

在本文的第 1 部分,我们为回收利用设施的分类机创建了一个图像分类模型,用来识别四种饮料容器。我们使用新的 AWS IoT Greengrass Image Classification 连接器来将其部署到我们的 AWS IoT Greengrass Core 设备上。借助在今年 re:Invent 大会上发布的 AWS IoT Greengrass 连接器,IoT Greengrass Core 设备无需编写代码即可连接到第三方应用程序、本地软件和 AWS 服务。在第 1 部分末尾,我们注意到我们对饮料包装容器的预测并不总是正确的或始终具有较高置信度。在第 2 部分中,我们将扩展我们的应用程序,上传超出预测置信度阈值的图像,标记这些图像,并重新训练我们的模型,然后再次将其部署到我们的 IoT Greengrass Core 设备。
注意:本博文中的信息在很大程度上依赖第 1 部分的内容。如果您尚未完成第 1 部分中的步骤,请先完成这些步骤,然后再继续。
概览
在本文中,通过在代码中添加一个额外步骤来检查捕获图像的预测置信度,我们将扩展在第 1 部分中创建的饮料包装容器分类器 Lambda 函数。将预测置信度低于最小阈值或高于最大阈值的图像上传至 Amazon S3,在那里我们可以手动标记这些图像,以便在将来的 Amazon SageMaker 模型训练作业中使用。换而言之,我们的 Amazon SageMaker 笔记本将下载这些新标记的图像,将它们与原始 Caltech 256 数据集结合,并创建一个结合新数据和原始数据的新模型。最后,我们将在我们的 IoT Greengrass 组连接器中更新模型并重新部署到 Greengrass Core 设备。
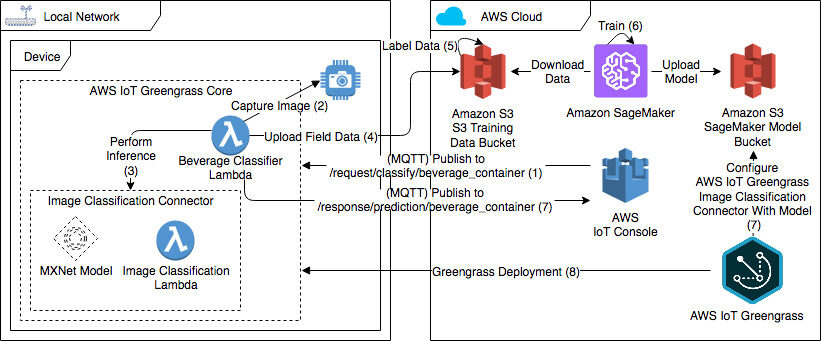
在第 2 部分末尾,我们将得到一个类似于此处所示的架构。您看到的数字用于显示重新训练模型的流程顺序。
先决条件
要从 Lambda 函数访问 Amazon S3,我们将使用适用于Python 的 AWS 开发工具包 (Boto3)。运行以下命令,以将其安装在您的 Raspberry Pi 上:
扩展和测试应用程序
要将我们的图像上传到 S3,我们需要授予 Greengrass Core 设备访问 S3 存储桶的权限。
配置 S3 权限
在 AWS IoT 控制台的组设置页面上,记下组角色中的值。如果尚未为您的组配置角色,请参阅 AWS IoT Greengrass 开发人员指南中的配置 IAM 角色。
要授予组访问 S3 的权限,我们需要使用 IAM 控制台来将 AmazonS3FullAccess 策略添加到其角色中。在 IAM 控制台中,选择角色。查找并选择您为您的 IoT Greengrass 组确定的角色。在摘要页面上,选择附加策略。
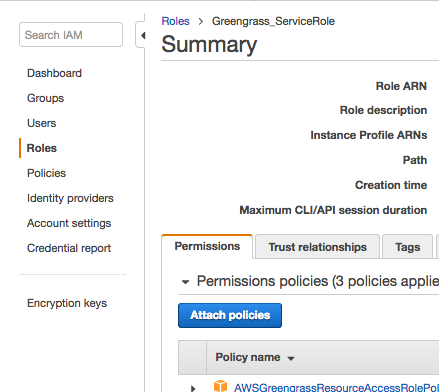
搜索 AmazonS3FullAccess,选中复选框,然后选择附加策略。

