常数值。

embedding\_lookup\_sparse\_with\_distributed_aggregation 的 OP 拓扑图
PS 上的 UniqueOP 性能瓶颈
在使用分布式 TensorFlow 跑广告推荐的 WDL 算法时,发现一个奇怪的现象:WDL 算法在 AFO 上的性能只有手动分布式的 1/4。手动分布式是指:不依赖 YARN 调度,用命令行方式在集群上分别启动 PS 和 Worker 作业。
使用 Perf 诊断 PS 进程热点,发现 PS 多线程在竞争一个内核自旋锁,PS 整体上有 30%-50%的 CPU 时间耗在 malloc 的在内核的 spin_lock 上。
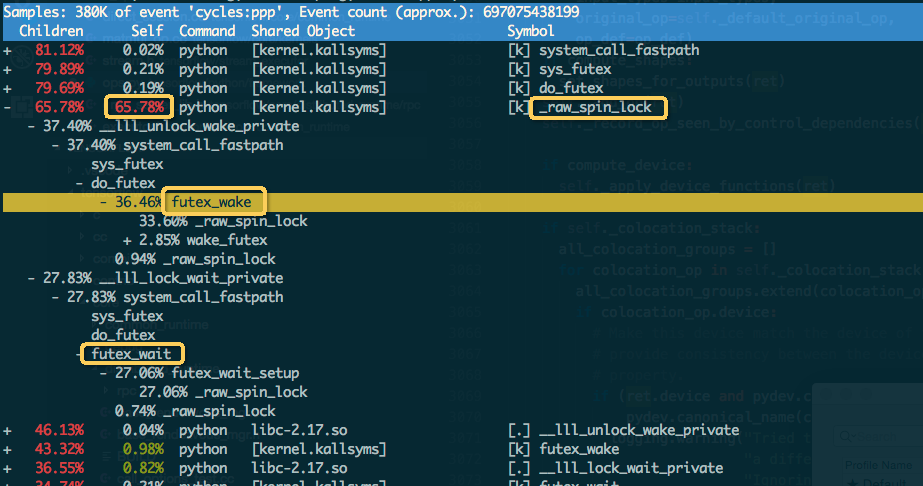
Perf 诊断 PS 计算瓶颈
进一步查看 PS 进程栈,发现竞争内核自旋锁来自于 malloc 相关的系统调用。WDL 的 embedding_lookup_sparse 会使用 UniqueOp 算子,TensorFlow 支持 OP 多线程,UniqueOp 计算时会开多线程,线程执行时会调用 glibc 的 malloc 申请内存。
经测试排查,发现 Hadoop 有一项默认的环境变量配置:
该配置意思是限制进程所能使用的 glibc 内存池个数为 4 个。这意味着当进程开启多线程调用 malloc 时,最多从 4 个内存池中竞争申请,这限制了调用 malloc 的线程并行执行数量最多为 4 个。
翻查 Hadoop 社区相关讨论,当初增加这一配置的主要原因是:glibc 的升级带来多线程 ARENA 的特性,可以提高 malloc 的并发性能,但同时也增加进程的虚拟内存(即 top 结果中的 VIRT)。YARN 管理进程树的虚拟内存和物理内存使用量,超过限制的进程树将被杀死。将 MALLOC_ARENA_MAX 的默认设置改为 4 之后,可以不至于 VIRT 增加很多,而且一般作业性能没有明显影响。
但这个默认配置对于 WDL 深度学习作业影响很大,我们去掉了这个环境配置,malloc 并发性能极大提升。经过测试,WDL 模型的平均训练时间性能减少至原来的 1/4。
调优结果
注意:以下测试都去掉了 Hadoop MALLOC_ARENA_MAX 的默认配置
我们在 AFO 上针对业务的 WDL 模型做了性能调优前后的比对测试,测试环境参数如下:
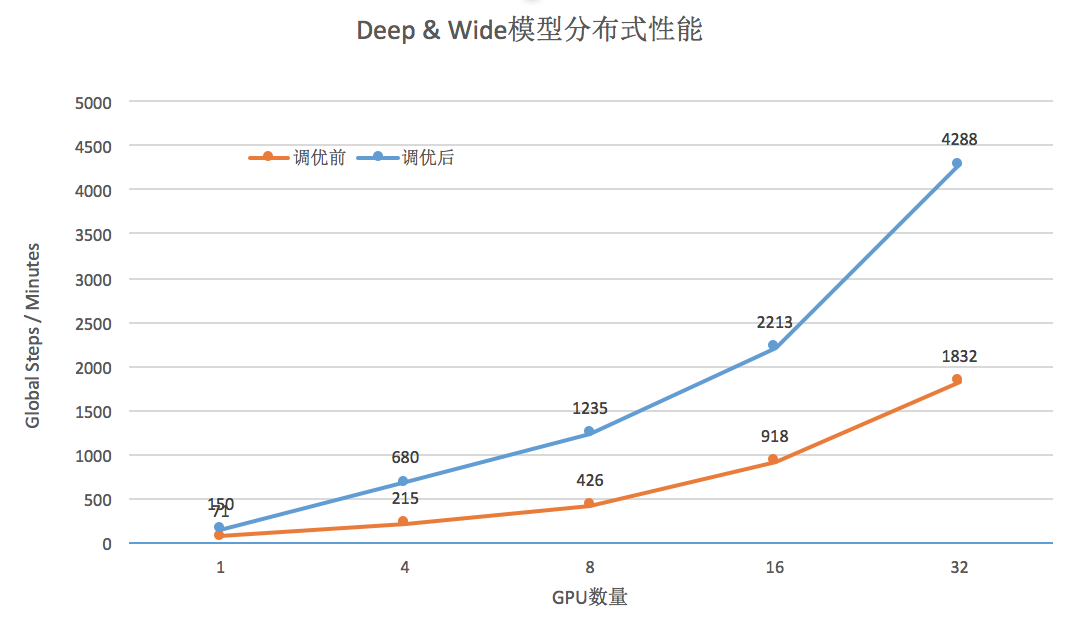
分布式线性加速效果
可以看到调优后,训练性能提高 2-3 倍,性能可以达到 32 个 GPU 线性加速。这意味着如果使用同样的资源,业务训练时间会更快,或者说在一定的性能要求下,资源节省更多。如果考虑优化 MALLOC_ARENA_MAX 的因素,调优后的训练性能提升约为 10 倍左右。
总结
我们使用 TensorFlow 训练 WDL 模型发现一些系统上的性能瓶颈点,通过针对性的调优不仅可以大大加速训练过程,而且可以提高 GPU、带宽等资源的利用率。在深入挖掘系统热点瓶颈的过程中,我们也加深了对业务算法模型、TensorFlow 框架的理解,具有技术储备的意义,有助于我们后续进一步优化深度学习平台性能,更好地为业务提供工程技术支持。
作者简介
郑坤,美团点评技术专家,2015 年加入美团点评,负责深度学习平台、Docker 平台的研发工作。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论