部署到您的组。您的组现在将具有对 S3 的读取和写入权限。
有关与其他 AWS 服务交互的信息,请参阅 AWS IoT Greengrass 开发人员指南中的模块 6:访问 AWS 云服务。
扩展饮料包装容器分类器 Lambda 函数
在此步骤中,我们将扩展饮料包装容器分类器 Lambda 函数。新代码与 S3 集成。它提供了有关何时上传要标记并用作新训练数据的图像的逻辑。我们要上传以下图像:
超过高阈值的图像,用作数据以验证我们置信度较低的预测。
低于低阈值的图像,将被标记并合并到我们的数据集中。
使用 GitHub 上发现的代码更新饮料包装容器分类器 Lambda 函数。
创建新部署。
收集字段中的数据
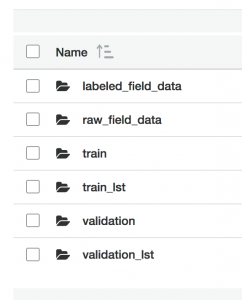
饮料分类器现在可以收集字段中的数据并将其上传到 S3 以进行手动标记。您现在应该可以在 S3 存储桶的 image-classification 文件夹中看到以下内容:
花些时间来使用更新的应用程序。尝试为五个类别中的每一个收集图像。在测试期间,我们为每个类别收集了 50 张额外的图像。我们对每个类别中的各种对象拍摄了不同角度的照片,以捕获大量的测试数据。请记住,您可以通过发布到 /request/classify/beverage_container 主题并订阅 /response/prediction/beverage_container 主题,在 AWS IoT 控制台的测试页面上对图像进行分类和查看结果,就像我们在第 1 部分中做的那样。
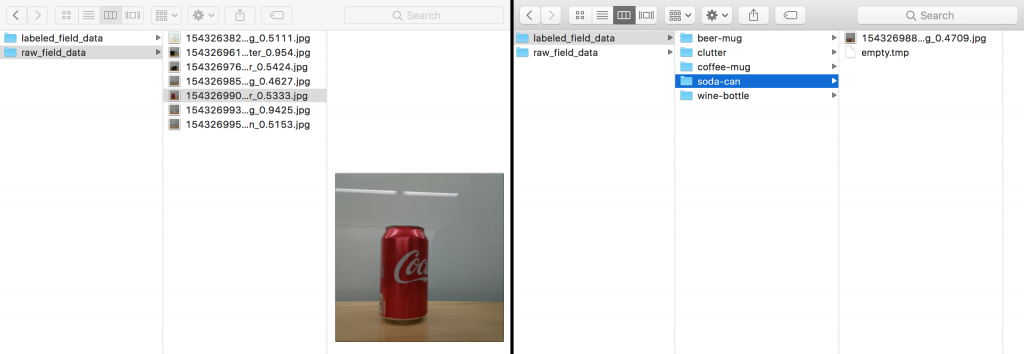
以下是我们捕获到的一些图像:








标记字段数据
要标记数据,我们需要查看 S3 存储桶中 raw_field_data 文件夹中的图像,并将它们移动到 labeled_field_data 文件夹中各自类别的文件夹中。我们建议您使用 AWS CLI 来执行此操作。
将 S3 存储桶同步到桌面上的某个文件夹:
浏览本地 raw_field_data 文件夹中的图像。查看每个图像并将其移动到本地 labeled_field_data 文件夹中各自的文件夹:
标记后,运行以下命令以更新 S3。此操作会将未标记的图像移动到正确标记的文件夹中。
重新训练您的模型
我们现在得到了可用于重新训练我们模型的新标记数据。返回到我们在第 1 部分中使用的 Amazon SageMaker 笔记本(从此处的笔记本复制)。按照笔记本中的步骤操作,到达最后时返回此处。
注意:您可以在添加训练数据时重新运行笔记本的第 2 部分。这样做会创建一个可以部署到您的 Greengrass Core 设备的新模型。
重新部署您的模型
我们现在拥有一个可以部署的经过重新训练的模型。返回您的 IoT Greengrass 组并编辑您在第 1 部分中创建的机器学习资源。在 Amazon SageMaker 训练作业的下拉菜单中,选择新的训练作业。选择保存,然后创建部署。部署完成后,Lambda 函数将使用您的新模型。
测试您的新模型
既然我们已经部署了新模型,我们可以测试看看它的表现。在测试中,我们看到我们的模型能力得以改进,能够始终如一地识别测试对象。试一试,看看您的模型表现如何。
有关测量模型性能的更多信息,请参阅 Amazon SageMaker 图像分类示例笔记本。
回顾
在本文的第 1 部分和第 2 部分中,我们创建了一个 AWS IoT Greengrass 应用程序,该应用程序使用新的 AWS IoT Greengrass Image Classification 连接器来识别几类饮料包装容器。我们在第 2 部分中扩展了该应用程序,以允许我们收集字段中的数据并重新训练我们在第 1 部分中创建的模型。
我们期待看到您构建的内容! 请关注 AWS IoT Greengrass 接下来推出的内容。
接下来的新尝试
如果您想继续使用本文中的示例,下面提供了几个想法,您接下来可以尝试一下。有关如何重新训练和改进模型的信息,请参阅 Amazon SageMaker 图像分类文档。
您可能还想尝试:
使用 Amazon SageMaker Ground Truth。
向模型中添加新类别。
在 Amazon SageMaker 笔记本中试验训练参数,以提高模型的准确度。
更新 AmazonSageMaker 笔记本中的训练配置,以使用迭代训练。请参阅 Amazon SageMaker 开发人员指南中的图像分类算法。
添加缓冲机制以在 Core 设备离线时存储捕获到的图像,并在恢复与云的连接时上传到 S3。
相关文章:
https://aws.amazon.com/greengrass/
本文转载自 AWS 技术博客。
原文链接:


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论